链接:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/Regression%20(v6).pdf
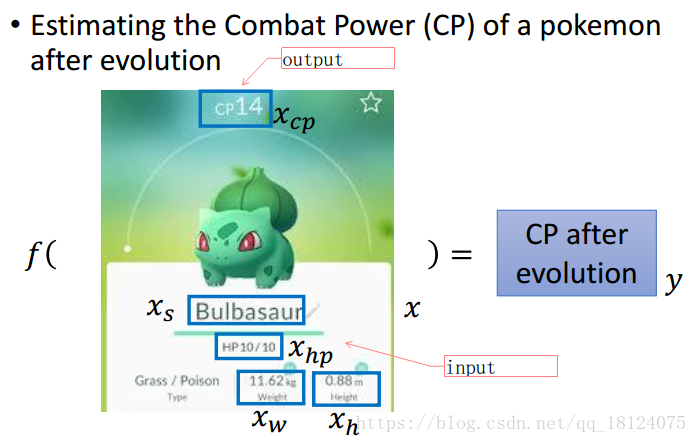
这里,李宏毅通过对宝可梦进化前的各项参数去预测进化后的各项参数,从而判断这个宝可梦是否能够进化来进行研究。整个研究思路我觉得还是具有很好的借鉴意义。
大概的模型建立步骤,无论是《统计学习方法》的李航还是《机器学习》的吴恩达,还是这里的李宏毅,我觉得他们的方法都是大同小异。这里,我们以李宏毅的研究思路为主。
步骤1是确定这个function set,输入的是进化前的某项或者多项参数,输出是进化后的CP值。

步骤2是如何从这么多的含有多个function的集合中选择最适合的那个function,这里我们需要构建一个Loss function,从而衡量w和b的好坏。

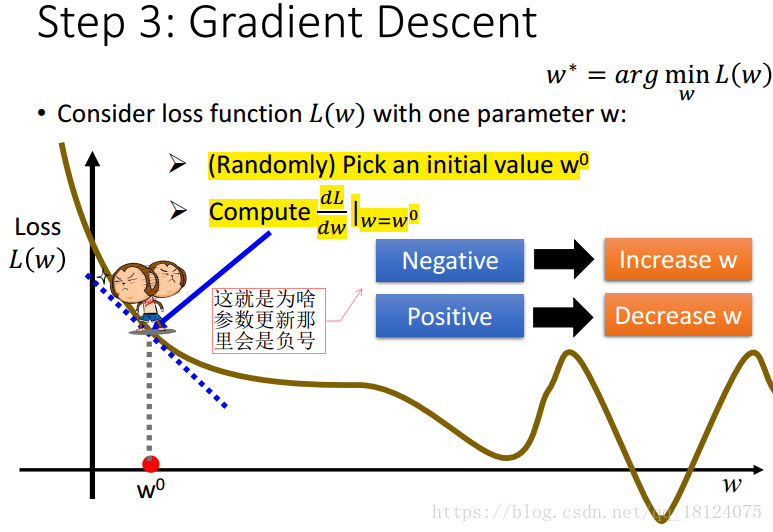
步骤3是如何使用这个Loss function从function set选取最好的那个function。此时,我们假设function set一般都是无限的,所有不可能去枚举所有的function。这里,我们可以采用梯度下降法,从而对w和b进行更新。

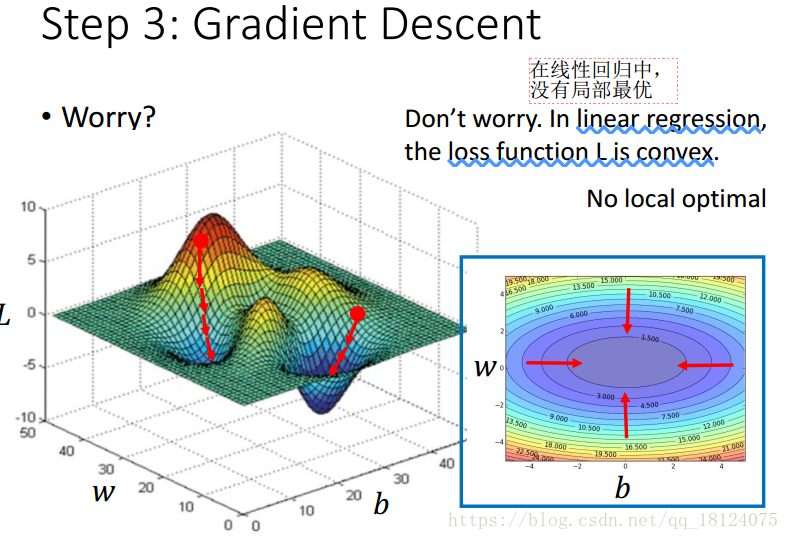
这里,对于非线性问题,梯度下降法很容易进入局部最优里面,但是在线性回归中,loss function是convex。
对于过拟合问题,虽然说在训练集上越复杂的模型其误差也就越小,这是因为更复杂的模型包含了更多简单的模型,所有其效果肯定要比那些简单的模型好很多。
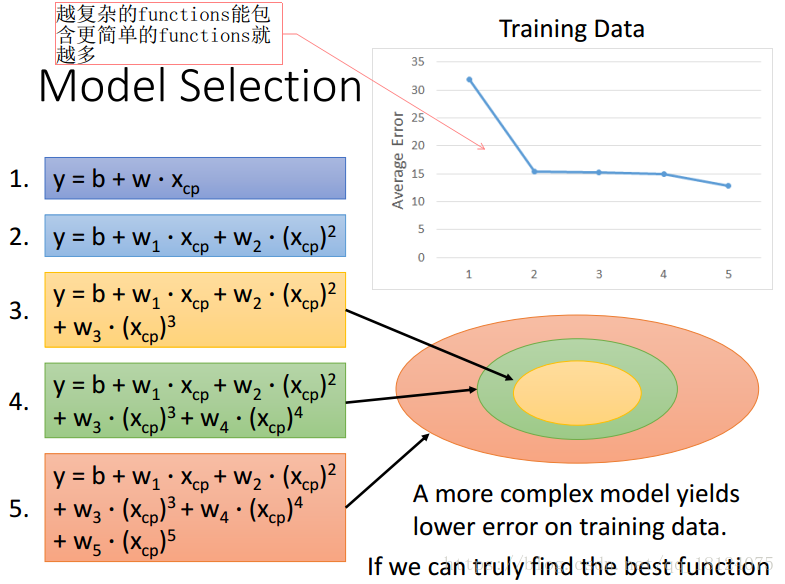
虽然越复杂的模型在训练集上效果特别好,但是在测试集上并非如此。我们追求的是一种泛化能力,因为训练集和测试集的分布都是不相同的,我们寻找的model是要适用于整个数据集的一个分布,有点像猜谜的感觉。

改进1:
对于以上的模型,我们是把所有宝可梦的进化前cp值作为输入,进化后的cp值作为你输出,这样其实并不好。所有我们根据种类对其你进行重新建模。
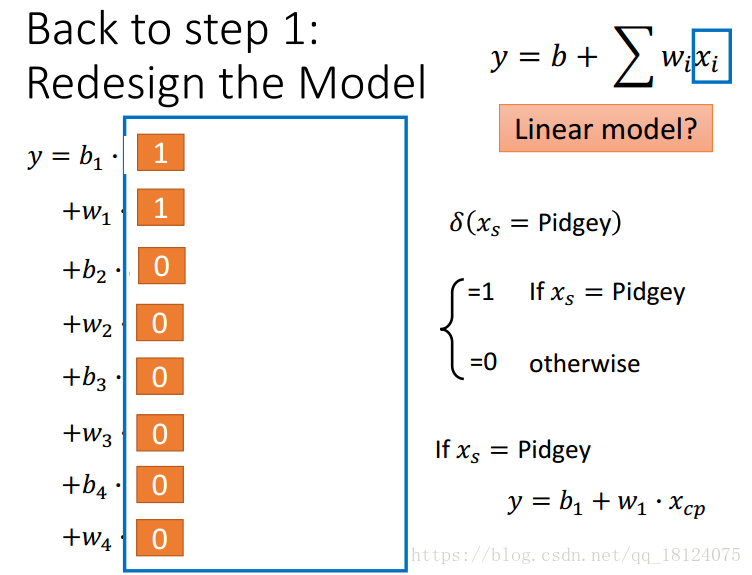
改进2:
如果将我们考虑各种种类,然后每一类考虑多次,这样我们构建了一个特别复杂的模型,其结果如下:

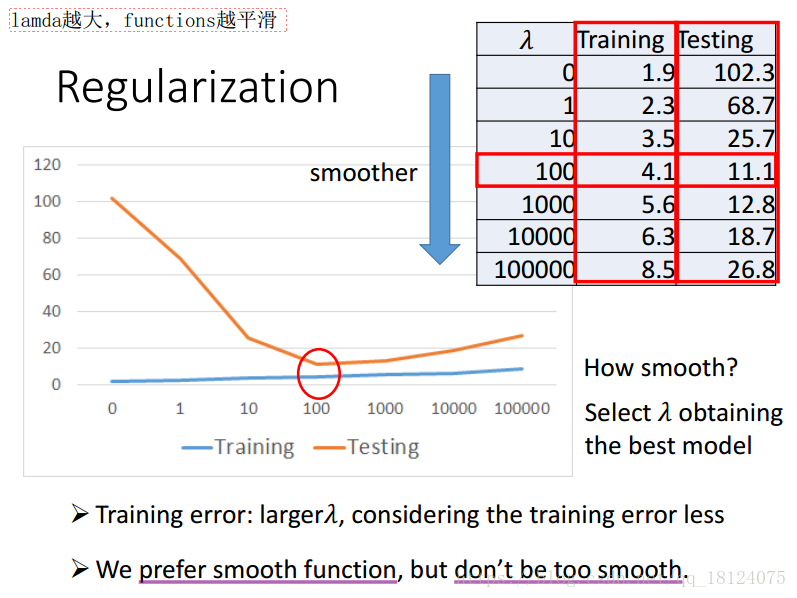
为了解决这类问题,我们决定加入正则项,即惩罚项。加入惩罚项的目的是可以使得loss function变得更平滑,但是太平滑效果也不会太好。