版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sinat_35406909/article/details/81842235
Support Vector Machines
1. Cost Function
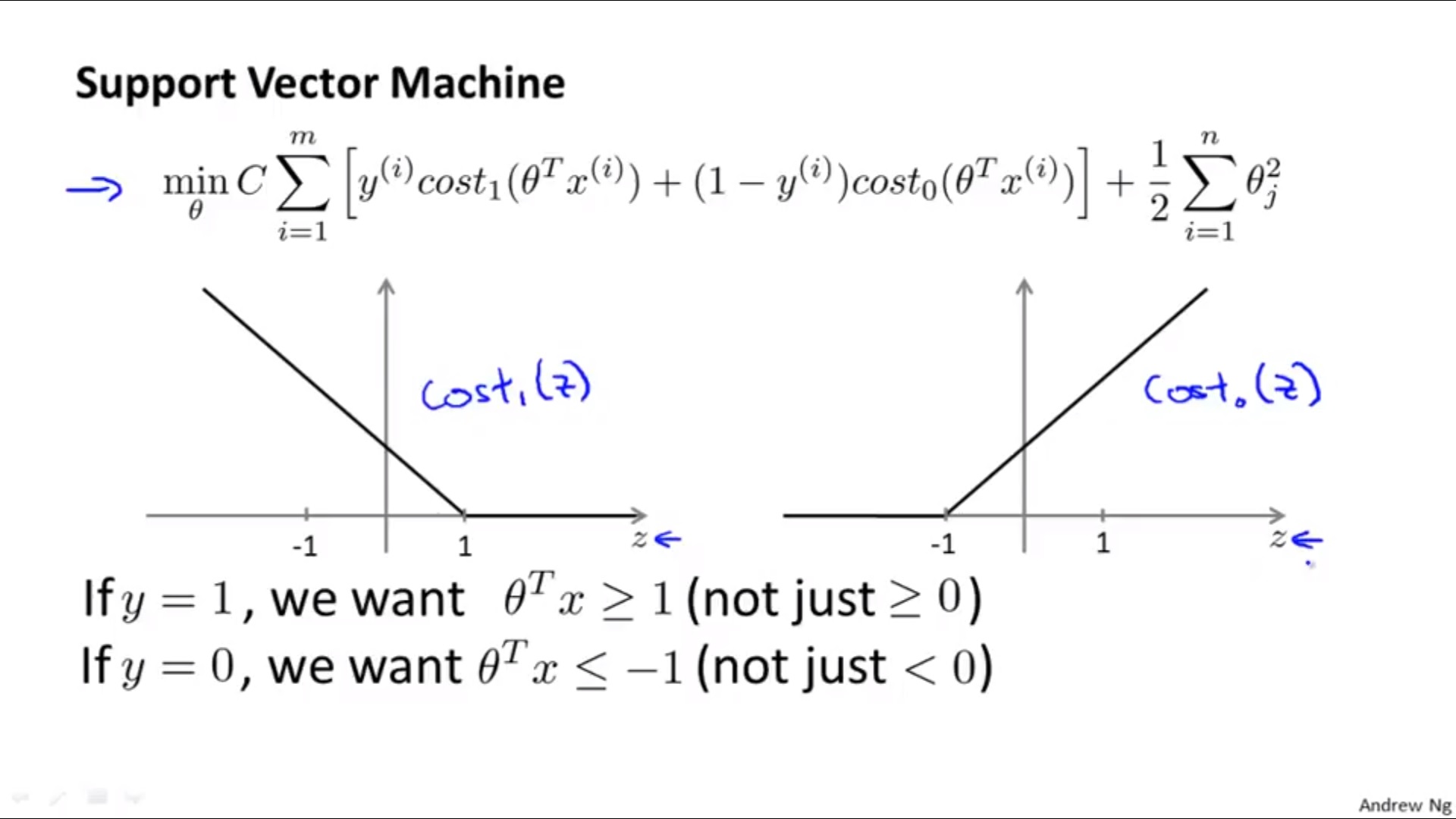
2. Hypothesis
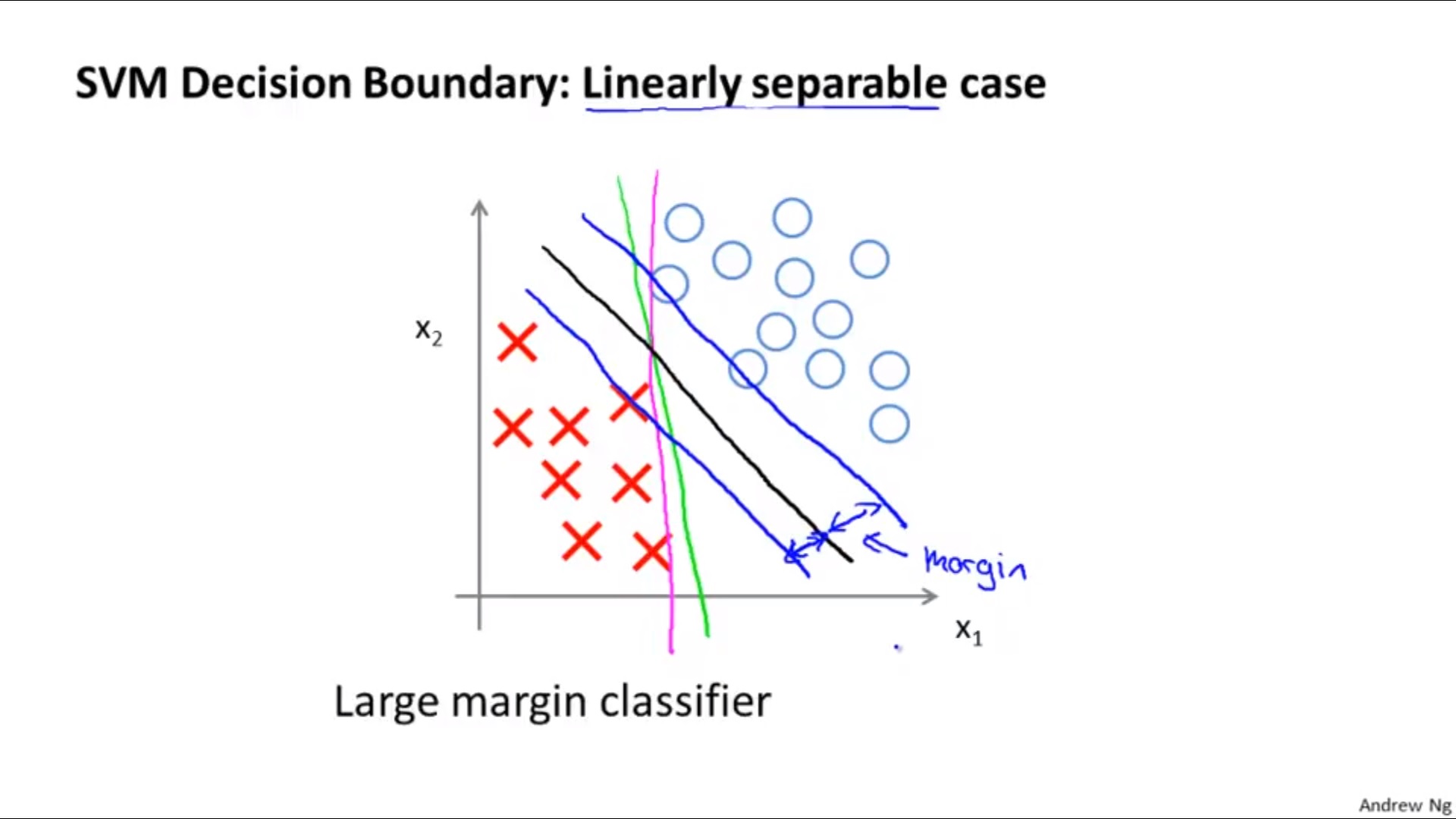
3. Margin of SVM
4. Kernels
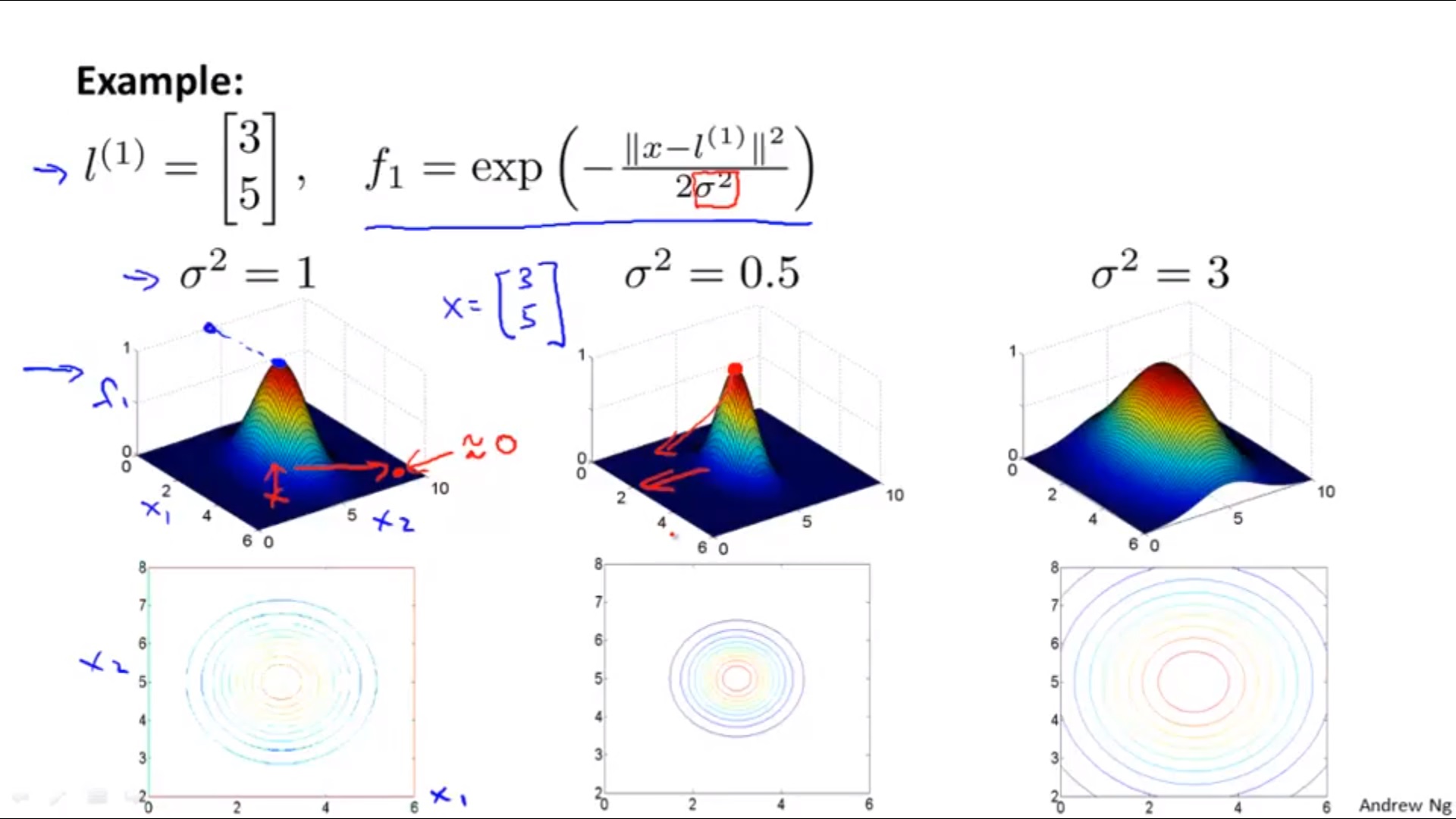
Define landmarks


Using
and
when making predictions..
5. How to Get Landmarks
One way is to use the first m training examples.
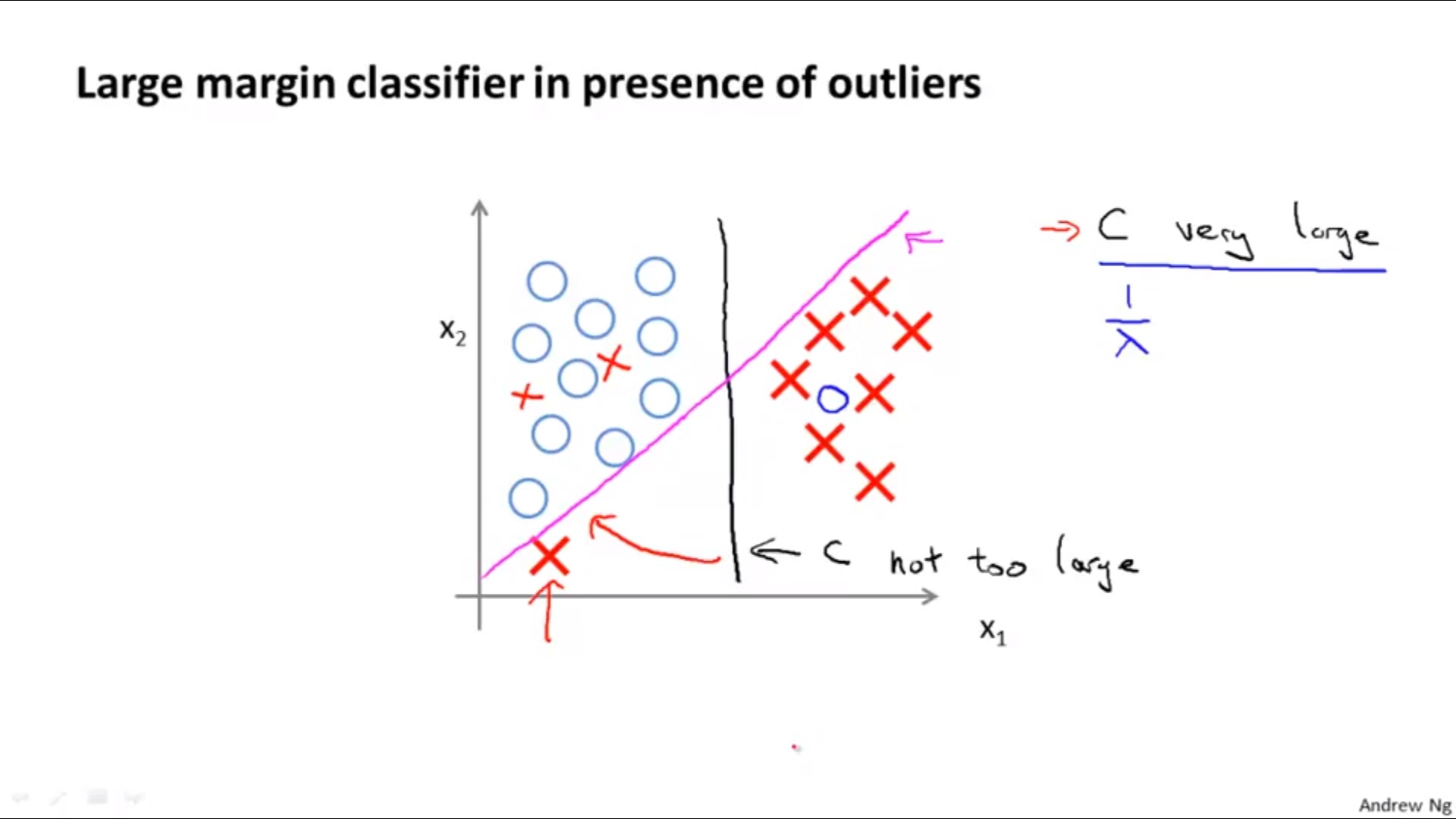
6. The Effects of Parameters in SVM
1) For
Large C : λ small, low bias, high variance
Small C : λ big, high bias, low variance
2) For
Large
: high bias, low variance
Small
: low bias, high variance
7. Choice of Kernal
Need to satisfy Mercer’s Theorem.
1) No kernal (Linear Kernal)
when n is large/ n is small && m is large
2) Gaussian Kernal
when n is small, m is intermediate
Need to use feature scaling before using!
3) Other Alternative Choices:
Polynomial Kernal, String Kernal, Chi-Square Kernal, Intersection Kernal…