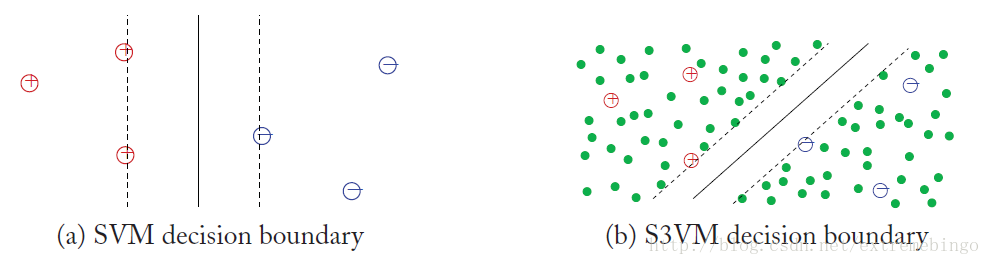
对于Semi-Supervised Support Vector Machines (S3VMs),即半监督支持向量机的直观理解是很简单的,如下图所示。在左图中,所有的数据都是有标签数据,所以可以使用SVM的最大化间隔来确定分离超平面。如果存在大量无标记的点,如右图所示,该如何确定分离超平面呢?如果还是采用左图所示的分离超平面,则分离超平面会将稠密的无标记数据切分成两个不同的类。但是根据图上的数据分布来看,该分离超平面很可能不是最优的,最优的分离超平面为图中实线所示,它就是由S3VMs得到的一个决策边界。上面简单介绍了S3VMs的直观理解,下面从理论层面详细介绍该算法。由于S3VMs是基于SVM的,所以先介绍SVM的部分理论知识。
Support Vector Machines(SVM)
假设存在两个类
y∈{−1,1}
,决策边界为
{x|wTx+b=0}
令
f(x)=wTx+b
,则决策边界为
f(x)=0
。对于样本
x
的预测值为
sign(f(x))
,它到决策边界距离的绝对值为
|f(x)|/||w||
。
决策边界将整个特征空间划分成两份,
f>0
和
f<0
。对于有标记样本
(x,y)
,带符号的距离为
yf(x)/||w||
如果分类正确,则带符号的距离为正,否则为负。对于线性可分的情况,可以将问题转化为下列带约束的优化问题
扫描二维码关注公众号,回复:
2774076 查看本文章

minw,b s.t. ||w||2yi(wTxi+b)≥1,i=1,...,l
对于线性不可分的情况,至少有一个点不能满足上述约束条件时,引入松弛因子
ξ
,将问题转为下述优化问题
minw,b,ξ s.t. ∑i=1lξi+λ||w||2yi(wTxi+b)≥1−ξi,i=1,...,lξi≥0(1)
考虑下列优化问题
minξ s.t. ξξ≥zξ≥0
可以很容易地看出,当
z≤0
时,目标值为0;当
z>0
时,目标值为
z
。因此,上述优化问题等同于
max(z,0)
式(1)中,约束条件可以写成
ξi≥1−yi(wTx+b)
,
ξ≥0
。令
zi=1−yi(wTx+b)
,将其代入(1)式,可将有约束的优化问题转化为无约束的优化问题,即
minw,b∑i=1lmax(1−yi(wTxi+b),0)+λ||w||2(2)
第一部分相当于损失函数(hinge loss)
c(x,y,f(x))=max(1−y(wTx+b),0)
第二部分相当于正则化
Ω(f)=||w||2
根据函数
yf(x)=y(wTx+b)
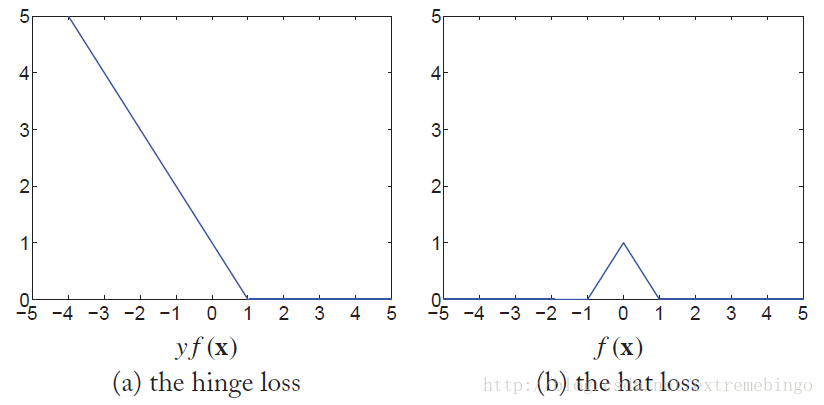
绘制的hinge loss如下图所示。对于完全可分的训练数据,
yf(x)≥1
。当
0≤yf(x)<1
时,样本分类正确,但是落在间隔边界与分离超平面之间。如果样本点分类错误,则
yf(x)<0
。
Semi-Supervised Support Vector Machines(S3VMs)
Semi-Supervised Support Vector Machines(S3VMs)最初被称为直推式支持向量机(Transductive Support Vector Machines(TSVMs)),因为它的理论是为了给无标记样本提供性能界限(理论保证)。但是由于学习到的函数
f
应用到了无标记的样本中,所以被称为半监督支持向量机S3VMs。
对于S3VMs的直观理解是使得有标记和无标记样本处于间隔边界之外。但是,对于无标记样本,我们无法得知其是否处于处于正确的分类。这里给出一种方法将无标记样本用到学习中。
对于样本
x
,它的预测值为
y^=sign(f(x))
,将该预测值假定为该样本的真实标签,则
x
的hinge损失函数为
c(x,y^,f(x))=max(1−y^(wTx+b),0)=max(1−sign(wTx+b)(wTx+b),0)=max(1−|wTx+b|,0)
该损失函数与hinge损失的不同之处在于它不需要样本真实的标签,而是由
f(x)
替代。该损失函数由上图中的右图所示。基于该损失函数的图形的形状,将其命名为hat loss。
虽然假设预测的分类结果都是正确的,但是基于hat loss,有些样本还是会存在惩罚。对于
f(x)≤−1
或
f(x)≥1
的样本,它们处在间隔边界之外,远离决策边界,是不存在惩罚的。但是对于
−1≤f(x)≤1
的样本,尤其是
f(x)≈0
的样本,它们在决策边界内,对于预测值
f(x)
是存在不确定性的,所以存在惩罚。
将无标记样本
{xj}l+uj=l+1
的hat loss加到SVM的损失函数(2)中,定义S3VMs的损失函数
minw,b∑i=1lmax(1−yi(wTxi+b),0)+λ1||w||2+λ2∑j=l+1l+umax(1−|wTxi+b|,0)(3)
由上式可以看出,S3VMs更希望无标记数据能够在决策边界的外边,也就是决策边界更希望出现在数据的低密度区域。此时,可以将hat loss看做正则化项
Ω(f)=λ1||w||2+λ2∑j=l+1l+umax(1−|wTxi+b|,0)
注意,有些时候,无标记数据的预测值只存在一个类,也就是无标记数据都被预测成了同一个类。为了纠正这种不平衡性,一种直接的想法就是限制预测值中各个类的比例。假设无标记数据的预测值中各个类的比例与有标记数据中各个类的比例相同,即
1u∑j=l+1l+uy^j=1l∑i=1lyi
因为
y^j=sign(f(xj))
不是一个连续函数,所以很难满足上述约束条件。因此放松该约束条件为
1u∑j=l+1l+uf(xj)=1l∑i=1lyi
该约束被称为类别的平衡约束。
所以,带类别平衡约束的S3VMs可以表示为
minw,bs.t.∑i=1lmax(1−yi(wTxi+b),0)+λ1||w||2+λ2∑j=l+1l+umax(1−|wTxi+b|,0)1u∑j=l+1l+uf(xj)=1l∑i=1lyi(4)
上述S3VMs的解是很难计算的,因为它的目标函数是非凸的。
参考文献