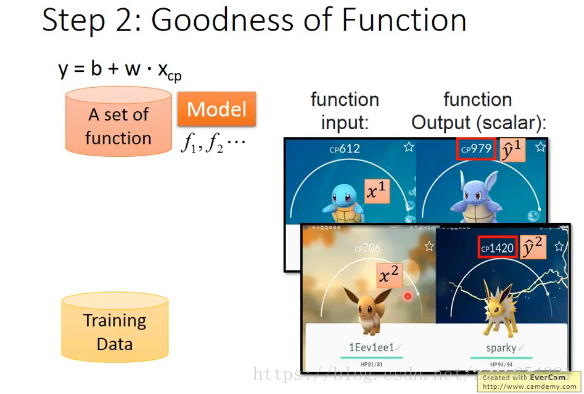
Regression案例:
宝可梦的CP值预测。

Xcp,Xs,Xhp,Xw,Xh为输入,Y为输出。
假设Xcp与Y有很大关系。
下面根据P1笔记中的三个步骤来进行:

先建立一个模型。

使用一组训练数据来训练模型。

用Loss function L来衡量你的function:

f由w,b决定,故我们可以把L里面的参数换成w,b。
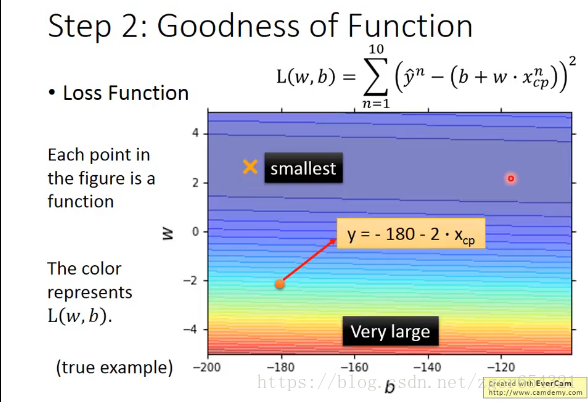
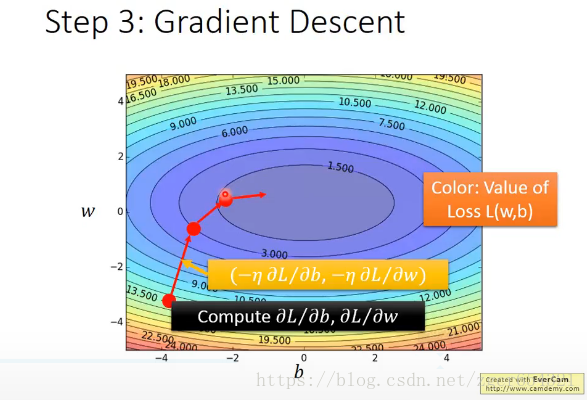
上图里面的图表中每一个点都是由w,b决定的一个function。颜色代表了对应的L(f)的值的大小,红色比较大,蓝色比较小。
下面我们要找出最好的function。

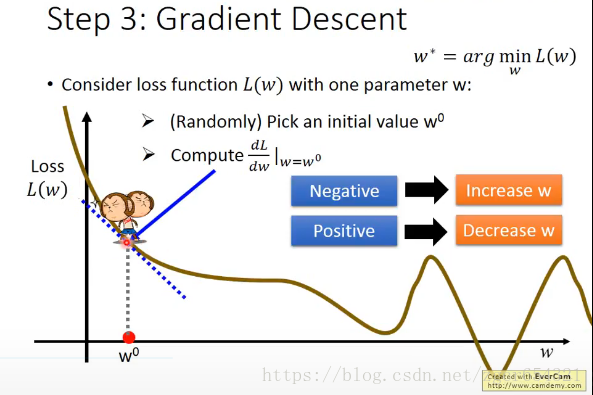
最好的function就是L(w,b)值最小时候的function。我们可以使用Gradient Descent方法来寻找L(w,b)min。


多次学习之后的结果:
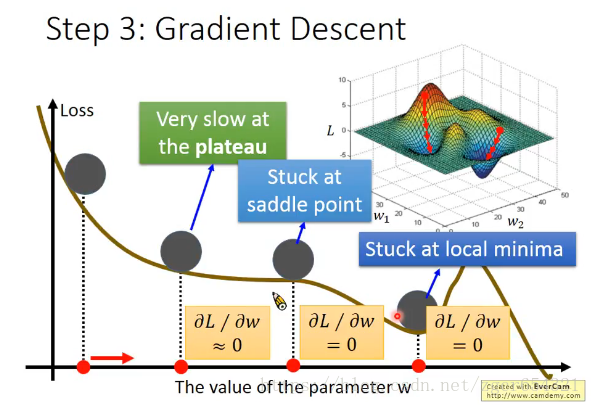
从不同的地方开始,可能会得到局部最优解(local minima)或全局最优解(global minima)。
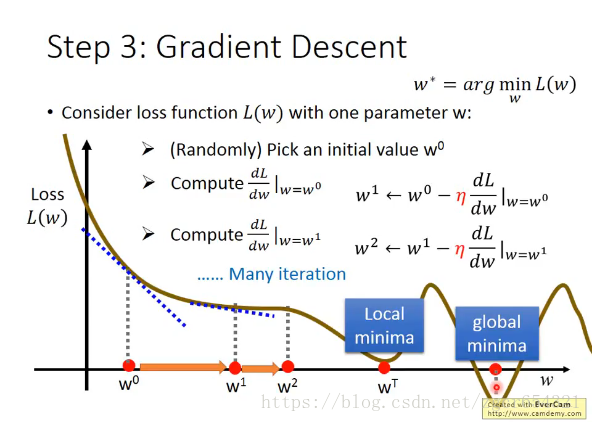
上面是只有一个参数w的情况,如果有两个参数w和b呢?

每次gradient的结果可以用
我们可以将所有的gradient的结果用类似等高线的图来表示出来:
当然如果有超过两个参数,我们也可以用gradient descent方法。我们用

理想状态下我们每次更新
在理想状态中,我们找到local minima时,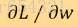

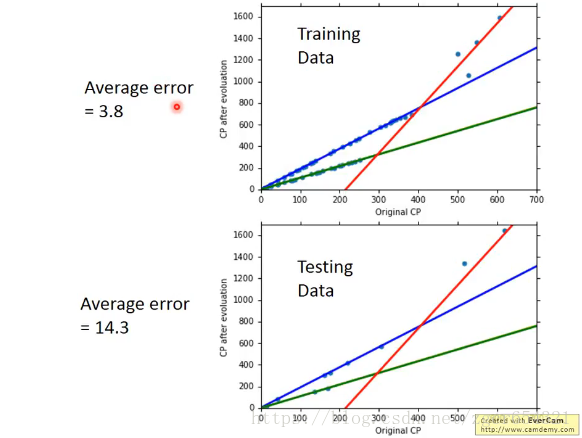
以上面宝可梦的训练数据,先训练模型,找出最合适的b和w:
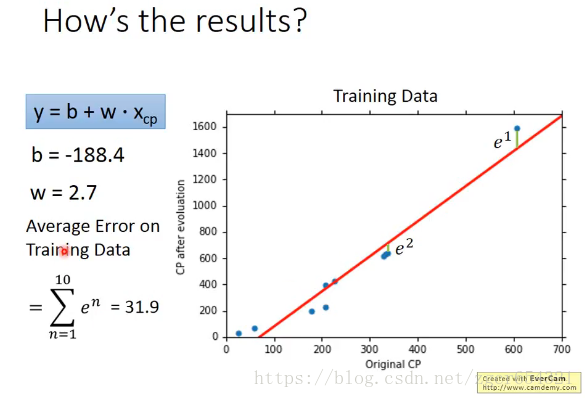
再用一组测试数据,套用模型,计算其偏差:
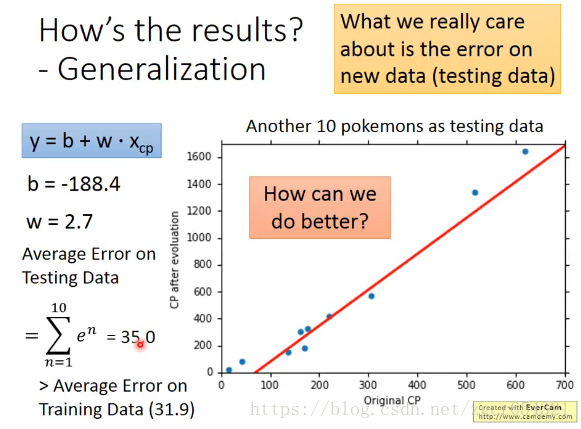
可以看到偏差略大于训练数据的偏差,较为符合实际。
我们还可以选择其他model来减小误差:
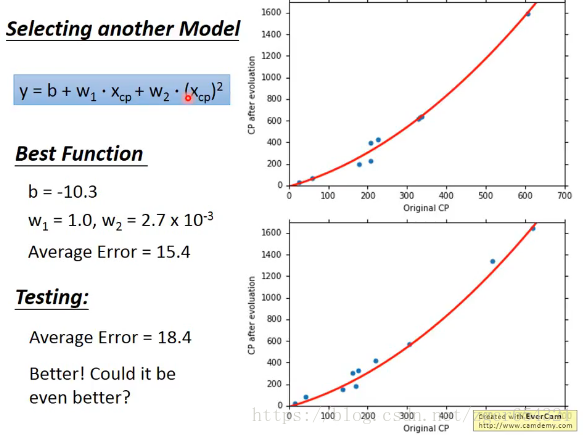
显然这个模型的误差要更小,更加贴合实际。
需要注意的是,虽然这个model是个二次多项式,但它仍然是linear model。
我们继续尝试三次多项式的model。
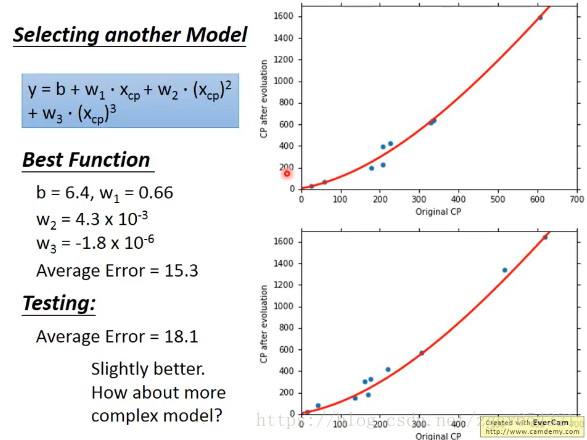
尝试四次多项式的model。
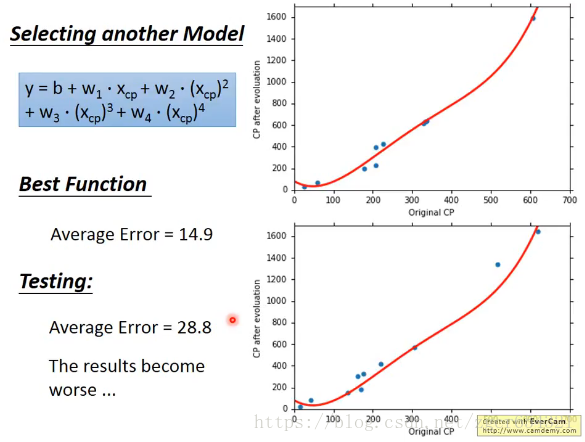
我们可以看到test误差反而上升了。。。
尝试五次多项式的model:
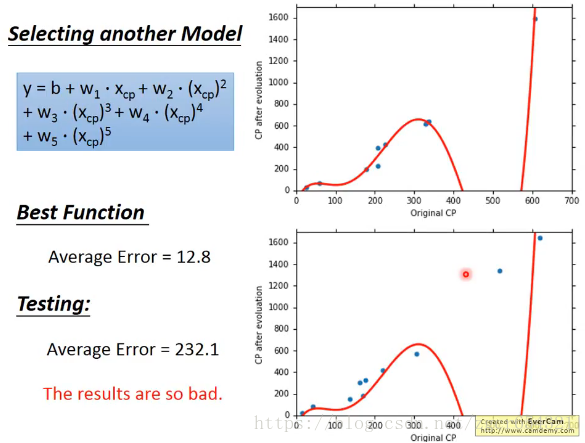
显然从图像上就能看出这个model是不合理的。
test误差非常大。
model之间的关系:3次多项式是4次的子集合,4次是5次的子集合。

当model越来越复杂时,在training data上的error越来越低。
但是在testing data中,3次多项式的error最低。

可以看到在training data上表现最好的model在testing data上并不是表现最好的。这种情况称为overfitting(过度拟合)。而我们在实际应用中更关心model在testing data上的表现。
如果我们收集了更多的数据后,会发现显然有更多的隐藏因素影响宝可梦的CP值。
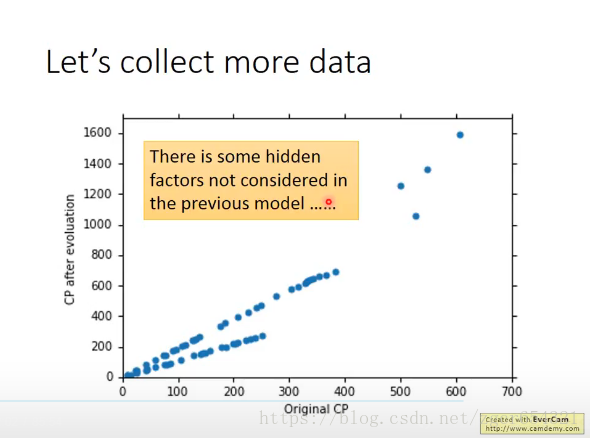
把不同种类的宝可梦用不同颜色区分,可以看到:

重新设计model function:
增加一个变量,宝可梦的种类Xs:
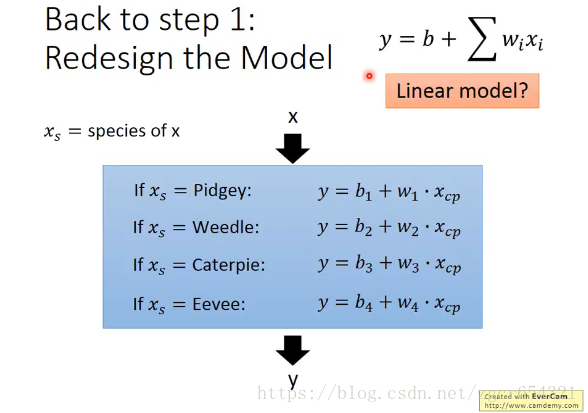
注意:这个model仍然是linear model。
上面这个model可以写成下面的形式,这样看起来是不是容易看出来是linear model了?

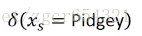

假如输入

用training data来训练这个新的model,再用testing data测试该model:
注意图中绿色线和黄色线重合了。
有什么其他的因素可能会影响宝可梦的CP值吗?
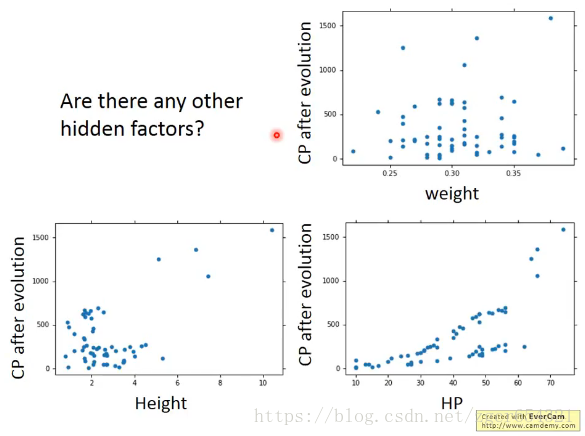
我们列出一些可能影响宝可梦CP值的因素。把这些因素全部加入model中。

Xhp表示hp值因素,Xh表示height因素,Xw表示weight因素。
可以发现又出现了overfitting现象。
我们尝试换一个Loss function,对Loss function参数进行改进,后面增加一项: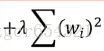
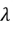
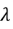
我们对model的y函数也做一些改进,使曲线smoother。因为多数情况下smoother的function比较有可能是更加正确的function。

注意b这一项是曲线水平的高度,对曲线是否smooth没有影响。这个b(即bias)上不需要加regularization(正则化)。regularization(正则化)实际上说的就是加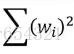
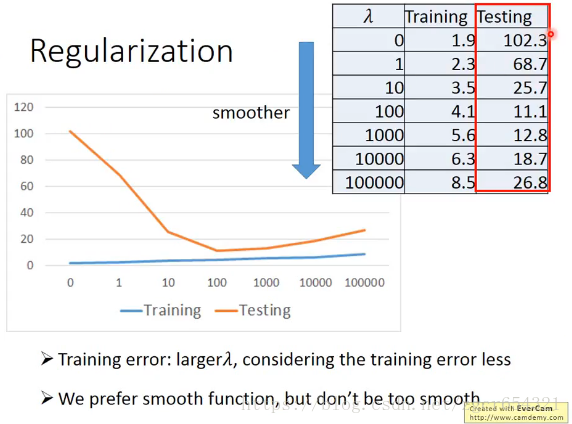
本节结论:

实际情况是遇到新data时error往往更大。