FCN首先将深度学习引入到语义分割领域,网络的要点总结如下:
1. 将全连接层变为卷积,好处:
①传统的分类网络,比如LeNet、AlexNet等,只接受固定尺寸的输入并产生非空间输出,原因在于全连接层参数的限制,而且这些网络在通过全连接层把输入展开成向量的时候丢失了图片原有的空间信息。以VGG16和PASCAL数据集为例,网络去除了最后的分类层,并将所有的全连接层转化为上述的卷积层,然后添加了一层1x1x21的卷积层用于预测每个类别(包括背景)的得分,然后使用转置卷积进行双线性上采样,使得粗粒度输出(coarse outputs)变成像素密集的输出。
②论文给出了这两种方式的时间性能比较,在GPU上,
AlexNe
t需要花费1.2毫秒来产生对一张227x227的图片预测,而
FCN版本
花费了22毫秒对一张500x500的图片产生大小为
10x10
的预测,比AlexNet快了5倍多。
2. 使用跳层连接
随着卷积神经网络层数的增加,每一层的感知野(reception field)也更广。但网络中低的层感知野小,能得到更多细节。
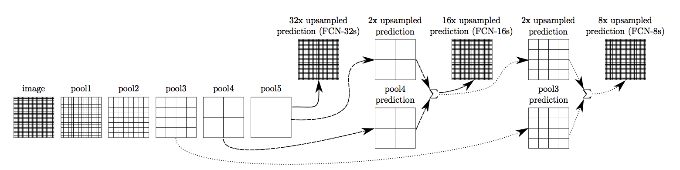
图中所示为改造后的VGG16的简化图,图中只包含了输入层、由全连接层转化而来的卷积层以及Pooling层。
对我们最初采用stride为32的上采样得到结果的模型我们称为FCN-32s
,为了进一步优化输出预测。
我们首先在pool4后面添加1x1的卷积层来产生额外的预测。然后对使用步长为32的conv7(卷积化后的fc7)进行2x上采样,因为pool5将尺寸缩减了一半,此时进行2x上采样将会把尺寸恢复到跟pool4一样,然后把该结果和pool4后1x1卷积层产生的结果进行求和(不采用Max fusion的原因是会因为梯度选择而使得训练较为困难)。对于pool4后的1x1卷积层采用双线性插值初始化,但是允许参数在训练过程中进行调整。最后,
结果采用stride为16的方式进行上采样得到,该模型我们成为FCN-16s
。
同理,我们可以通过在
pool3后添加1x1的卷积层并进行上述类似操作得到FCN-8s
,但是得到的提升已经十分有限,因此不再进行更低层的fusion操作。
3. 上采样
图像输入经过网络之后,尺寸为
[H/32, W/32]
,而算法的目标是对每一个像素进行预测,需要进行upsampling操作,恢复原始尺寸。在某种程度上,使用系数为
f
的upsampling可以看成是步长为
1/f
的卷积的转置,
f
是整数,一种进行upsampling的方法就是使用
backwards convolution
(或称
deconvolution
,该术语存在争议,也有人称
transposed convolution
),以输出步长为
f
进行计算。
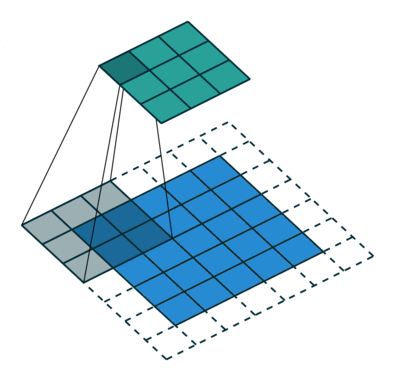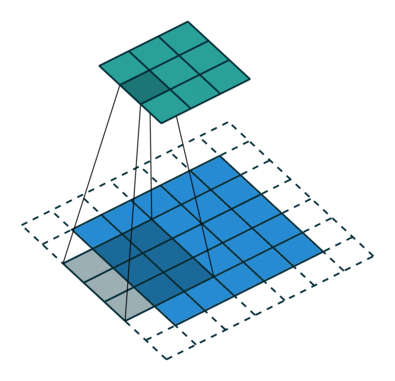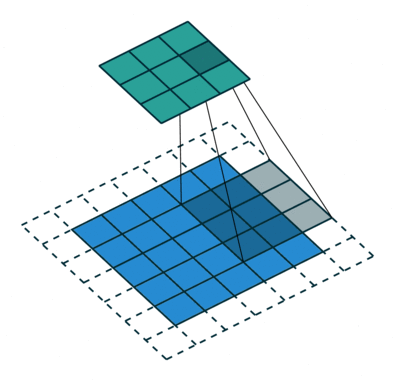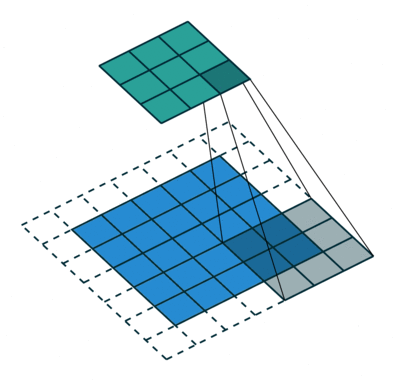
如图所示,绿色部分为输入,蓝色部分为输出,stride为2,padding为1。可以看出,
transposed convolution
其实就是
convolution
反过来,调换了
convolution
的前向传播和反向传播过程而已。