粒子滤波器
一、粒子滤波器原理
粒子滤波器是一个很好的解决非线性和非高斯系统中问题的工具。
粒子滤波(PF: Particle Filter)的思想基于蒙特卡洛方法(Monte Carlo methods),它是利用粒子集来表示概率,可以用在任何形式的状态空间模型上。其核心思想是通过从后验概率中抽取的随机状态粒子来表达其分布,是一种顺序重要性采样法(Sequential Importance Sampling)。简单来说,粒子滤波法是指通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。这里的样本即指粒子,当样本数量N→∝时可以逼近任何形式的概率密度分布。

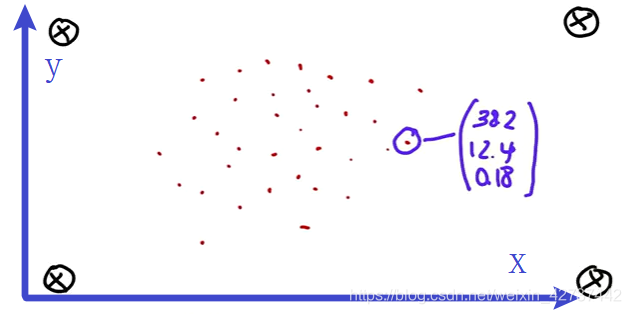
粒子滤波器的原理很简单,如上图所示,可以用来辅助机器人或者是自动驾驶汽车进行定位。
在开始的时候,我们的机器人不知道自己在那,所以可能是在任意一个位置,那么开始的时候所有的红点就代表可能的位置,所以说这个点包含的信息有位置信息x,y,以及机器人的行驶方向角度。这些点是随机生成的。而蓝色的线,代表了机器人使用传感器获取到的,自己与地图上标志物的距离,所以机器人必须使用这些距离来判断或者说预测自己所处的位置。
二、粒子滤波器流程
2.1 生成随机点
首先,我们要生成一定数量的随机粒子,每个粒子是一个三维的
2.2 随机点运动
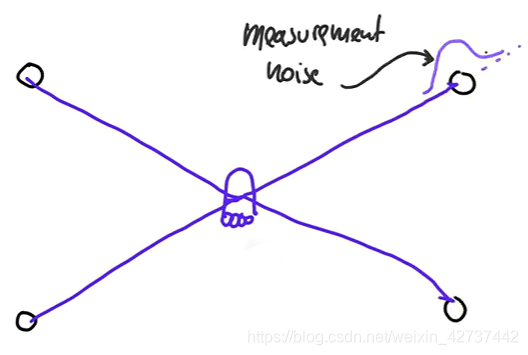
接着,我们要让我们的机器人进行运动,因为我们是自己控制机器人的,我们知道机器人移动的角度和距离。紧接着,让所有的随机点按照机器人移动的距离和角度做相同的动作。

接着就要进行测量,假设我们的机器人是处于某一个位置,那么它使用传感器可以测量到自己距离每一个标志物(可能是地标或者障碍物,其位置已知)的距离,但是因为传感器有一定的测量噪声,所以每一个距离都不是准确的,都得叠加一个高斯噪声。
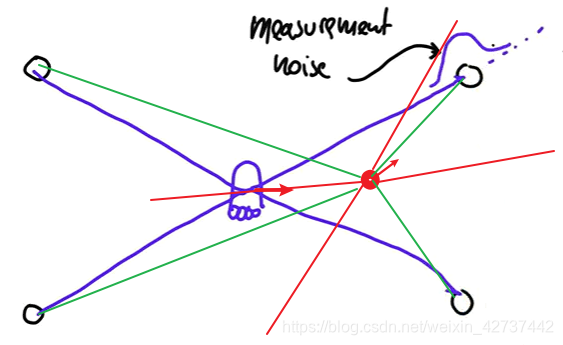
我们假设图中的红点是一个随机的点,那么按照红点的位置与方向,实际上将传感器的数据放到红点上的话,计算出来的四个参考点的位置就与实际的位置有较大的偏差,其真实的与参考点的位置应该是绿色线标识出来的。
2.3 权重
所以这里我们就引入一个权重的概念,随机点与实际位置越接近,那么其权重就越到,也就说明这个点越有可能是真实的机器人的位置。
2.4 重采样
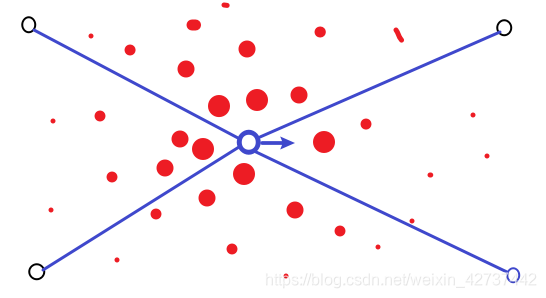
然后我们需要根据权重对所有的点进行重采样,也就是说,权重越到的点越有可能被保留,而权重越小的点越有可能被淘汰。但是点的总数与之前的一样。这也就意味着有一些点可能会被重采样采集多次。
2.5 重采样轮
要实现重采样,其实这个过程还不是特别简单,所以我们引入了一个工具,重采样轮。将所有的点按照权重大小分布在一个圆形里边。
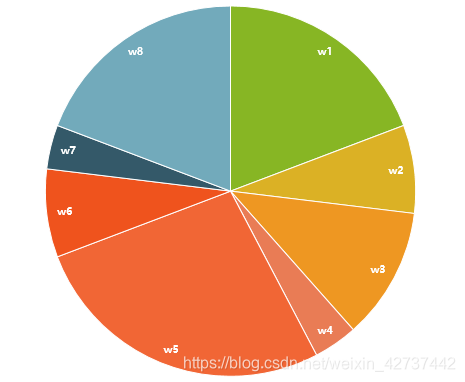
第一步,我们要随机的选取一个索引,表示从一个随机的位置开始。
第二步,我们需要选取一个步进值,这个步进值初始为0 ,但是需要在其上加一个0到2倍的最大权重之间的随机数,之后我们就得出了步进值。
第三步,我们观察当前索引加上步进值后落到了哪个区域,将索引设置为哪个区域,同时这个区域就是我们选取到的点。
第四步:重新选取步进值,然后重复上述操作。
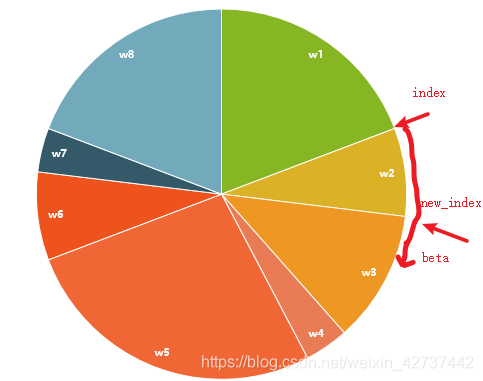
P_new = []
index = int(random.random() * N)
beta = 0.0
mw = max(W)
for i in range(N):
beta += random.random() * 2.0 * mw
while beta > W[index]:
beta =+ W[index]
index = (index +1) % N
P_new.append(P[index])
PS在这里看似没有用到角度,但是角度是很有用的,因为不同的角度经过动作后,如果运动方向与真实机器人不符,那么误差就会变大,权重就会变小,从而很快就会在重采样中被淘汰。
三、自动驾驶中的粒子滤波器
3.1 系统流程
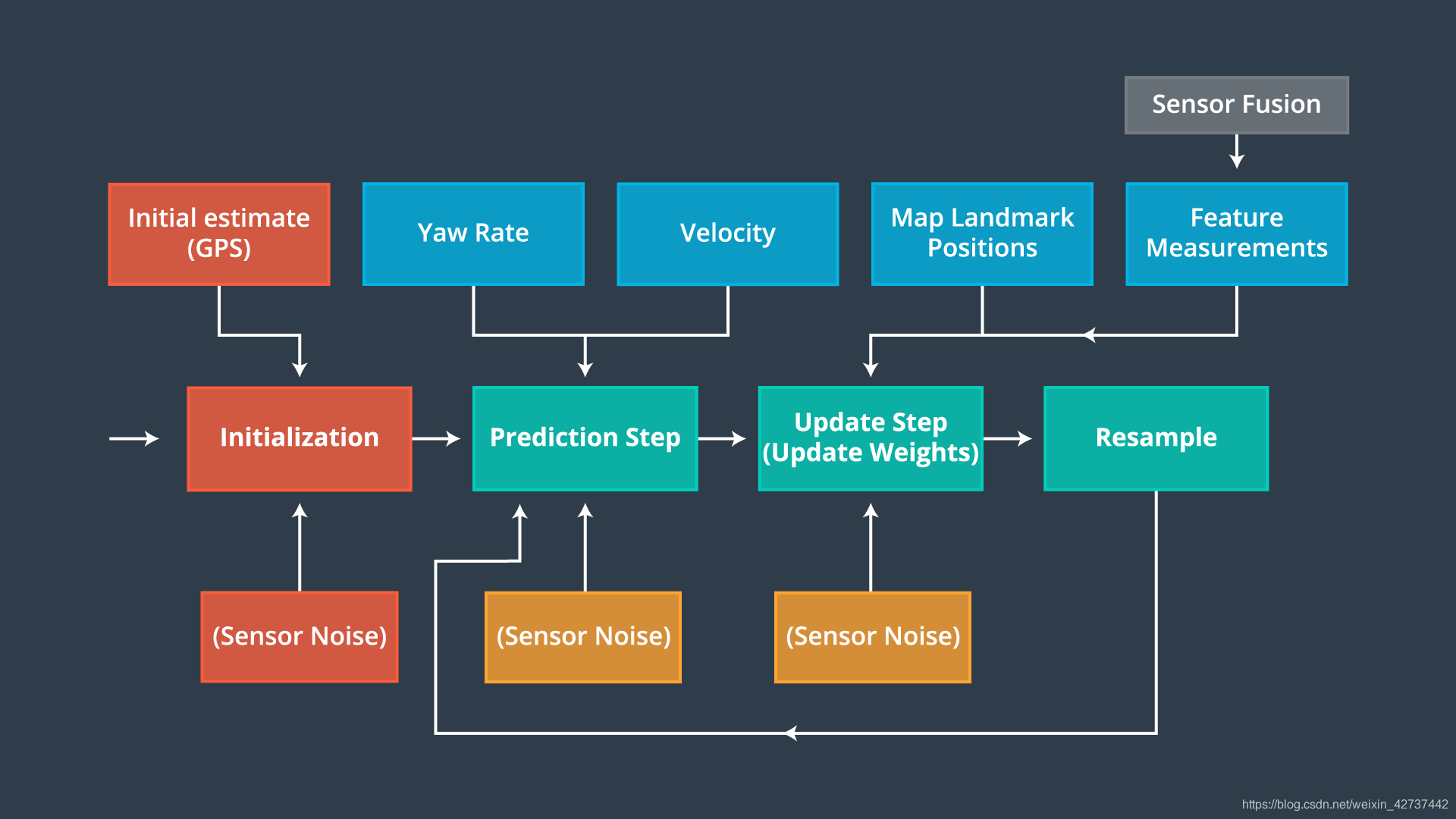
一般子啊自动驾驶中,我们使用粒子滤波器进行定位,即确定自己在那,一般配合GPS数据进行精确定位。首先用GPS数据确定大概的位置,然后使用粒子滤波器进行精确的定位。
3.2 初始化
在初始化的过程中,我们要确定随机生成多少个粒子,太多或者太少都是不合适的,太少了覆盖不了所有可能的位置,太多了会增加计算量。
有两种初始化的方法,一种是在整个空间中均匀的采样。例如将空间网格化,每一个网格安排一个或者多个粒子。

但是这种方法比较困难,尤其是我们认为汽车可能会去任何地方,那么就需要一个足够大的网格区域,有可能是整个地球,那么显然是不现实的。
所以就有了第二种方案,利用GPS的数据,对汽车先进行一个初步的定位,然后在确定的初步位置的周围生成粒子。
void ParticleFilter::init(double x, double y, double theta, double std[])
{
/**
* Set the number of particles. Initialize all particles to
* first position (based on estimates of x, y, theta and their uncertainties
* from GPS) and all weights to 1.
* Add random Gaussian noise to each particle.
*/
num_particles = 100; // Set the number of particles
//gaussion
static default_random_engine e;
normal_distribution<double> gx(0, std[0]);
normal_distribution<double> gy(0, std[1]);
normal_distribution<double> gt(0, std[2]);
for (int i = 0; i < num_particles; i++)
{
Particle p;
p.id = i;
p.x = x;
p.y = y;
p.theta = theta;
p.weight = 1.0;
//add noise
p.x += gx(e);
p.y += gy(e);
p.theta += gt(e);
particles.push_back(p);
}
is_initialized = true;
}
3.3 预测
在预测阶段,我们需要基于汽车的已知运动模型(主要是运动方式)来对所有的粒子进行相同的动态更新,就是让所有的粒子执行跟汽车相同的动作。主要是基于运动速度和运动角度。
其中会用到的更新公式为:
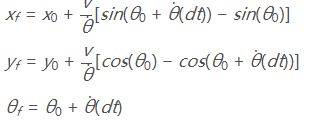
void ParticleFilter::prediction(double delta_t, double std_pos[],
double velocity, double yaw_rate)
{
/**
* Add measurements to each particle and add random Gaussian noise.
* When adding noise you may find std::normal_distribution
* and std::default_random_engine useful.
* http://en.cppreference.com/w/cpp/numeric/random/normal_distribution
* http://www.cplusplus.com/reference/random/default_random_engine/
*/
//gaussion
static default_random_engine e;
normal_distribution<double> gx(0, std_pos[0]);
normal_distribution<double> gy(0, std_pos[1]);
normal_distribution<double> gt(0, std_pos[2]);
for (int i = 0; i < num_particles; i++)
{
Particle p = particles[i];
if (fabs(yaw_rate) < 0.0001)
{
p.x = p.x + velocity * delta_t * cos(p.theta);
p.y = p.y + velocity * delta_t * sin(p.theta);
}
else
{
p.x = p.x + velocity / yaw_rate * (sin(p.theta + yaw_rate * delta_t) - sin(p.theta));
p.y = p.y + velocity / yaw_rate * (cos(p.theta) - cos(p.theta + yaw_rate * delta_t));
}
p.theta = p.theta + delta_t * yaw_rate;
//add noise
p.x += gx(e);
p.y += gy(e);
p.theta += gt(e);
particles[i] = p;
}
}
3.3 数据关联
在进行预测之前,我们先需要对数据进行处理,即数据关联。
我们可以想到,我们的传感器测量到的数据往往会有很多,有时候同一个地标就会采集到很多不同的数据,就像下图:
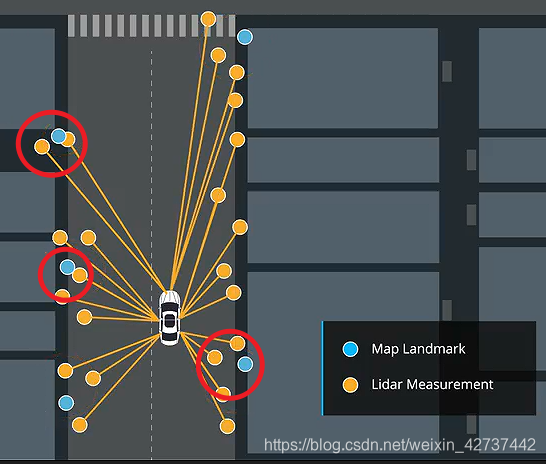
那么我们该选择拿一个点作为可以使用的真实点呢?这里有一种方法是将测量到的离参考点最近的点作为可以使用的测量值。
但是这种方法有一些缺陷,
首先,当有很多参考点的时候,每一个参考点我们都必须计算一下它跟多有才几点的距离,假设有m个路边,然后传感器测量到了n个点,那么时间复杂度就是O(mn),这个在点多的时候就会拖慢计算速度。

其次,会因为测量的噪声过大而发生一些错误的匹配,例如下图:
当噪声过大的时候,本来应该匹配B点,但是实际上却是选择了A点
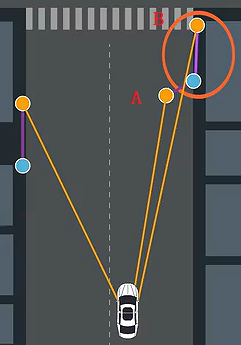
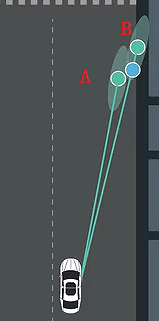
最后,这种算法没有考虑到传感器的噪声,有的传感器的噪声是有方向的,因此早这个方向上就算是更大的偏差也比较符合实际情况。如下图,明显是B点更符合实际的测量,但是因为最近原则,我们反而采用了A点。
void ParticleFilter::dataAssociation(vector<LandmarkObs> predicted,
vector<LandmarkObs> &observations)
{
/**
* Find the predicted measurement that is closest to each
* observed measurement and assign the observed measurement to this
* particular landmark.
*/
// 每一个地图上的参考点坐标,都从测量点中找到与之最接近的一个,将两个对齐, 使用ID对其
for (unsigned int i = 0; i < observations.size(); i++)
{
//将距离最大化
double min_len = std::numeric_limits<double>::max();
int id = -1;
// 找到最接近的点的id
for (int j = 0; j < particles.size(); j++)
{
double len = dist(predicted[j].x, predicted[j].y, observations[i].x, observations[i].y);
// std::cout << "len:" << len << std::endl;
if (len < min_len)
{
min_len = len;
id = predicted[j].id;
}
}
observations[i].id = id;
}
}
3.4 坐标转化
因为我们目前使用的是两套坐标系,对于地标,我们使用的是绝对坐标系,是地图上的坐标系,而传感器测到的是以汽车为原点的坐标,两种点不在同一个坐标系中,所以需要转化。
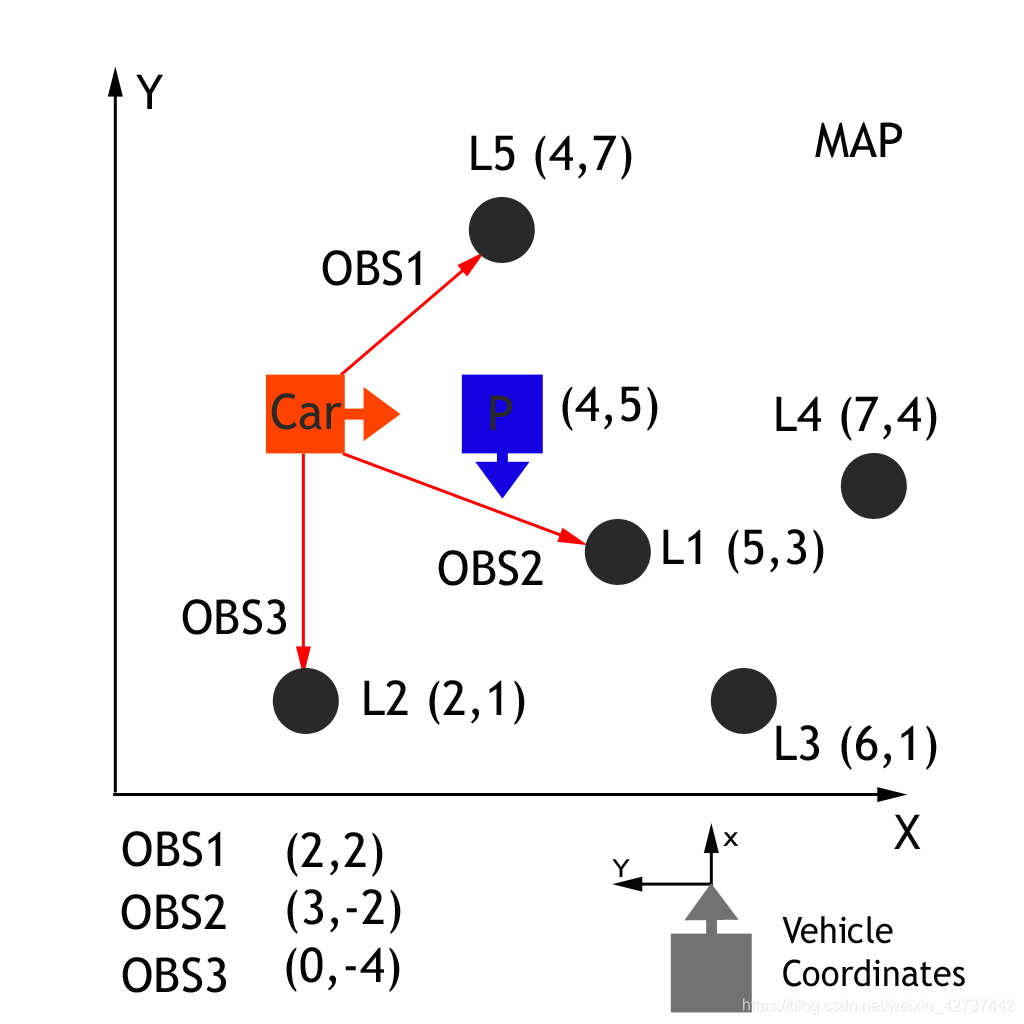
具体的装换方法可以参考这里:
因此变换的公式为
换成公式就是:
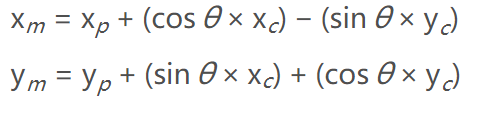
vector<LandmarkObs> observations_map;
for (unsigned int j = 0; j < observations.size(); j++)
{
double x_map = p.x + cos(p.theta) * observations[j].x - sin(p.theta) * observations[j].y;
double y_map = p.y + sin(p.theta) * observations[j].x + cos(p.theta) * observations[j].y;
observations_map.push_back(LandmarkObs{observations[j].id, x_map, y_map});
}
3.5 更新权重
接下来就需要对于每个粒子的权重进行更新。这里我们采用多元高斯概率密度函数。函数如下:
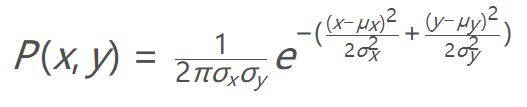
其中:
x和y以及ux和uy分别是观测坐标以及预测坐标。
σx和σy为传感器噪声。
//计算weight
for (int j = 0; j < observations_map.size(); j++)
{
/*
这种方法是使用ID对齐,所以需要进行找ID的行为,需要每次进行一次循环,对应的数据处理是使用ID对齐
*/
LandmarkObs obs = observations_map[j];
LandmarkObs pred;
for (unsigned k = 0; k < predictions.size(); k++)
{
if (predictions[k].id == obs.id)
{
pred = predictions[k];
}
}
/*
这种方法是使用索引对齐,不需要进行循环,暂时行不通
*/
// LandmarkObs pred = predictions[j];
// LandmarkObs obs = observations_map[j];
double pxy = (0.5 / (M_PI * sig_x * sig_y)) * exp(-(pow(pred.x - obs.x, 2) / (2 * pow(sig_x, 2)) + pow(pred.y - obs.y, 2) / (2 * pow(sig_y, 2))));
// std::cout << "pxy=" << pxy << std::endl;
particles[i].weight *= pxy;
}
3.6 重采样
更新完权重之后,就按照权重进行重采样。
void ParticleFilter::resample()
{
/**
* Resample particles with replacement with probability proportional to their weight.
* http://en.cppreference.com/w/cpp/numeric/random/discrete_distribution
*/
//获取所有粒子的权重,放入向量
vector<double> weights;
for (int i = 0; i < num_particles; i++)
{
weights.push_back(particles[i].weight);
}
//根据权重向量生成随机的索引
default_random_engine e;
std::discrete_distribution<int> index(weights.begin(), weights.end());
//重采样粒子
vector<Particle> new_particles;
for (int i = 0; i < num_particles; i++)
{
new_particles.push_back(particles[index(e)]);
}
particles = new_particles;
}
3.7 误差计算RMSE
接着可以计算一下均方根误差:
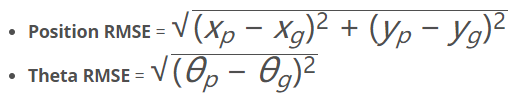
四、完整代码
完整代码可以参考我的github
