来源:
因为工作中从事机器人导航相关工作,需要了解粒子滤波相关知识,现在从csdn博主(白巧克力亦唯心)的几篇博文研究一番,写一写自己的学习笔记与思路,所有思路从该博主来,贴出该博主的网址http://blog.csdn.net/heyijia0327/article/details/40899819
前言:
意思是将结合实际例程给出粒子滤波的详细推导,解释一些别人博客并不注意的关键地点。
文章框架: 从 贝叶斯估计---蒙特卡洛采样----重要性采样---SIS粒子滤波---重采样---基本粒子滤波Generic Partical Filter---SIR粒子滤波
...........................(从这个顺序介绍似乎更清楚?先看看)
一、贝叶斯滤波
假设了一个系统,知道状态方程
如:
(1)
如:
(2)
.................................//排版不好意思,公式乱乱的
意义介绍:其中x为系统状态,y为测量到的数据,f,h是状态转移函数和测量函数,v,n为过程噪声和测量噪声,噪声都是独立同分布的。
贝叶斯理论:状态估计问题 就是根据之前的一系列已经有的数据(后验知识,搜索哲学概念:先验知识与后验知识)递推计算当前状态
的可信度,可信度计算概率公式:
,这通过预测与更新递推计算。
预测过程:利用状态方程1预测状态的先验概率密度,即通过已有的先验知识进行猜测,获得p( x(k)|x(k-1) )
更新过程:利用最新的测量值对先验概率密度进行修正,得到后验概率密度,也就是对猜测进行修正。
处理问题时使用的假设:1.当前时刻状态x(k)时刻只与上一个时刻的状态x(k-1)有关(服从一阶马尔科夫模型。。。)
2.假设K时刻测量到的数据y(k)只与当前状态x(k)有关。
(思考:根据观察到的k时刻之前一系列数据给出一个k时刻预测值,然后观测一下k时刻的值,预测值和观测值根据可靠性进行修正,这怎么跟卡尔曼滤波很类似啊?????????)
开始递推:已知条件,k-1时刻的概率密度函数
预测:由上一时刻的概率密度得到
,即由k-1时刻的测量数据,预测下一状态x(k)出现的概率。
给出推导公式:
等式第一行到第二行时贝叶斯公式的应用,第二行到第三行是假设一,状态x(k)只由x(k-1)决定。
因为假设的x(k)由x(k-1)决定,所以成立。
是根据已有的经验猜测x(k)。
最后一行是已知的,
由系统状态方程决定,x(k)由一个通过x(k-1)计算出的常数叠加一个噪声得到。
没有噪声的话,x(k)将完全由计算得到,就没有概率分布的概念了。
更新:由得到后验概率
,这个后验概率才是有用的东西。先验概率只是预测值,现在添加了k时刻的测量值,对预测值进行了修正,这就是滤波了。修正后的后后验概率可以带入下一次的预测,就是递推了。
公式:
其中归一化常数:
等式第一行到第二行是因为测量方程知道, y(k)只与x(k)有关,也称之为似然函数,由量测方程决定。也和上面的推理一样,
, x(k)部分是常数,
也是只和量测噪声n(k)的概率分布有关,注意这个也将为SIR粒子滤波里权重的采样提供编程依据。
遗留问题:上面的推导过程中使用到积分,对于一般的非线性,非高斯系统,很难得到后验概率的解析解,为了解决这个问题,引入了蒙特卡洛采样,下面进行介绍蒙特卡洛
(概率论学的差不多快忘记了,里面有一些概念遗忘了,一些小地方不太理解。。。大致意思看了一遍有些不理解的地方大家可以去博主原文查看,稍后细看,下面介绍蒙特卡洛相关的。。。)
--------------------------------------------------------------我是一条分界线-------------------------------------------------------------------------
一、蒙特卡洛采样
一个概率分布p(x),从中采样一系列样本(粒子?称呼不同而已:x1,x2....xn),想要获得概率分布的期望,可以通过计算样本的期望来估计,这两者应该是近似的:
计算期望的公式:
上面两个式子都是计算期望的(第一个我了解,第二个不清楚,先放一放售后研究)
蒙特卡洛采样 即使用平均值来代替积分求期望:
(这样合适吗?平均?原文似乎是说按照比例抽样计算平均。。。)
.............中间一个公式推导例子,省略掉..........
也就是说,我们采用蒙特卡洛的方式,通过抽样,来估计后验概率。
后验概率计算公式:
得到后验概率后,就是用来做图像跟踪或者滤波,现在得知道当前状态的期望值:
就是采样粒子的状态值直接进行平均求得,就是粒子滤波,从后验概率中采样很多粒子,用他们状态求平均就得到粒子滤波结果。
问题:后验概率不知道,不能从后验概率分布中采样,得引入重要性采样
--------------------------------------------------------------我是一条分界线-------------------------------------------------------------------------
三、重要性采样
无法从目标分布中采样,就从一个已知的可以采样的分布里去采样(???):
公式推导......................(可以在原博文中去看)
总之,通过蒙特卡洛的方式计算期望,,,,
最后,不再是粒子状态直接相加求平均了,而是采用加权和的形式,不同的粒子由相应的权重,权重大的粒子可信程度比较高。现在解决了不能从后验概率直接采样的问题,但是每种粒子的权重直接计算的方法,效率低下,改用以递推的方式计算权重,即所谓的序惯重要性采样(SIS),粒子滤波的原型。
权重W递推形式推导:
......................略
权重有了后进行稍微总结,就可以得到SIS Filter
四、Sequential Importance Sampling(SIS) Filter
实际的使用中,假设重要性分布满足:
假设说明了,重要性分布只与前一刻的状态x(k-1)以及测量y(k)有关
序惯重要性采样滤波伪代码:
----------------------pseudo code-----------------------------------
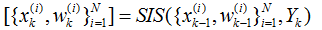
For i=1:N
(1)采样:;
(2)根据递推计算各个粒子的权重;
End For
粒子权值归一化。粒子有了,粒子的权重有了,就可以由(4)式,对每个粒子的状态进行加权去估计目标的状态了。
-----------------------end -----------------------------------------------
这个算法就是粒子滤波的前身了。只是在实际应用中,又发现了很多问题,如粒子权重退化的问题,因此就有了重采样( resample ),就有了基本的粒子滤波算法。还有就是重要性概率密度q()的选择问题,等等。都留到下一章 去解决。
五、重采样
SIS滤波存在的问题:
1.退化现象
描述:迭代几次后,大多数粒子权重变得极小,可以忽略,仅少数粒子权重很大,粒子方差随时间增大,状态空间有效粒子较小,随着无效粒子采样数目增加,浪费大量计算资源在对后验滤波概率计算几乎不起作用的粒子上,使得估计估算性能大大下降。
如何描述退化程度,通过有效粒子数目来衡量。一般来说,有效粒子数越小,权重方差越大,也就说权重大的和权重小的之间差距越大,权值退化越是严重,相关的衡量公式这里暂时不写:::
解决办法,预先设定一个阈值,达到后采取措施控制。采取的措施一般两种,第一种是选择合适的重要性概率密度函数,第二种是徐惯重要性采样之后,采用重采样方法。
原文对于第一种方法没有介绍,大家自己去百度谷歌去,或者看看《粒子滤波理论》
第二种:重采样。
即将权重大的粒子复制,保持粒子数目不变。复制的数目根据粒子权重衡量,权重越大,复制得越多。
将重采样的方法放入之前的SIS算法中,就是基本粒子滤波算法:

使用重采样的方法也不一定可靠,因为靠权重大的多复制这个思路来说,粒子权重大 可能是分母小,分子也可能小,实际的后验概率可能小。粒子滤波中也有专门的方法:正则粒子滤波。
至此,整个过程基本完了。其实自己还没看清楚,后续随着理解增加会修改的。
六、Sampling Importance Resampling Filter(SIR)
SIR滤波器很容易有前面的基本粒子滤波推导出来,只要退粒子的重要性概率密度函数做出特定的选择即可。
....若干公式(看不进去了,留个位置稍后填写)
.....
伪代码的SIR滤波器:
----------------------SIR Particle Filter pseudo code-----------------------------------
- FOR i = 1:N
(1)采样粒子:
(2)计算粒子的权重:
- END FOR
- 计算粒子权重和,t=sum(w)
- 对每个粒子,用上面的权重和进行归一化,w = w/t
- 粒子有了,每个粒子权重有了,进行状态估计
- 重采样
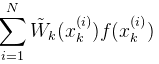
在上面算法中,每进行一次,都必须重采样一次,这是由于权重的计算方式决定的。
分析上面算法中的采样,发现它并没有加入测量y(k)。只是凭先验知识p( x(k)|x(k-1) )进行的采样,而不是用的修正了的后验概率。所以这种算法存在效率不高和对奇异点(outliers)敏感的问题。但不管怎样,SIR确实简单易用。
七、粒子滤波的应用
这一段实践我就不放了,想看的可以去 博主 白巧克力亦唯心那里去看
虽然巧克力博主写的很好,但自己水平有限,特别是公式一多起来时理解速度就会变慢,不过现在正在看,争取之后在文后添加更多关于粒子滤波的个人理解。