本篇博客将按照机器学习简介中机器学习建模步骤,结合宝可梦(神奇宝贝)具体数据进行案例分析。
目录
Objective
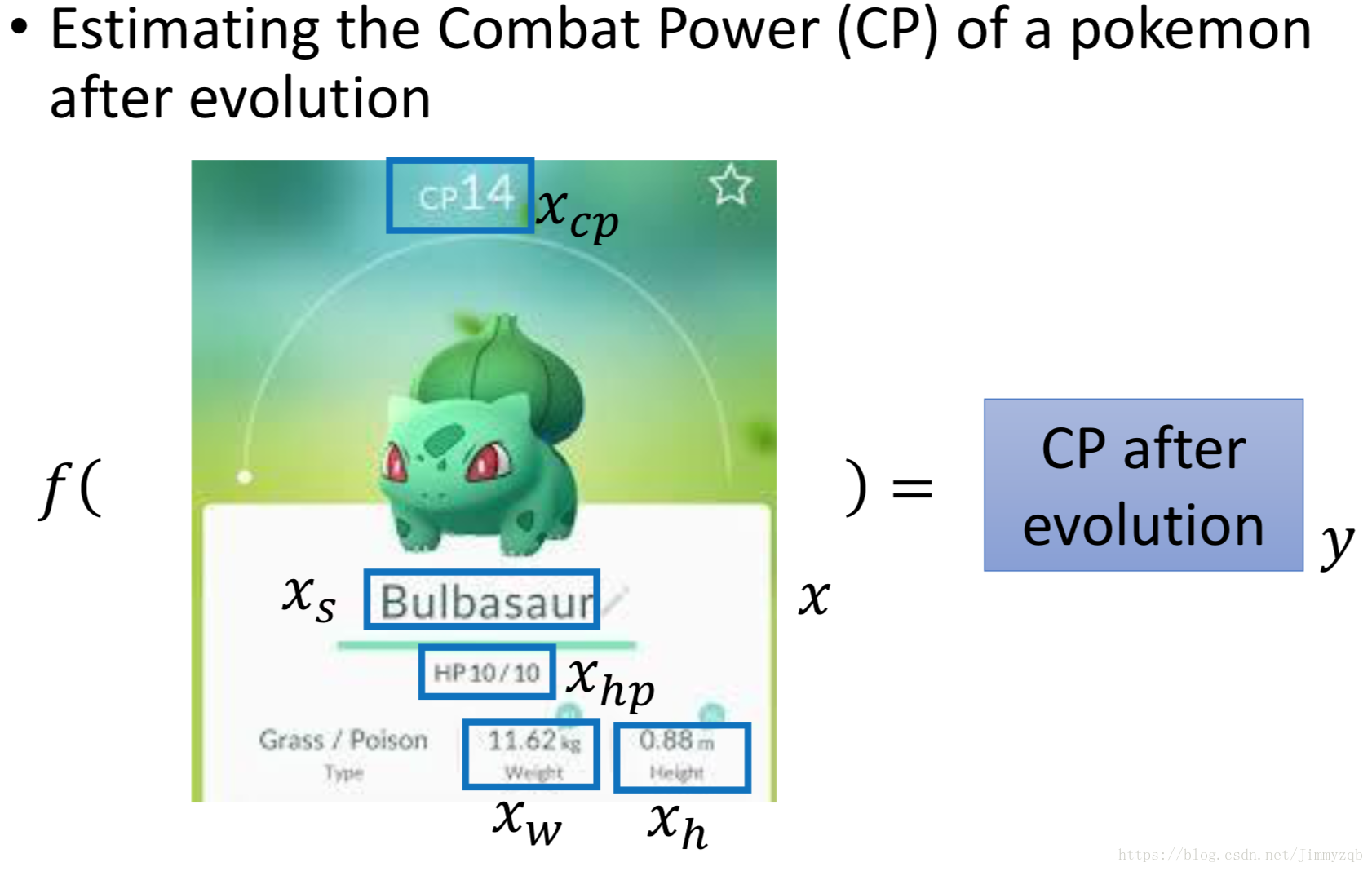
通过训练宝可梦属性的历史数据构建回归模型,输入宝可梦进化前的属性数据,预测宝可梦进化后的Combat Power (CP)。
step1:Model
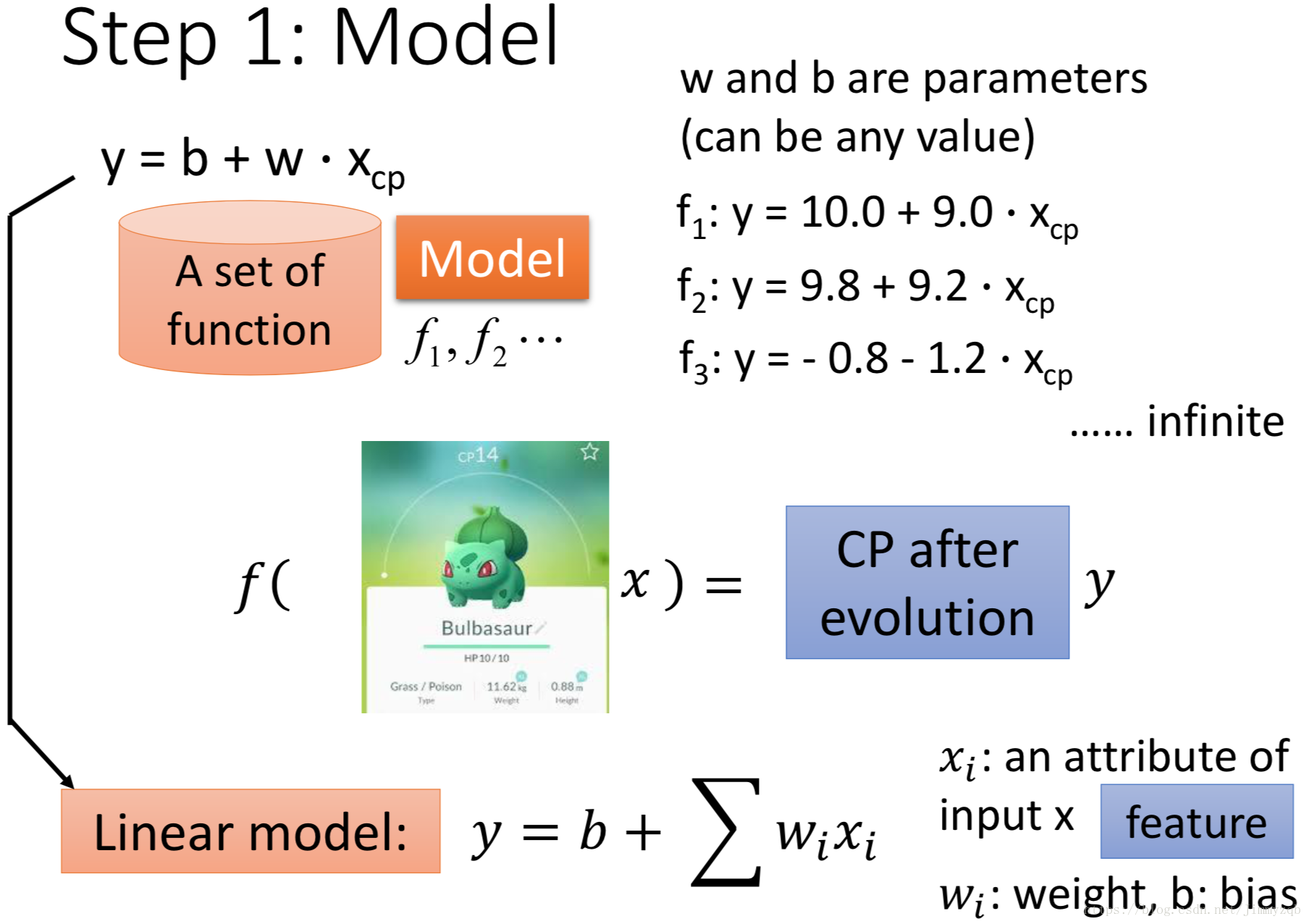
假设进化前的
与进化后的
的(即
)存在关系
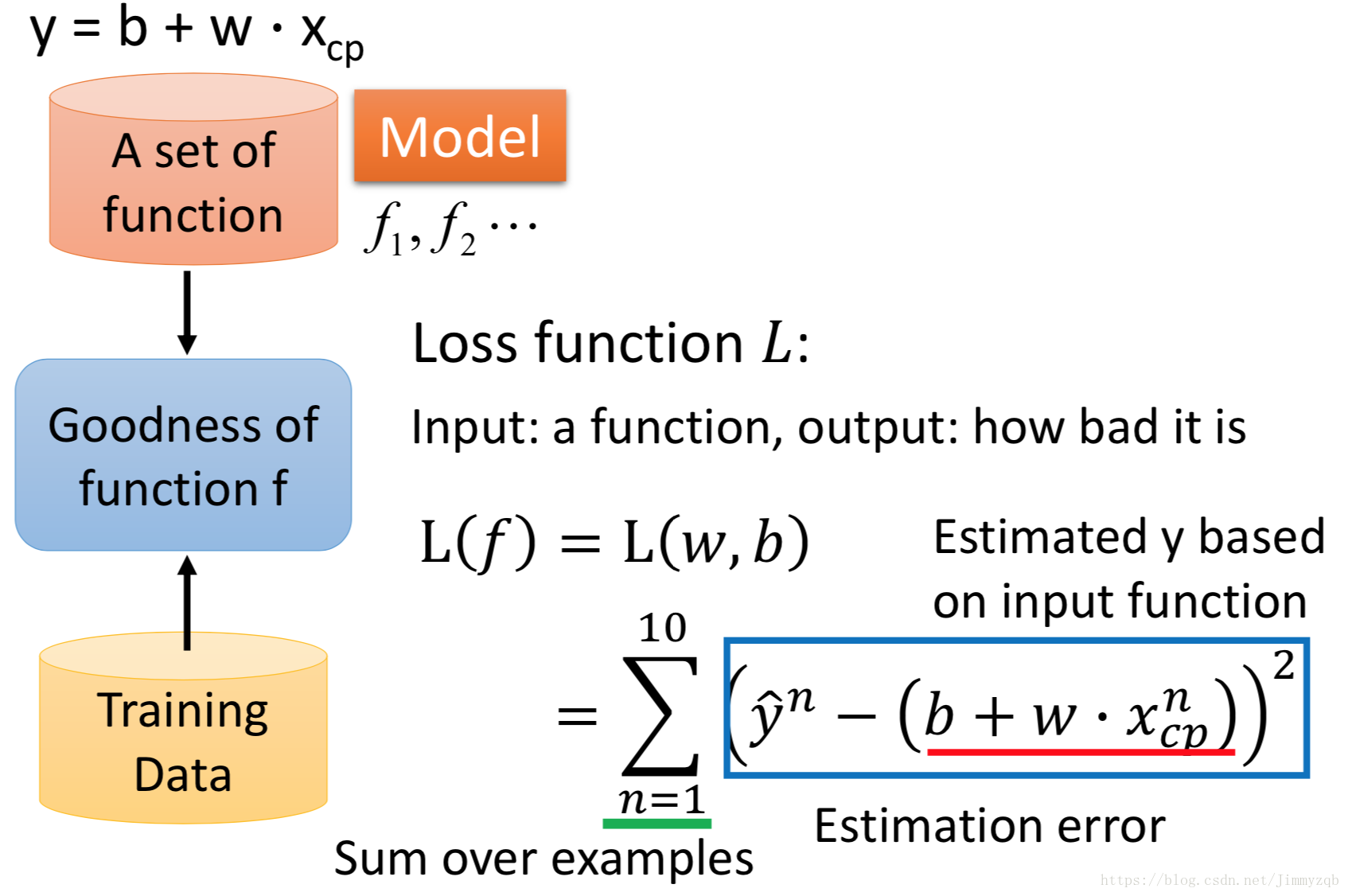
step2:Goodness of Function
表示第
个观测(进化前的CP),
表示第
个观测的真实值(进化后的CP),现在捕捉10只宝可梦,记录这10只宝可梦进化前和进化后的CP(
),在这一案例中
。
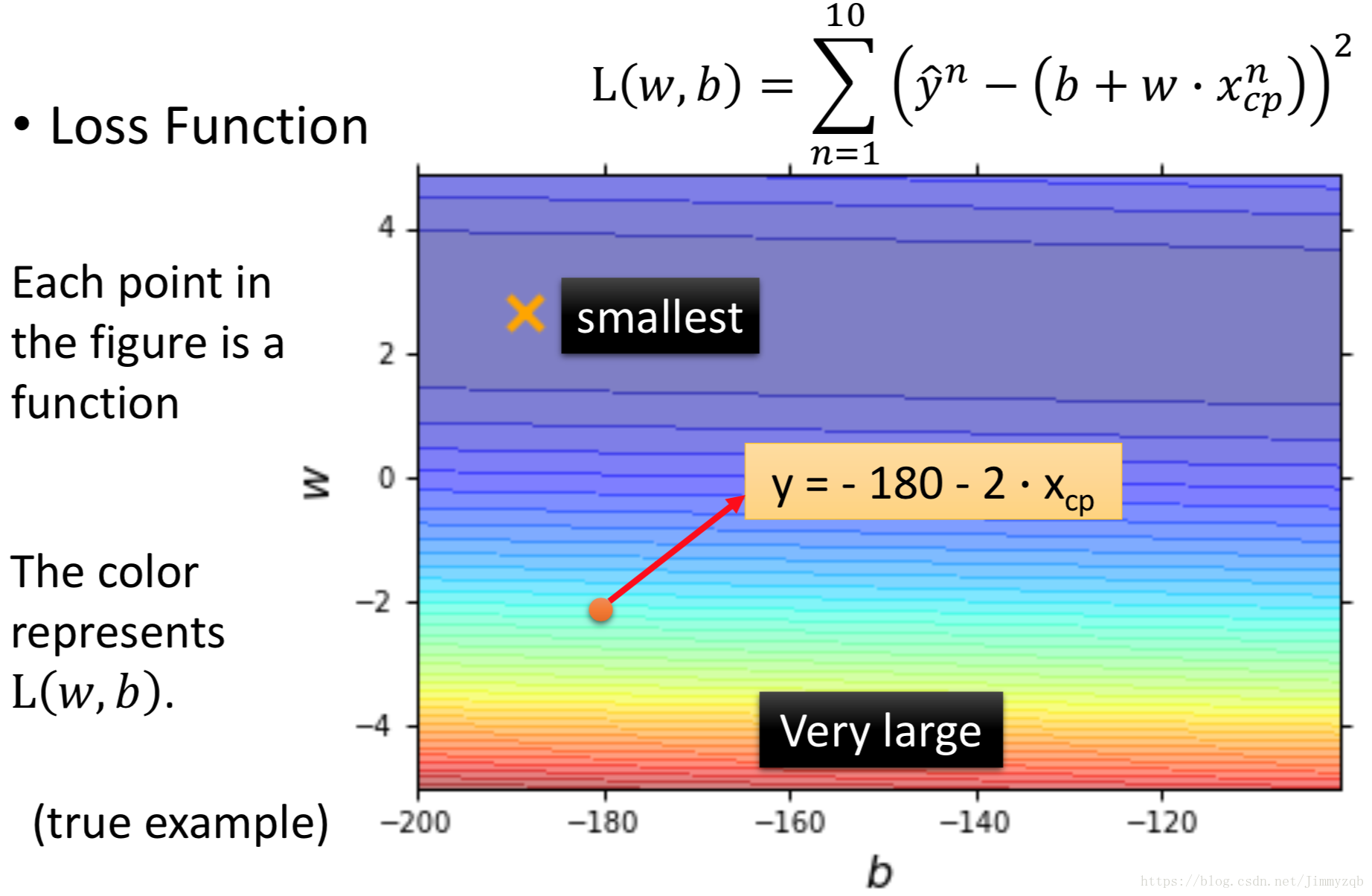
Loss function L由
控制,可视化如图,冷色调代表低
值,暖色调代表高
值,
step3:Best Function
从Step1中的
选择最优函数
,
,在这一案例中,即

求 函数最小值问题一般用梯度下降法来进行计算,步骤如下:
- 随机初始化
- 计算函数 在 处的偏导 , ,其中 为学习速率(Learning rate)
- 重复第二步直到
收敛
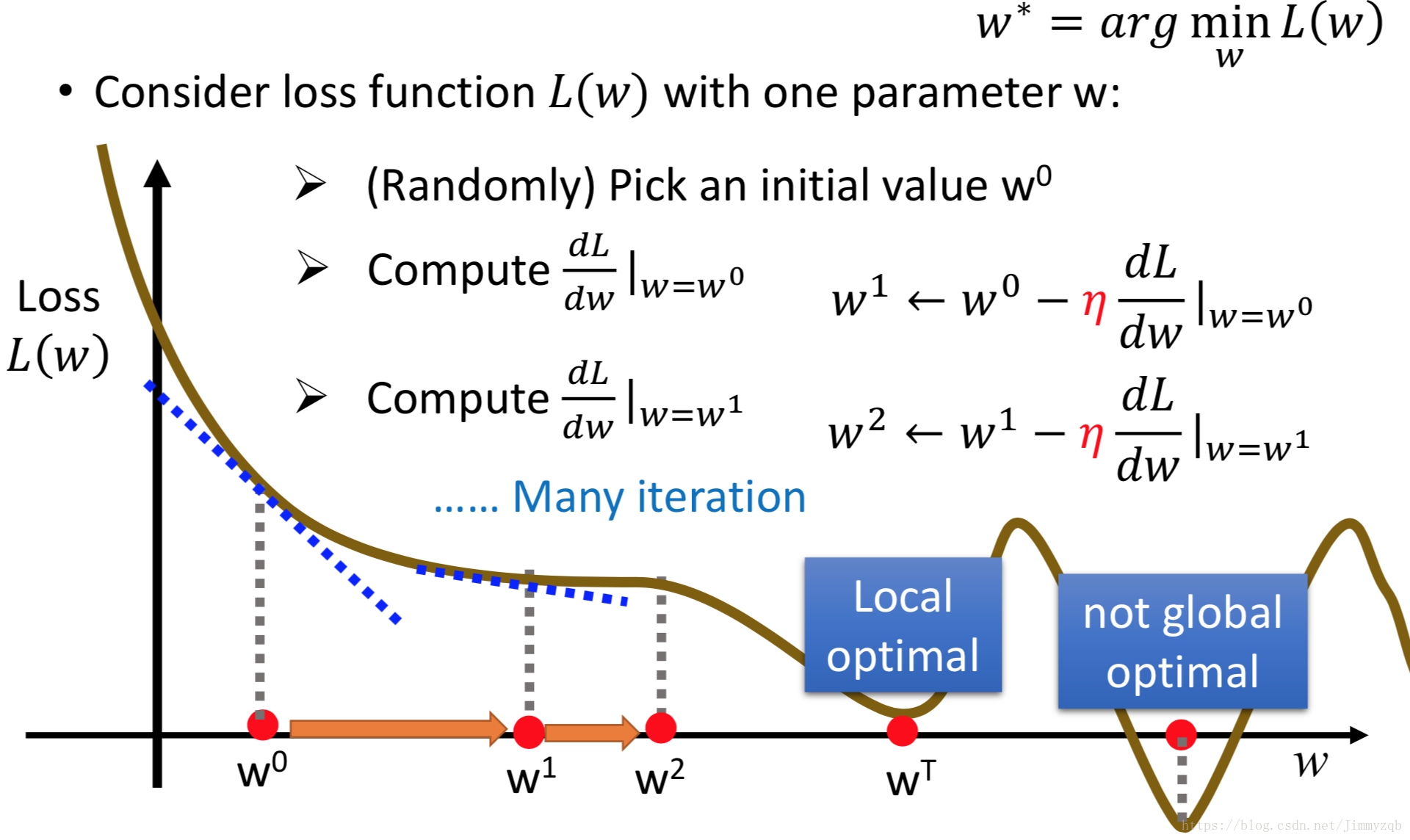
注意:梯度下降方法可能得到的是局部最优,在线性回归模型中,函数是凸的,因此梯度下降得到的最优解即全局最优解使用梯度下降算法求解案例最小化问题,
,表示训练集中第 个观测的误差,使用新捕捉的10只宝可梦作为测试集计算平均误差,以此来评价模型的泛化能力,现在我们考虑更复杂的线性模型,即在Step1中的 不再仅仅使用的 一次变量。(tips:模型的总误差可以从bias和variance两方面考虑,bias衡量训练集的拟合效果,variance衡量测试集结果的稳定性)
| Model | Best Function | 训练集平均误差 | 测试集平均误差 |
|---|---|---|---|
| 35.0 | 31.9 | ||
| 15.4 | 18.4 | ||
| 15.3 | 18.1 | ||
| 14.9 | 28.8 | ||
| 12.8 | 232.1 |

当模型越复杂,训练集平均误差越低,如图可以直观地理解,在越复杂的模型(对应越大的集合)找到的best function拟合效果显然越好,但是测试集平均误差并不是单调递减,在引入4次、5次项之后反而急剧增大,此时产生了过拟合问题(可以尝试增加训练集样本来解决)。
现在我们考虑更复杂的线性模型,即在Step1中的
不再仅仅使用的
这一变量,引入变量
(宝可梦种族),此时训练集平均误差为3.8,测试集平均误差为14.3,模型拟合与泛化效果都增强,在此基础上考虑变量的二次项,
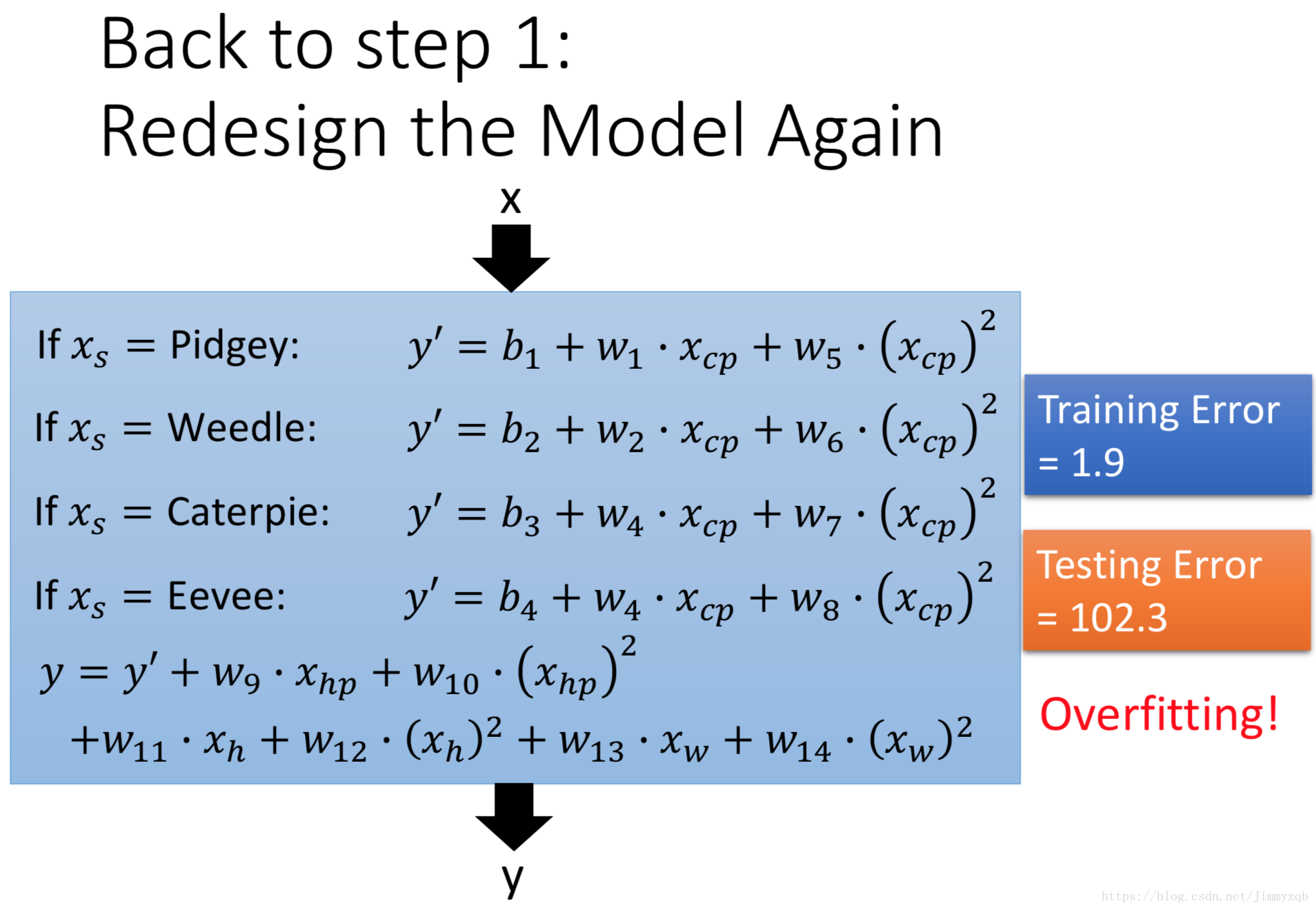
此时模型过拟合,使用正则化方法来解决过拟合问题,即使Step2中的loss function 不仅仅考虑error,还考虑了参数个数,
,此时我们假设平滑的
更接近真正的
。
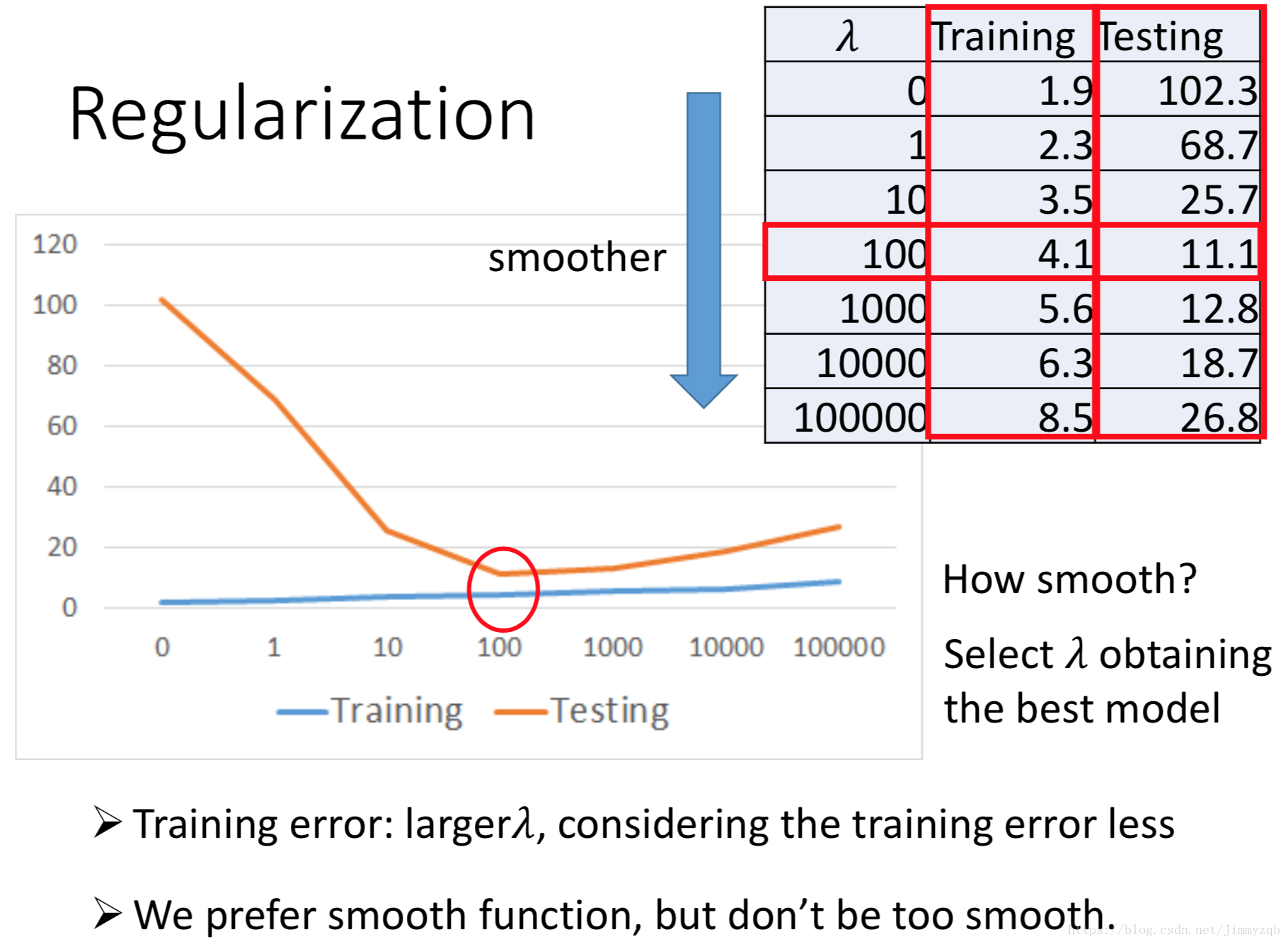
为了兼顾最小化第二项,训练集平均误差相对于没有正则化的方法高,但是测试集平均误差降低,大大减少了过拟合的影响。
demo
# 进化前后CP值数据
x_data=[338.,333.,328.,207.,226.,25.,179.,60.,200.,606.]
y_data=[640.,633.,619.,393.,428.,27.,193.,66.,226.,1591.]
# 假设模型
#y_data = b + w*x_data
# 初始化w、b
w,b = -4,-120
# 学习速率
lr = 0.000001
# 迭代次数
iter = 100000
b_history=[b]
w_history=[w]
for i in range(iter):
b_grad = 0.0
w_grad = 0.0
for n in range(len(x_data)):
b_grad -= 2.0*(y_data[n] - b*w*x_data[n])*1.0
w_grad -= 2.0*(y_data[n] - b*w*x_data[n])*x_data[n]
# 更新参数
b = b -lr*b_grad
w = w -lr*w_grad
# 储存w、b
b_history.append(b)
w_history.append(w)