粒子滤波PF—从贝叶斯滤波到粒子滤波PF—Part-IV(粒子退化和重采样)
原创不易,路过的各位大佬请点个赞
机动目标跟踪/非线性滤波/传感器融合/导航等探讨代码联系WX: ZB823618313
粒子滤波PF—从贝叶斯滤波到粒子滤波PF—Part-IV(粒子退化和重采样)
在非线性条件下,贝叶斯滤波面临一个重要问题是状态分布的表达和积分式的求解,由前面章节中的分析可知,对于一般的非线性/非高斯系统,解析求解的途径是行不通的。在数值近似方法中,蒙特卡罗仿真是一种最为通用、有效的手段,粒子滤波就是建立在蒙特卡罗仿真基础之上的,它通过利用一组带权值的系统状态采样来近似状态的统计分布。由于蒙特卡罗仿真方法具有广泛的适用性,由此得到的粒子滤波算法也能适用于一般的非线性/非高斯系统。但是,这种滤波方法也面临几个重要问题,如有效采样(粒子)如何产生、粒子如何传递以及系统状态的序贯估计如何得到等。
简单的理解,粒子滤波就是使用了大量的随机样本,采用蒙特卡洛(MonteCarlo,MC)仿真技术完成贝叶斯递推滤波(Recursive Bayesian Filter)过程。因此本博客从贝叶斯滤波出发,简单介绍粒子滤波PF的出生、即应用
核心思想:是使用一组具有相应权值的随机样本(粒子)来表示状态的后验分布。该方法的基本思路是选取一个重要性概率密度并从中进行随机抽样,得到一些带有相应权值的随机样本后,在状态观测的基础上调节权值的大小。和粒子的位置,再使用这些样本来逼近状态后验分布,最后将这组样本的加权求和作为状态的估计值。粒子滤波不受系统模型的线性和高斯假设约束,采用样本形式而不是函数形式对状态概率密度进行描述,使其不需要对状态变量的概率分布进行过多的约束,因而在非线性非高斯动态系统中广泛应用。尽管如此,粒子滤波目前仍存在计算量过大、粒子退化等关键问题亟待突破。
1、贝叶斯滤波
**贝叶斯滤波细节 见Part-I**
考虑离散时间非线性系统动态模型,
x k = f ( x k − 1 , w k − 1 ) z k = h ( x k , v k ) (1) x_k=f(x_{k-1},w_{k-1}) \\ z_k=h(x_k,v_k ) \tag{1} xk=f(xk−1,wk−1)zk=h(xk,vk)(1)
其中 x k x_k xk为 k k k时刻的目标状态向量, z k z_k zk为 k k k时刻量测向量(传感器数据)。这里不考虑控制器 u k u_k uk。 w k {w_k} wk和 v k {v_k} vk分别是过程噪声序列和量测噪声序列。 w k w_k wk和 v k v_k vk为零均值高斯白噪声。
定义 1 1 1 ~ k k k时刻对状态 x k x_k xk的所有测量数据为
z k = [ z 1 T , z 2 T , ⋯ , z k T ] T z^k=[z_1^T,z_2^T,\cdots,z_k^T]^T zk=[z1T,z2T,⋯,zkT]T
根据Part-I, k k k时刻状态 x k x_k xk的后验概率密度函数:
p ( x k ∣ z k ) = p ( z k ∣ x k ) p ( x k ∣ z k − 1 ) p ( z k ∣ z k − 1 ) p(x_k |z^{k})=\frac{p(z_k |x_k)p(x_k |z^{k-1})}{p(z_k |z^{k-1})} p(xk∣zk)=p(zk∣zk−1)p(zk∣xk)p(xk∣zk−1)

通过后验分布 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)可以得到 x k x_k xk的最小均方误差(MMSE)估计为
x ^ k = E [ x k ∣ z k ] = ∫ x k p ( x k ∣ z k ) d x k (2) \hat{x}_k=E[x_k|z_k]=\int x_kp(x_k |z^{k}) dx_k \tag{2} x^k=E[xk∣zk]=∫xkp(xk∣zk)dxk(2)
2、 蒙特卡洛方法MC
**蒙特卡洛近似方法细节 见Part-I**
根据Part-II蒙特卡洛方法, x k ( i ) , i = 1 , 2 , ⋯ , N x_k^{(i)}, i=1,2,\cdots,N xk(i),i=1,2,⋯,N表示从后验概率分布函数 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)采样得到的 N N N个独立同分布的样本,则状态的后验概率密度可以通过如下经验公式近似得到:
p ( x k ∣ z k ) = 1 N ∑ i = 1 N δ ( x k − x k ( i ) ) p(x_k |z^{k})=\frac{1}{N}\sum_{i=1}^N\delta(x_k-x_k^{(i)}) p(xk∣zk)=N1i=1∑Nδ(xk−xk(i))
同时后验条件期望可近似表示为
x ^ k = E [ x k ∣ z k ] ≈ E ^ [ x k ∣ z k ] ≈ 1 N ∑ i = 1 N x k ( i ) , E [ g ( x k ) ∣ z k ] ≈ E ^ [ g ( x k ) ∣ z k ] ≈ 1 N ∑ i = 1 N g ( x k ( i ) ) (3) \hat{x}_k=E[x_k|z^{k}]\approx\hat{E}[x_k|z^{k}]\approx\frac{1}{N}\sum_{i=1}^Nx_k^{(i)}, \tag{3}\\ E[g(x_k)|z^{k}]\approx\hat{E}[g(x_k)|z^{k}]\approx\frac{1}{N}\sum_{i=1}^Ng(x_k^{(i)}) x^k=E[xk∣zk]≈E^[xk∣zk]≈N1i=1∑Nxk(i),E[g(xk)∣zk]≈E^[g(xk)∣zk]≈N1i=1∑Ng(xk(i))(3)
蒙特卡洛方法是实现的贝叶斯滤波,得到粒子滤波的桥梁。
3、 序贯重要性采样SIS
重要性采样不能直接用来进行递推估计,主要因为估计 p ( x 0 : k ∣ z 1 : k ) p(x_{0:k} |z_{1:k}) p(x0:k∣z1:k)的过程需要用到所有的量测信息 k k k,然而每次在 k + 1 k+1 k+1时刻更新量测信息 z k + 1 z_{k+1} zk+1时,则需要重新计算整个状态序列的重要性权值,所以其计算量将随时间的推移而大量增加。为了解决这一问题, 序贯重要性采样( Sequential Importance Sampling,SIS) 方法得以提出。
序贯重要性采样算法根据每一步接收到新的量测信息,逐次进行采样粒子和重要性权值的递推,算法步骤如下:
算法:序贯重要性采样SIS
For i = 1 : N i=1:N i=1:N
Step 3: 采样粒子 x k ( i ) ∼ q ( x k ∣ x k − 1 , z 1 : k ) x_k^{(i)} \sim q(x_{k} |x_{k-1},z_{1:k}) xk(i)∼q(xk∣xk−1,z1:k)
Step 4: 根据 w ~ k ( i ) = w ~ k − 1 ( i ) p ( x k ( i ) ∣ x k − 1 ( i ) ) p ( z k ∣ x k ( i ) ) q ( x k ( i ) ∣ x k − 1 ( i ) , z k ) \tilde{w}_k^{(i)}=\tilde{w}_{k-1}^{(i)}\frac{p(x_k^{(i)} |x_{k-1}^{(i)})p(z_{k}|x_k^{(i)})}{q(x_k^{(i)} |x_{k-1}^{(i)}, z_{k})} w~k(i)=w~k−1(i)q(xk(i)∣xk−1(i),zk)p(xk(i)∣xk−1(i))p(zk∣xk(i))
计算立在的权值 w ~ k ( i ) \tilde{w}_k^{(i)} w~k(i)
End For
Step 5: 粒子重要性权重归一化
w ~ k ( i ) = w k ( i ) ∑ j = 1 N w k ( j ) \tilde{w}_k^{(i)}=\frac{w_k^{(i)}}{\sum_{j=1}^Nw_k^{(j)}} w~k(i)=∑j=1Nwk(j)wk(i)
4、 粒子退化
4.1、 粒子退化问题
SIS 算法在经历次多次迭代后,粒子重要性权重的方差可能将变得很大,从而引发粒子退化问题(Particle Degeneracy Problem)。所谓粒子退化,指的是大量粒子中只有少数粒子具有较高权重,而绝大多数粒子的权重都很小甚至接近于0,导致计算加权均值时大量的运算资源被浪费在了小权重粒子上。进而是的估计性能下降,如下图所示:
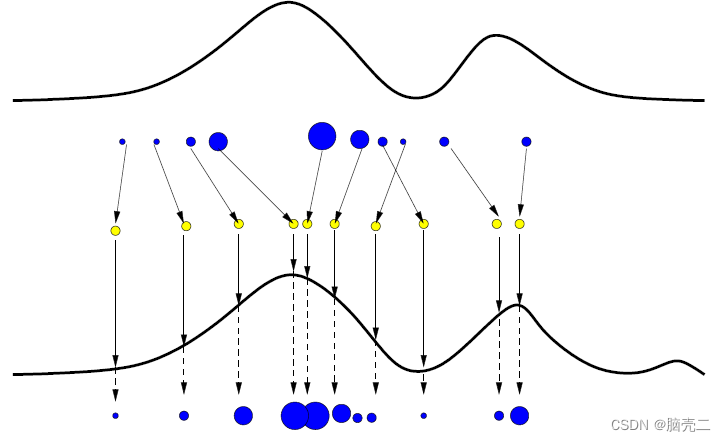

粒子退化问题发生的根本原因是建议分布与真实分布的不匹配。
4.2、 粒子退化度量
序贯重要性采样的一个常见问题就是粒子退化现象,即经过若干次迭代之后,除了少数几个粒子,大部分其他粒子的权值将小到可以忽略不计。粒子退化现象的原因在于,重要性权值的方差将随时间的推移而增加。因此,粒子退化问题的存在意味着大量的计算工作将浪费在更新那些对 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)的估计作用几乎为零的粒子上。下面给出了一种衡量算法的粒子退化程度的方法,定义有效样本数(effective sample size)为
N e f f = N 1 + var ( w k ∗ ( i ) ) N_{eff}=\frac{N}{1+\text{var}(w_k^{*(i)})} Neff=1+var(wk∗(i))N
式中, w k ∗ ( i ) w_k^{*(i)} wk∗(i)是真权值。有效样本无法通过计算准确得到,但可以用一下估计获得
N ^ e f f = N 1 + ∑ i = 1 N ( w ~ k ( i ) ) 2 \hat{N}_{eff}=\frac{N}{1+\sum_{i=1}^N(\tilde{w}_k^{(i)})^2} N^eff=1+∑i=1N(w~k(i))2N
式中, w ~ k ( i ) \tilde{w}_k^{(i)} w~k(i)是粒子重要性权重归一化。易知 N ^ e f f ≤ N e f f \hat{N}_{eff}\leq N_{eff} N^eff≤Neff,而很小的 N ^ e f f \hat{N}_{eff} N^eff意味着粒子严重退化。显然粒子退化问题是在粒子滤波过程中所不希望看到的,一种强制措施是采用大量粒子,增大粒子数N,这种方法通常情况下是不现实的。因此,可考虑采用两种解决方案:
- 选择合适的重要性密度函数
- 粒子重采样法
4.3、 选择合适的重要性密度函数
针对“选择合适的重要性密度函数”问题,常用的选取方案是次优的重要性密度函数,即.
q ( x k ∣ x k − 1 ( i ) , z k ) = p ( x k ∣ x k − 1 ( i ) ) q(x_k |x_{k-1}^{(i)}, z_{k})=p(x_k |x_{k-1}^{(i)}) q(xk∣xk−1(i),zk)=p(xk∣xk−1(i))
进而得到
w k ( i ) = w k − 1 ( i ) p ( z k ∣ x k ( i ) ) w_k^{(i)}=w_{k-1}^{(i)}p(z_k |x_{k}^{(i)}) wk(i)=wk−1(i)p(zk∣xk(i))
同样 w k ( i ) w_k^{(i)} wk(i)需要归一化得到 w ~ k ( i ) \tilde{w}_k^{(i)} w~k(i)。
这种方案虽然未能利用最新的量测信息,使得采样粒子的方差较大,但其优点在于较为直观且易于实现,所以得到了广泛使用。
5、 粒子重采样
重采样的思路是:既然那些权重小的不起作用了,那就不要了。要保持粒子数目不变,得用一些新的粒子来取代它们。找新粒子最简单的方法就是将权重大的粒子多复制几个出来,至于复制几个?那就在权重大的粒子里面让它们根据自己权重所占的比例去分配,也就是老大分身分得最多,老二分得次多,以此类推。下面以数学的形式来进行说明。
下面先给出常用的重采样方法:
系统重采样
多项式重采样
残差重采样
随机重采样
重采样(resampling)也是抑制粒子退化现象的一种有效方法。重采样法的主要思
想是,预先设定一个 N τ Nτ Nτ作为有效样本数N的阈值,当 N ^ e f f \hat{N}_{eff} N^eff低于 N τ Nτ Nτ时进行重采样,其目的在于抑制权值较小的粒子,而只关心权值较大的粒子。重采样的步骤是,对于给定的后验概率密度函数 p ( x k ∣ z k ) p(x_k |z^{k}) p(xk∣zk)的离散近似:
p ( x k ∣ z k ) ≈ 1 N ∑ i = 1 N δ ( x k − x k ( i ) ) w k ( i ) p(x_k |z^{k})\approx\frac{1}{N}\sum_{i=1}^N\delta(x_k-x_k^{(i)})w_k^{(i)} p(xk∣zk)≈N1i=1∑Nδ(xk−xk(i))wk(i)
采样 N N N次重新生成一组新的粒子 x k ( i ) x_k^{(i)} xk(i),使得 P ( x k ( i ) = x k j ) = w k ( j ) P(x_k^{(i)}=x_k^{j}) =w_k^{(j)} P(xk(i)=xkj)=wk(j)。而根据重采样粒子的独立同分布特性,其权值将重置为 w k ( i ) = 1 / N w_k^{(i)}=1/N wk(i)=1/N。
这一过程可以通过下图加以解释,同样途中圆圈的大小代表粒子所占的权重大小。
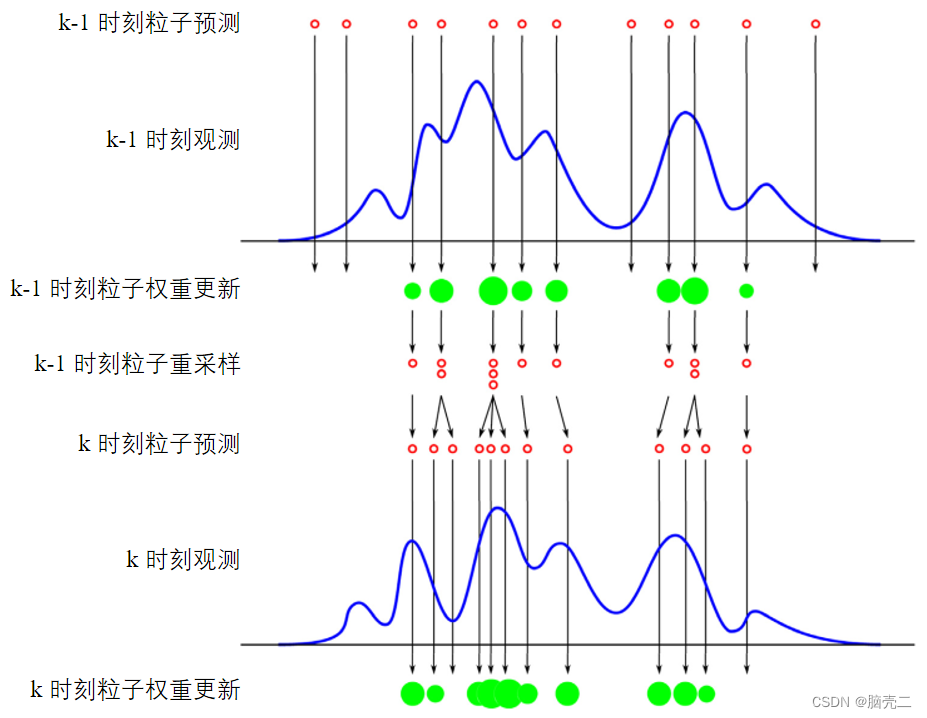
需要指出的是,虽然重采样方法在某种程度上可以抑制粒子退化问题,但会降低粒子的多样性,使得原本权值较小的粒子缺乏子代粒子,而少数权值较大的粒子具有多个相同的子代粒子。常用的重采样方法包括系统重采样、多项式重采样、残差重采样、随机重采样等。
其中基于系统重采样的SIS粒子滤波也被称之为:标准的粒子滤波
本人更喜欢随机重采样,它的讲解比较清楚在Dan Simon的《最优状态估计 卡尔曼滤波, H ∞ 滤 波 和 非 线 性 滤 波 H_\infty滤波和非线性滤波 H∞滤波和非线性滤波》
下面给出系统重采样方法及代码:
算法:系统重采样 (systematic resampling)
For i = 1 : N i=1:N i=1:N
Step 1: 初始化累积概率密度函数CDF: c 1 = 0 c_1=0 c1=0
For i = 2 : N i=2:N i=2:N
Step 2: 构造CDF: c i = c i − 1 + w k ( i ) c_i=c_{i-1}+w_k^{(i)} ci=ci−1+wk(i)
Step 3: 从CDF的底部开始: i = 1 i=1 i=1
Step 4: 采样起始点: u 1 = U [ 0 , 1 / N ] u_1=\mathcal{U}[0,1/N] u1=U[0,1/N]
End For
For j = 1 : N j=1:N j=1:N
Step 5: 沿CDF移动: u j = u 1 + ( j − 1 ) / N u_j=u_{1}+(j-1)/N uj=u1+(j−1)/N
Step 6: While u j > c i u_j>c_i uj>ci
i = i + 1 i=i+1 i=i+1
End While
Step 7: 赋值粒子: x k ( j ) = x k ( i ) x_k^{(j)}=x_k^{(i)} xk(j)=xk(i)
Step 8: 赋值权值: w k ( j ) = 1 / N w_k^{(j)}=1/N wk(j)=1/N
Step 9: 赋值父代: i ( j ) = i i^{(j)}=i i(j)=i
End For
代码:系统重采样 (systematic resampling)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 系统重采样子函数
% 输入参数:weight为原始数据对应的权重大小
% 输出参数:outIndex是根据weight筛选和复制结果
function outIndex = systematicR(weight);
N=length(weight);
N_children=zeros(1,N);
label=zeros(1,N);
label=1:1:N;
s=1/N;
auxw=0;
auxl=0;
li=0;
T=s*rand(1);
j=1;
Q=0;
i=0;
u=rand(1,N);
while (T<1)
if (Q>T)
T=T+s;
N_children(1,li)=N_children(1,li)+1;
else
i=fix((N-j+1)*u(1,j))+j;
auxw=weight(1,i);
li=label(1,i);
Q=Q+auxw;
weight(1,i)=weight(1,j);
label(1,i)=label(1,j);
j=j+1;
end
end
index=1;
for i=1:N
if (N_children(1,i)>0)
for j=index:index+N_children(1,i)-1
outIndex(j) = i;
end;
end;
index= index+N_children(1,i);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
6、基于系统重采样的SIRPF的在目标跟踪应用:
6.1、 仿真参数
**一、目标模型:CT(细节见另一个博客) **
X k + 1 = [ 1 sin ( ω T ) ω 0 − 1 − cos ( ω T ) ω 0 cos ( ω T ) 0 − sin ( ω T ) 0 1 − cos ( ω T ) ω 1 sin ( ω T ) ω 0 sin ( ω T ) 0 cos ( ω T ) ] X k + [ T 2 / 2 0 T 0 0 T 2 / 2 0 T ] W k X_{k+1}=\begin{bmatrix}1&\frac{\sin(\omega T)}{\omega}&0&-\frac{1-\cos(\omega T)}{\omega}\\0&\cos(\omega T)&0&-\sin(\omega T)\\0&\frac{1-\cos(\omega T)}{\omega}&1&\frac{\sin(\omega T)}{\omega}\\0&\sin(\omega T)&0&\cos(\omega T)\end{bmatrix}X_{k} + \begin{bmatrix}T^2/2&0\\T&0\\0&T^2/2\\0&T\end{bmatrix}W_k Xk+1=⎣⎢⎢⎡1000ωsin(ωT)cos(ωT)ω1−cos(ωT)sin(ωT)0010−ω1−cos(ωT)−sin(ωT)ωsin(ωT)cos(ωT)⎦⎥⎥⎤Xk+⎣⎢⎢⎡T2/2T0000T2/2T⎦⎥⎥⎤Wk
CV CT 模型的具体方程形式见另一个博客
二、测量模型:2D主动雷达
在二维情况下,雷达量测为距离和角度
r k m = r k + r ~ k b k m = b k + b ~ k {r}_k^m=r_k+\tilde{r}_k\\ b^m_k=b_k+\tilde{b}_k rkm=rk+r~kbkm=bk+b~k
其中
r k = ( x k − x 0 ) + ( y k − y 0 ) 2 ) b k = tan − 1 y k − y 0 x k − x 0 r_k=\sqrt{(x_k-x_0)^+(y_k-y_0)^2)}\\ b_k=\tan^{-1}{\frac{y_k-y_0}{x_k-x_0}}\\ rk=(xk−x0)+(yk−y0)2)bk=tan−1xk−x0yk−y0
[ x 0 , y 0 ] [x_0,y_0] [x0,y0]为雷达坐标,一般情况为0。雷达量测为 z k = [ r k , b k ] ′ z_k=[r_k,b_k]' zk=[rk,bk]′。雷达量测方差为
R k = cov ( v k ) = [ σ r 2 0 0 σ b 2 ] R_k=\text{cov}(v_k)=\begin{bmatrix}\sigma_r^2 & 0 \\0 & \sigma_b^2 \end{bmatrix} Rk=cov(vk)=[σr200σb2]
6.2、 跟踪轨迹
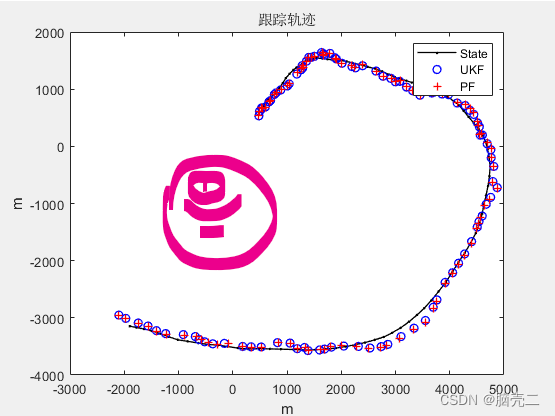
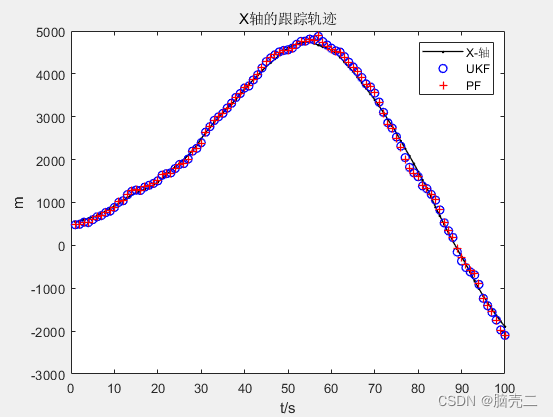
6.3、 跟踪误差(RMSE)
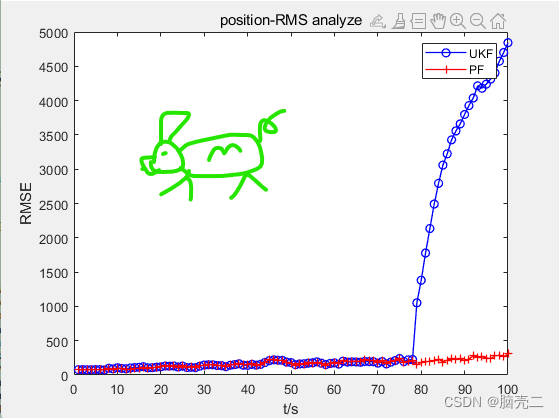
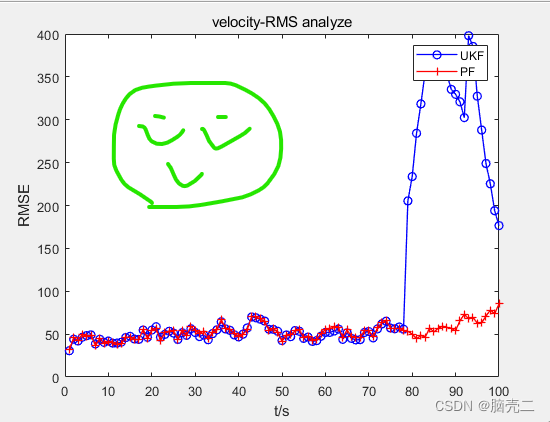
PF的妈妈贝叶斯滤波、基于标准的粒子滤波见Part-I和Part-V
原创不易,路过的各位大佬请点个赞