今天介绍一篇图像语义分割的开山之作——FCN(全卷积网络)
论文题目:Fully Convolutional Networks for Semantic Segmentation
论文地址:https://arxiv.org/abs/1411.4038
这是一篇发表在2015 CVPR上的一篇论文,拿到了当年的best paper honorable mention
如果你会分类网络,那么分割网络你也就会很快明白了,因为分类网络是把一张图预测成一类,而分割网络是把一张图每个像素都预测一下,其实是一样的。这篇论文我们就捡最重要的介绍,论文前面写了很多内容都不太重要。
1.大致背景
CNN这几年一直在驱动着图像识别领域的进步。无论是整张图片的分类(ILSVRC),还是物体检测,关键点检测都在CNN的帮助下得到了非常大的发展。但是图像语义分割不同于以上任务,这是个空间密集型的预测任务,换言之,这需要预测一幅图像中所有像素点的类别。
以往的用于语义分割的CNN,每个像素点用包围其的对象或区域类别进行标注,但是这种方法不管是在速度上还是精度上都有很大的缺陷。
本文提出了全卷积网络(FCN)的概念,针对语义分割训练一个端到端,点对点的网络,达到了state-of-the-art。这是第一次训练端到端的FCN,用于像素级的预测;也是第一次用监督预训练的方法训练FCN。
2.本文核心看点

- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
- 上采样的反卷积(deconv)层。能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
3.FCN原理
(1)卷积化
分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵(图片)压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出则需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们丢弃全连接层,换上卷积层,而这就是所谓的卷积化了。
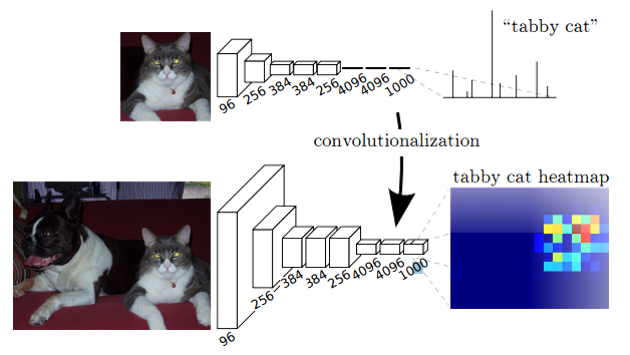
按照论文的图:
更直观的说明一下:
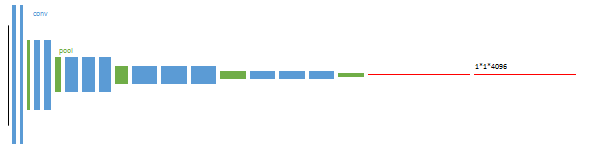
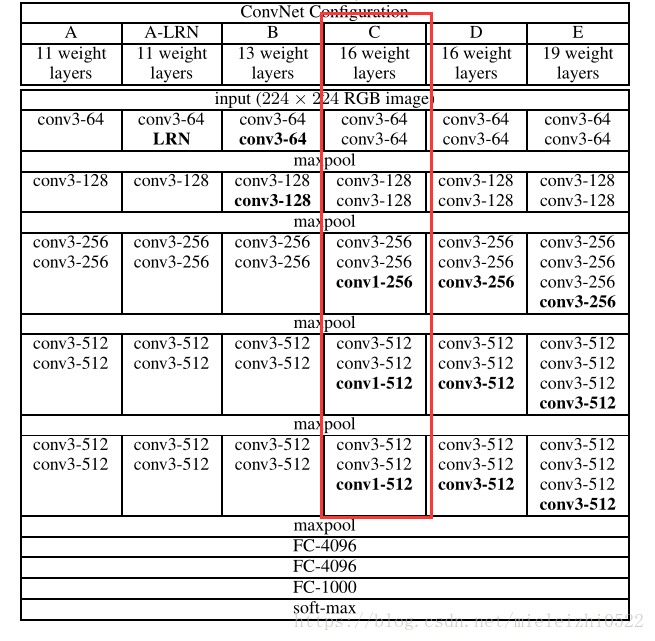
FCN前面的网络是在VGG网络基础上改进的,后面将红色的全连接层丢弃,我们都知道,分类网络中,全连接层是个一维输出,怎么输出一维呢,他是这样的,假如说在最后一个绿的池化层后面输出的是6*6*256,那么全连接层的第一个会把这个矩阵给拉直摊成一维向量9216,然后再用9216*[9216,4096]=1*1*4096大小的一维向量这就是全连接!
那么全卷积呢,全卷积就是在得到6*6*256后不进行拉直摊平处理,直接再用6*6**256的卷积核去卷积这幅特征图,如果输出通道是4096的话,得到就是1*1*4096的热图 ,注意这里的热图,虽然都是1*1*4096,但是意义是不一样的,上面那个是向量,这个是热图,为什么会是热图呢,因为如果输入尺寸发生变化,那么输出的就不是1*1*4096了,那个时候就真正的是一张图了。
也就是下面这种情况:
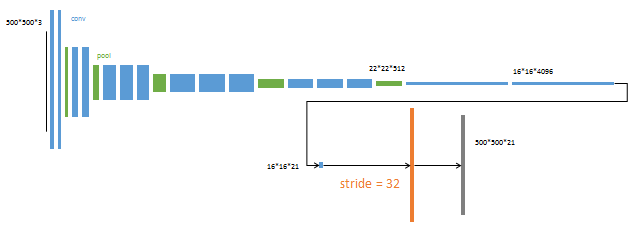
(2)反卷积
这个知识点一定要理解,说起来还是很多的,就是一种上采样的方法,其实应该叫做转置卷积,它和卷积是一样的,只是反卷积的输出图像大于输入图像,这个是通过补零来实现的具体原理可参考1 ,这里运用这个就是进行上采样。
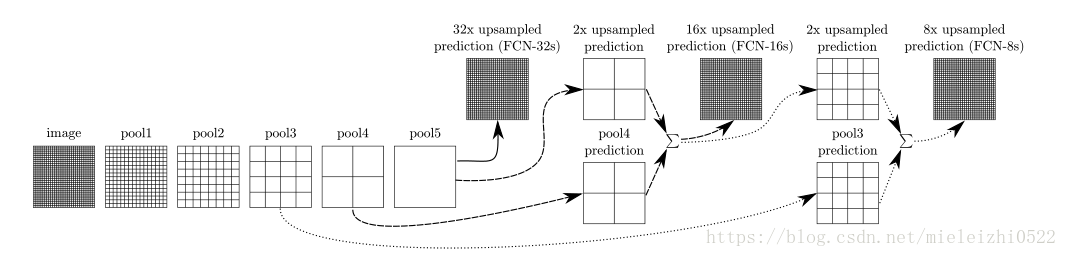
(3)跳跃结构(Skip Architecture)
直接将全卷积后的结果上采样后得到的结果通常是很粗糙的。所以这一结构主要是用来优化最终结果的,思路就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,具体结构如下:
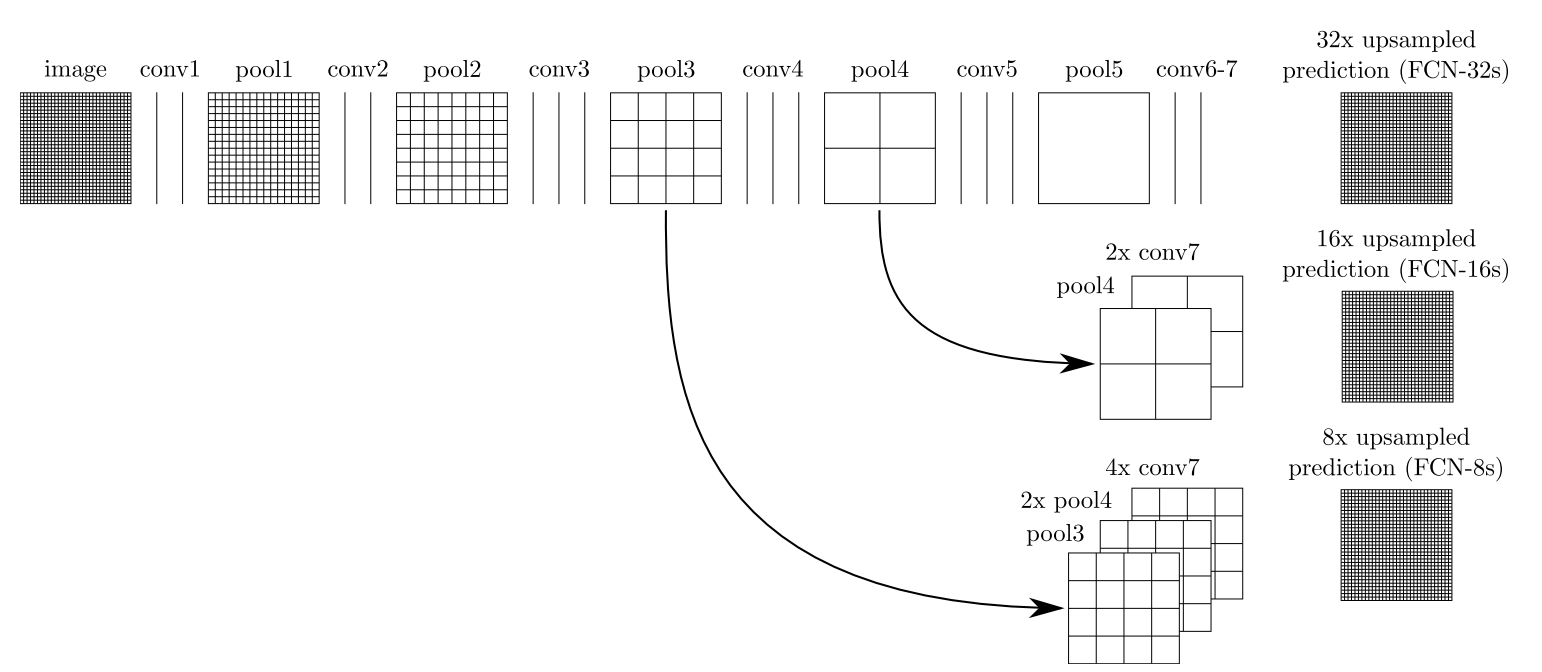
或者下面的这种表达方式 ,我估计那个灰色的是1*1的卷积,是为了在进行elementwise 的像素对像素的相加。
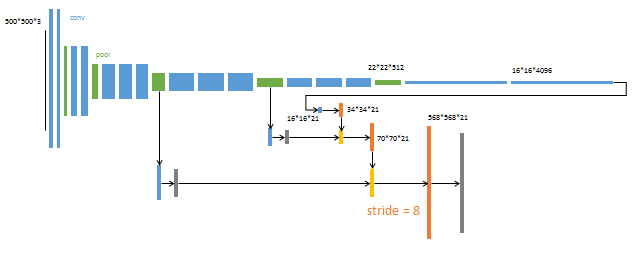
4.结果:


可见是相对优秀的。
5.评价指标
图像分割和分类不一样,评价指标有点复杂,什么是IU,什么是mAP 本轮文中有提到!

图像分割中通常使用许多标准来衡量算法的精度。这些标准通常是像素精度及IoU的变种,以下我们将会介绍常用的几种逐像素标记的精度标准。为了便于解释,假设如下:共有k+1个类(从L0到Lk,其中包含一个空类或背景),pij表示本属于类i但被预测为类j的像素数量。即,pii表示真正的数量,而pij pji则分别被解释为假正和假负,尽管两者都是假正与假负之和。
- Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
- Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
-
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。
- 在以上所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
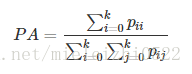

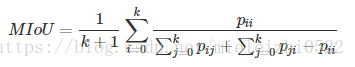
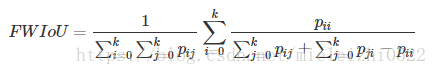
直观理解
如下图所示,红色圆代表真实值,黄色圆代表预测值。橙色部分红色圆与黄色圆的交集,即真正(预测为1,真实值为1)的部分,红色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个圆之外的白色区域表示真负(预测为0,真实值为0)的部分。
- MP计算橙色与(橙色与红色)的比例。
- MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(红色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1

源码地址:https://github.com/shelhamer/fcn.berkeleyvision.org
谢谢大家!我叫冯爽朗