回顾
上个笔记的最后我们已经化简了模型,今天我们继续来研究如何计算模型。
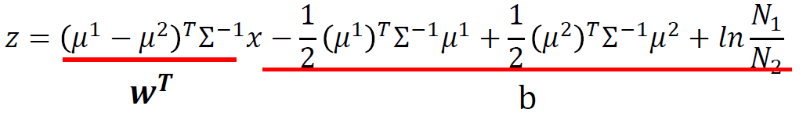
得到:
Logistic Regression
Step 1: Function Set
三步走第一步:定义一个函数集合
如果
,输出Class 1,否则输出Class 2。

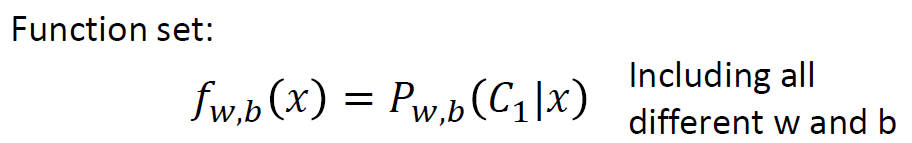
图像化表示:

这个模型叫做逻辑回归(Logistic Regression),我们和第二节课的线性回归做一个比较。

从Step1来看,逻辑回归的output是经过Sigmoid函数的,所以一定是0到1之间的数。而线性回归的output可以是任何数。
Step 2: Goodness of a Function
三步走第二步:判断一个函数的好坏
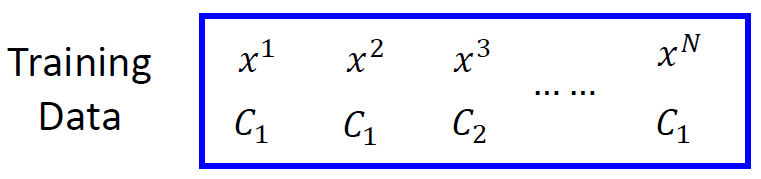
数据集每个对象分别对应一个类别(
),假设这些数据都是由后验概率
产生的。
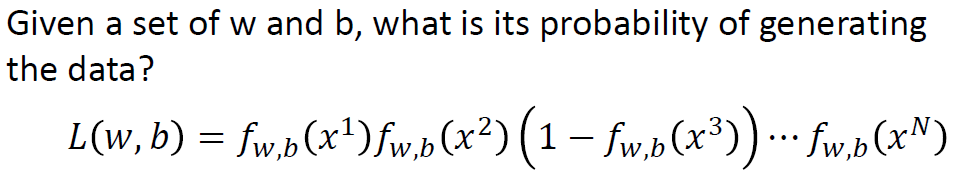
定义逻辑回归好坏的判定公式:给定一组
和
,就可以计算这组
下产生上图N个训练数据的概率。

可以最大化这个概率的
和
,记做
和
。
将训练集数字化:

并且将式1-2中求max通过取负自然对数转化为求min :

等价于把Likelyhood乘法变成加法,求最大值,也变成了求最小值。

图中蓝色下划线实际上代表的是两个伯努利分布(0-1分布,两点分布)的 cross entropy(交叉熵)
熵的概念本来是热力学的一个概念,描述物质的混乱程度。 在这里,我们用交叉熵的概念来描述两组不同概率数据分布的相似程度,越小越相似。(这个概念在机器学习中非常重要)

假设有两个分布
和
,如图中蓝色方框所示,这两个分布之间交叉熵的计算方式就是
;如果两个分布是一模一样的话,那计算出的交叉熵就是0。

从Step2来看,逻辑回归就是算Cross entropy。把function的输出和target(算出的function和真实的
)都看作是两个伯努利分布,所做的事情就是希望这两个分布越接近越好。线性回归就是简单的平方差。
Step 3:Find the best function
三步走第三步:找到最好的函数(Gradient Decent)
求极值,我们首先想到的是求微分

要求
对
的偏微分,只需要对右边的两项分别求偏微分。左边项利用链式法则展开偏微分的结果为

右边项偏微分的结果为

整理后就得到图中绿线的样子,化简得到结果。
现在
的更新取决于学习率
,
以及上图的紫色划线部分;紫色下划线部分直观上看就是真正的目标
与我们的function差距有多大。

在这里我们惊奇的发现,逻辑回归和线性回归的第三步骤的推导结果是一致的。
我们把线性回归和逻辑回归做一个小小的总结:
- 他们的函数选择集不一样
- 衡量函数好坏的算法不一样(crossentorpy 和 LMS)
- 但是梯度下降的微分函数的结构是一致的
损失函数可不可以用最小均方误差?


从上面的式子我们可以看出,不管是非常接近结果还是离结果很远,都存在使得偏微分为0的项。

- 如果是交叉熵,距离target越远,微分值就越大,就可以做到距离target越远,更新参数越快。
- Square Error 微分太小,根本不知道离目标点近还是远,十分容易卡住。
判别模型 v.s. 生成模型
逻辑回归的方法称为Discriminative(判别) 方法;上节课中用高斯来描述后验概率,称为 Generative(生成) 方法。它们的Function Set都是一样的:

如果是逻辑回归,就可以直接用梯度下降法找出
和
;如果是概率生成模型,像上篇那样求出
,协方差矩阵的逆,然后就能算出
和
。
用逻辑回归和概率生成模型找出来的
和
是不一样的。逻辑回归中我们没有做任何假设,就是求
和
,但是概率生成模型我们假设他的分布是高斯分布。那一组的结果更好呢?

上图是前节课神奇宝贝的例子,图中只考虑两个feature,很难区分。如果考虑七个feature,逻辑回归的效果好一些。
我们举一个有趣的例子:2个feature共13个data

人类来判断的话,不出意外肯定认为
是类别1。下面看一下朴素贝叶斯分类器(Naive Bayes)会有什么样的结果。

属于
的概率等于每个特征属于
概率的乘积。结果
是小于0.5的,朴素贝叶斯认为
属于Class2。
实际上训练集的数据量太小,但是对于 可能属于类别2这件事情,朴素贝叶斯分类器是有假设这种情况存在的,只不过我们sample的data比较少(机器脑补这种可能性==)。
所以生成模型做了脑补,而逻辑回归的判别模型没做。
生成方法的优势:

- 训练集数据量很小的情况;因为判别方法没有做任何假设,就是看着训练集来计算,训练集数量越来越大的时候,受到数据量的影响比较大,error会越小。而生成方法会自己脑补,受到数据量的影响比较小。
- label本身有噪声; 对于噪声数据有更好的鲁棒性(robust)。
- 先验和类相关的概率可以从不同的来源估计。比如语音识别,可能直观会认为现在的语音识别大都使用神经网络来进行处理,是判别方法。但事实上整个语音识别是Generative的方法,DNN只是其中的一块而已;因为还是需要算一个先验概率,就是某句话被说出来的概率,而估计某句话被说出来的概率不需要声音数据,只需要爬很多的句子,就能计算某句话出现的几率。
多分类(Multi-class Classification)
Softmax
假设有3个类别,每个都有自己的weight和bias

把
放到一个叫做Softmax的函数中,Softmax做的事情就是它们进行exponential(指数化),将exponential 的结果相加,再分别用 exponential 的结果除以相加的结果。原本
可以是任何值,但做完Softmax之后输出会被限制住,都介于0到1之间,并且和是1。
Softmax做事情就是对最大值进行强化。
输入x,属于类别1的几率是0.88,属于类别2的几率是0.12,属于类别3的几率是0。
Softmax的输出就是用来估计后验概率(Posterior Probability)。

用矩阵定义
可以避免Class之间相似的问题。
这里我们直接计算Cross Entropy。为了计算交叉熵, 也需要是个概率分布才可以。
逻辑回归的限制
逻辑回归无法解决异或问题。

考虑上图的例子,两个类别分布在两个对角线两端,用逻辑回归可以处理吗?

逻辑回归就是一条直线,无法把红蓝分边。
特征转换

特征转换的方法有很多,举例类别1转化为某个点到 (0,0)(0,0) 点的距离,类别2转化为某个点到 (1,1)(1,1) 点的距离。然后问题就转化右图,此时就可以处理了。但是实际中并不是总能轻易的找到好的特征转换的方法。我们让机器自己找转换的方法:把多个model连接起来。
级联逻辑回归模型

将多个逻辑回归接到一起,就可以进行特征转换。比如上图就用两个逻辑回归model对
来进行特征转换,然后对于
再用一个逻辑回归
来进行分类。


经过这样的转换,点就被处理为可以分开。

一个逻辑回归的input可以其他逻辑回归的output,这个逻辑回归的output也可以是其他逻辑回归的input。把每个逻辑回归称为一个 Neuron(神经元),把这些Neuron连接起来的网络,就叫做 Neural Network(神经网络)。
参考: