Load Forecasting Using Support Vector Machines :A Study on EUNITE Competition 2001
本文通过使用SVM(SVR)来进行电力负荷预测,并引入时间序列概念来改善预测,同时发现温度(或其他类型的气候信息)在这种中期负荷预测可能没有好处。
1.数据分析
- 实验数据:
- 1997年至1998年,每半小时记录一次电力负荷需求。
- 1995年至1998年日平均气温。
- 1997年至1999年的假期。
goal:预测1999年1月电力负荷的最大日值
评价指标:平均绝对误差百分比(MAPE)
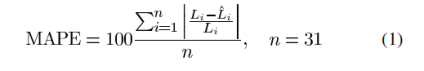
数据分析
1.负荷需求特性:(1)需求有一些季节性模式:冬季电力需求高,夏季需求低。这种模式意味着电力使用与不同季节的天气条件之间的关系;(2)每周都存在负载周期性。周末的负荷需求通常低于平日(周一至周五)。此外,周六的电力需求略高于周日。
2.气候影响:从1可以看出有季节性变化,从下图也也可以看出负荷需求与日温度之间负相关。但是这可能意味着1999年1月到来的温度和负荷的高度不确定性,从而增加了负荷预测的难度。(后面会介绍)

3.假期影响:在节假日,负荷通常会下降(本文由于数据限制,没有讨论假期的影响)
2.实验
方法:使用SVR
我们需要将有用的信息编码到数据条目中[即xi,…(2)]。此外,不同的数据编码影响建模方案的选择。
(1)特征选择:训练数据的每个组成部分称为特征(属性)。在这里,我们考虑应该包括什么样的信息。假设yi是第i天的负荷,一般情况下,我们在同一天或更早的时候合并信息作为特征xi。该功能有几种选择:
a)基本信息:日历属性:在第二-B节中,我们讨论了负载需求的每周周期性。此外,正如我们前面所指出的,假日的负荷需求低于非假日。因此,在训练条目中编码这些信息(平日和假期)可能有助于建模次问题。
b) 温度:另一个可能的特点是温度数据。这是一个相当简单的选择,因为负荷需求和温度之间有因果关系。在大多数短期负荷预测工作中,包括温度、风速、天空覆盖等在内的气象信息被用来预测负荷需求。然而,为了将温度包括在训练条目中,有一个困难:在这次比赛中,没有提供1999年1月的实际温度数据。换句话说,对于这种中期负荷预测,几周后的温度通常不能通过天气预报得到。如果我们想在我们的训练条目中编码温度,我们还需要预测或估计1999年1月的温度。然而,温度预测并不容易,特别是在如此有限的数据下。因此,使用温度将是一个两难的问题。
c)时间序列风格与否:除了工作日、假日和温度外,还有另一个我们认为编码为属性的信息:过去的负载需求。即在我们的模型中引入时间序列的概念…更精确地说,如果yi是预测的目标值,则向量xi包括几个先前的目标值yi-1,…,yi-△作为属性。在训练阶段,所有yi的都是已知的,但对于未来的预测yi1,…,yi-△,可以是以前预测的值。例如,在获得1999年1月1日的近似负荷后,如果△=7,它与1998年12月26日至31日的负荷一起用于预测1月2日的负荷。
-
数据分割:除了特征选择外,我们可以只考虑负载数据的子集,因为第二节也显示了季节模式。以往关于负荷预测的工作[1]、[2]、[7]提出基于不同季节数据的模型。这启发了我们对数据分割做一些分析。通常,人们用公式来模拟时间序列数据
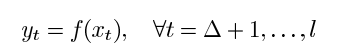
其中xt = (yt-1,yt-2,…,yt-△),and △ is the embedding dimension。但是,由于时间序列的特征可能会随着时间而改变,这种公式不适用于非平稳时间序列。对于这样一个时间交替的时间序列,我们可以考虑一个混合模型,其中
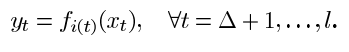
请注意,该公式允许在不同的时间内具有不同的特征功能。给定系列yt,t=1,l,任务是识别所有i(t)。我们称之为无监督分割,其中可以找到早期的工作,例如,[10]。换句话说,该方法将级数分解为不同的段,其中同一段中的点可以用相同的fi建模。最近,[11]提出了一个类似的框架使用SVR与不同的参数调谐。在任意时间点t,这些方法都考虑不同的权重,表示yt属于相应函数的概率。在任何给定的时间点t的权重之和总是固定为1。权重被迭代更新,直到一个权重接近一个,但其他权重接近于零。这意味着最终yt与一个特定的时间序列相关联。(无监督分割,这里不是特别懂)无监督数据分割对于时间序列预测(例如,[10])非常有用。如果训练数据与不同的时间序列相关联,最好只考虑数据段与最后一段的同一系列有关。现在比赛的目的是预测1999年1月的负荷需求,所以我们考虑只使用冬季段进行训练。在这里,如分析结果所示,我们选择1月至3月和10月至12月为我们的“冬季”时期。也就是说,“冬季”数据集将包含1997年和1998年的一半数据。另外,我们进一步提取1月和2月的数据,以形成另一个可能的训练数据集。这个数据集比“冬天”要小得多,它将更多地关注我们所关注的目标时期的负荷模式。
-
数据表示:在选择有用的信息和适当的数据段进行编码后,我们可以准备几个组合的训练数据集。在这些数据集中,我们为特定的第i天编码一个训练条目[即(2)中的xi]如下:

在这里,我们使用七个二进制编码日历信息,其中包括工作日、周末和假日,其中六个是工作日和周末,另一个是假日。六个二进制分别代表星期一到星期六,星期天表示为所有六个属性都设置为零。此外,一个数值属性用于归一化温度数据,如果温度是编码的。对于过去的负载,如果编码,我们对过去的七个日最大负载使用七个数字。使用“7”代替其他数字的原因是模型选择的复杂性。之后我们将详细阐述这一点。最后,对于这样一个条目,它的目标值[(2)中yi]被指定为第一天的最大负载需求。
实验:
对于基于时间序列的方法,我们分别提取1997年1月和1998年1月的数据条目,形成验证集,并对其模型进行评估。性能由这两个验证集上的平均错误率决定。对于非时间序列模型,我们简单地进行了十折交叉验证来推断参数。
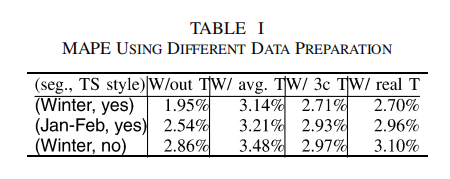
表I包含由不同的数据编码和分割产生的预测误差。在表中,第一列显示所使用的数据段,以及是否对过去的负载需求进行了编码。然后,接下来的四列表示有或没有温度(T)的预测:“AVG”。平均温度的T值,从其他三个城市的数据中得出的估计值的“3cT”,以及“再”对于1999年1月的实际温度(real T)。
图中,明显看出,不使用温度与使用温度的MAPE要低,前两行与第三行比较可以看出,使用时间序列序列模型的方法要比不使用时间序列的方法好。
同时,当我们计算最大负荷与每个月而不是整个两年温度之间的相关系数时,,我们发现它们是不同的(从-0.64到0.32)。这也表明在较短的周期内,载荷与温度之间的模糊相关性。
由于数据少,数据限制,导致只使用1,2月的数据要比使用冬季数据效果差。
综上,温度在这篇文章中对预测是没有多大用。
注:
局部模型。局部建模是一种简单的时间序列数据分析方案。固定时间序列数据局部模型也可以具有良好的性能[16]。它们通过找到时间序列的片段来产生预测,这些片段与点的片段非常相似,它们立即进行点的指向。是可以预测的。然后,预测通常是在这些相似的点段之后立即发生的元素的平均值。(不太懂)
本文使用1997-1998,2年的电力负荷数据(每半小时记录一次)来预测1999年的电力负荷的最大日值。通过SVM模型与局部模型和神经网络模型的对比,SVM效果较之,前两者要好,可以成功的用于负荷预测。在SVM的基础上,通过对实验时间序列模型与不实验时间序列对比,得出时间序列模型的效果明显比不使用时间模型的效果要好。同时,该文章中还通过对比不使用温度,和使用平均温度,使用附近3个城市的温度,真实的温度做比较,发现不使用温度的效果要比使用温度的效果要好,可以看出温度在这种中期负荷预测问题上可能没有用处。
重点:时间序列模型
本文缺点:
1.数据限制,导致像假期等因素都没考虑进来,并且文章一些实验结果的分析也都受到数据少的影响。
2.文章太老,SVR模型现在未必最好
