前言
这一章内容还是紧接着上一章的内容,在前面我们给大家介绍了线性回归,逻辑回归,神经网络算法,也对在设计学习系统之前该做什么准备和发现问题后该如何改进都做了详细的分析,在这一章将又给大家介绍一个新的算法,Support Vector Machines(支持向量机) ,我们也常简称为SVM,为什么要给大家介绍这个,首先这个算法在目前实际问题中运用很广泛,特别是在对复杂的非线性问题上有很好的运用,在这一章将详细给大家介绍。
最后,如果有理解不对的地方,希望大家不吝赐教,谢谢!
第十章 Support Vector Machines(支持向量机)
10.1 Optimization Objective(优化目标)
在前面我们有给大家介绍逻辑回归问题,现在我们将一步步地给大家介绍怎样由逻辑回归慢慢变成SVM的。在构造逻辑回归的目标函数时,我们引用了逻辑函数,即,在这里我们有令
,则
,我们画出g(z)关于z的图像,如图1所示。

图1 g(z)
在图1中,我们会发现如果我们希望结果y=1,则需要,即
>>0;如果我们希望结果y=0,则需要
,即
<<0。
在逻辑回归中,我们有,
,在这里,我们将
带入,则有
,我们分别画出当y=1和y=0的Cost(h(x),y)的图像,如图2所示,而我们SVM的图像就是由曲线变成折线,如图2中蓝色画出的直线。对于y=1的折线,我们记作
,而对于y=0的折线我们记作
。

图2 Cost(h(x),y)图像
对于有正则化项的完整CostFunction为,在这里我们只是把式子前面的负号放在了式子里面,我们用
,
代替,还有我们把
去掉,
是一个常数,去掉对最后得到的
并没有什么影响,比如J(
)=(
-5)^2+5,则当
=5时,J(
)取最小,如果我们把J(
)*10=10*(
-5)^2+5*10,这个时候依然是当
=5时,J(
)取最小值,所以我们去掉
不会影响最后的结果。还有我们对式子做一个变换在前面一项乘以个C,把第二项的
去掉,比如式子原先是
,我们通过改变
来惩罚B,同样的如果我们把式子变成CA+B,可以这样理解同时除以了
,即C=1/
,不过这个式子不是一直成立的,只是这里的C的大小变换和之前
的大小变换对式子的影响是相反的。所以我们SVM的CostFunction变成了
。
10.2 Large Margin Intuition(大间距的直观感受)
在前面已经给大家介绍了,怎样通过逻辑回归代价函数一步步演变为SVM的代价函数,对于这个新的,如果我们预测y=1,这个时候
>=1而不仅仅是
>=0了,对于预测结果y=0,这个时候
<=-1而不仅仅是
<0了,这就有了一个安全因子,那么这会对分类数据有什么好处了?下面会跟大家说到。在这里,我们对C选取一个比较大的值,大概C=100,000或者更大,这个时候对于
,我们就希望可以找到一个最优解使得
为0,这样可以给我们一个对于大间距的直观感受,如果我们希望第一项为0,当
=1时,我们只需要
>=1即可,当
=0时,我们只需要
<=-1即可。这个时候,问题就简化成了如下所示:
,s.t
>=1,
=1;
<=-1,
=0。
我们就会有很好的边界决策线对数据进行很好的分类,如图3所示,有两类数据样本,我们需要做出一条比较好的决策边界对此进行分类,而根据我们的SVM所选出的边界决策线将会是图3中倾斜线中的中间那条线,大家可以看出,这似乎是最好的一条边界,虽然边界线不止一条,我们还可以用图3所示的接近竖着的两条线把数据进行分类,可以看出这两条线都是比较勉强把两类进行分开,而我们SVM做出的一条线具有最大的margin(间距),如图3所示的margin,这样在对于预测新的数据时更具有一般性。

图3 large margin classifier
大家肯定会有疑惑,为什么SVM做出来的边界决策线就具有最大的margin,在后面我将会给大家做详细的解释。
对于如图4所示的两类数据,我们用SVM可以做出一条很好的决策线如图所示,这个时候的C是非常大的,当分类器中有异常值存在时,如图5所示,这个时候由于我们选取的C较大,所以我们的决策线会从黑色那条线变到粉色那条,为了更好的把数据分开,然而我们是不希望整个分类受到几个异常数据影响的,或者有时候两类数据中参合着其他类的少量数据,这个时候我们都希望可以不受这些异常数据的影响,所以我们可以取一个较小的C,我们所选的C比较小,即对于之前来讲就是比较大,而倾斜的边界决策线所选的C比较大,即
比较小,容易发生过度拟合,即更贴近数据,会受到异常数据的影响,而我们往往是不希望受到异常数据的影响的,即我们更想要的是竖着的边界决策线,所以我们需要C比较小。
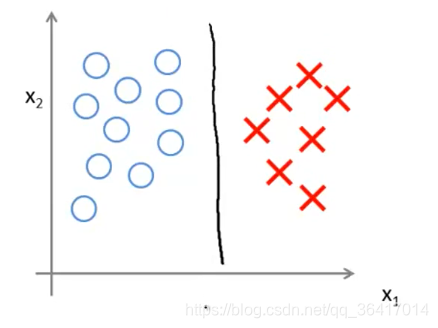
图4 没有异常数据的分类器
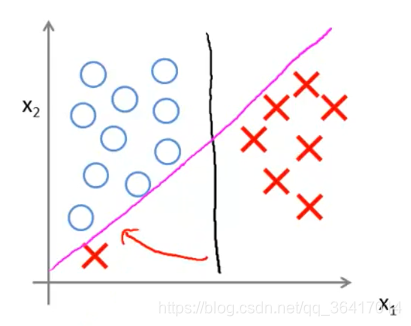
图5 分类器中有异常值
10.3 The mathematics behind large margin classification(大间距分类器背后的数学分析)
这一节将通过数学上的分析,给大家来解释为什么SVM会有前面所讲的large margin,这一节属于选学部分,可以不用了解,当然想了解更好。先给大家介绍下内积的含义,例如有两个向量,
,我们对u和v求两者的内积,即
,在这里还有一个范数的定义,即
为u的范数,为
,我们在图中标出u和v还有u和v的内积,如图6所示。

图6 u和v的内积
在图6中,u和v的内积即是v在u上的投影,即图中所示的p,所以我们的u和v的内积可以表示成,p即是v在u上的投影,是一个实数,有正负区分的,图6所示的p是大于0的,而如图7所示,p<0。即当u和v的夹角小于90度时,p>0;当u和v的夹角大于90度时,p<0。

图7 p<0
对于前面我们得到的新的代价函数,在前面我们也说明了,我们可以将其简化为
,当我们不考虑
时,且n=2,即只有
和
,这个时候就变成了
,而我们前面所要求的条件是
>=1,
=1;
<=-1,
=0
而是什么?不就是
和
的内积吗,所以我们在图中标出两者之间的关系,如图8所示,所以我们对于
,我们可以写成
,这个时候我们新的条件又诞生了:
,s.t
>=1,
=1;
<=-1,
=0。

图8
我们来用两个图来解释,为什么这会有大的间距,我们同样认为=0,其实对于
=0,我们的向量就是以原点为起点的。现在有如图9所示的数据,我们做出边界决策线,如图所示,我们有一条绿色的线勉强把两类数据分开,下面就来分析为什么我们的SVM不会选择这条线。对于
的方向是和我们的决策线成90度的,如图10所示,我们任意选择一个x1和x2,我们需要的条件是
>=1即
>=1,在这里我们会发现我们的
很小,所以我们需要
比较大,而我们需要的结果就是使
,即需要
较小,这样就相互矛盾了,同样x2也可以说明问题,那我们再看看SVM是怎样处理这个的。

图9 非大间距边界决策线

图10 选择任意x
如图11所示,对于SVM我们的选择是这样的一条绿色决策线,同样的我们做出,并任意选择x1和x2,分别做出
和
,我们会发现对于x1来讲,
比较大,所以我们希望
,则
可以比较小,这样正好也满足了
。所以SVM才会选择这条线,具有最大的间距。

图11 大间距的边界决策线
10.4 Kernels(内核)
在刚开始,我们也给大家说明了我们的SVM可以解决比较复杂的非线性分类问题,如图12所示,我们想要预测y=1,我们可能会要,在这里,我们用f1=x1,f2=x2,f3=x1x2,f4=x1^2,f5=x2^2...,这样就变成了
,我们是否有了不同的选择,通过选择f1,f2,f3,f4,f5...?下面会给大家一步步介绍是否可以由x派生出的特征f来进行计算。

图12 复杂的非线性分类问题
下面先给大家介绍内核的定义,如图13所示,我们有三个地标,我们对于所给的x,我们需要做的是计算x到这些地标的接近程度,用f1,f2,f3来表示。
,同样的,我们会有
...,这里的相似函数在术语上就是我们所说的核函数,其实这里的核函数实际是高斯核函数,后面我们会见到其他的核函数,所以这里就统称核函数了,我们常简写为
。下面就让我们看看这个核函数究竟是在计算什么,如果
,则
,如果x离
很远,则
,这样我们的l对应着f,而我们的x又对应着多个f。

图13 地标
下面给大家举一个例子来说明下对于相似函数到底在计算什么,例如,
,假设有两个特征变量x1,x2,我们做出f1关于x1和x2的图,如图14所示,当我们的
时,我们会有f1=1,而当我们的x离(3,5)比较远时,则我们的f1接近0,所以我们会发现当x越接近
时,f1的值就越接近1,即f1就是表达了x接近
的程度。

图14 f1
下面给大家讲的是,改变的值,我们会发现f1会有所改变,如图15所示,当
时,整个峰变窄了,从峰顶下降到0的速度更快了,而
则正好相反。

图15 不同的对f1的影响
在前面讲完了特征变量,那么我们会得到怎样的预测函数了?在这里,我们给定一个x,我们需要计算x到三个地标的f1,f2,f3然后代入到
,使其大于等于0,则预测结果为1,对于这个特殊的例子,我们假设得到了
,
,
,
,我们想要知道的是,如果我们现在有一堆数据,它是怎样预测它的结果是0还是1的,如图16所示,我们有一个数据x接近
处,所以
,而由于x距离
比较远,所以
,我们再看下那个式子
,带入
,
,
,
,我们会得到0.5>0所以我们预测结果为1,同样的,如果我们选取一个离
都较远的一个x,那么
,这个时候,我们得到的式子值为-0.5<0,所以我们预测结果为0,同理这些数据都以这样的计算方法得到他们的预测值,我们会发现最终的结果是如图17所示,即得到了图12中的边界决策线。

图16 举例说明预测函数的构造

图17 最终得到的边界决策线
在前面给大家讲解了核函数的意义后,我们对于训练集,我们该如何选取我们的地标
了?在这里我们选择
,对于给定的x,我们有
,所以
,在这里f0=1,我们任意的训练集
,我们都会有
,而其中会有
,所以我们每一个
将会有对应的
,而其中
。最后我们根据核函数,我们会得到新的假设和代价函数分别是:对于x,我们计算新的特征
,当我们需要预测结果是y=1时,条件是
(
),而我们的
,在这里n=m。
前面关于SVM的基本思想和提出了核函数的方法给大家也介绍完了,在前面章节,我们有给大家提到高偏差和高方差问题,对于SVM我们有两个参数需要注意下,一个就是C,还有一个就是核函数中的,C我们在前面也介绍了就是
,所以当C很大时,即
较小,为低偏差高方差;当C很小时,即
较大,为高偏差低方差。而对于我们的
,在前面也对其进行了分析,当
较大时,f过于平缓,所以是高偏差低方差;而当
较小时,f过于陡峭,所以是高方差低偏差。
10.5 使用SVM
前面给大家介绍了那么多关于SVM从构造到最终定型的方方面面,下面给大家总结下该如何使用一个SVM,其实对于SVM的模型选择,我们都有现成的软件包(例如liblinear,libsvm...)来进行选择出合适的,所以我们的问题就是选择出合适的C和核函数,对于核函数我们也给大家介绍了一种高斯核函数,就是所谓的相似核函数,当然还有我们最初的
,这也叫做线性核函数。那么我们该如何对两者进行选择了?对于高斯核函数,一般是解决比较复杂的非线性问题的,而且要求有大量的数据,所以当我们的m很大时,而特征数n较少时,我们一般选择高斯核函数,而当m较少时,n又很大时,我们则选择线性核函数。
对于高斯核函数,我还想说一点,对于式子中的
,我们令v=x-l,则即是求
,而
,假设我们对于预测房子价格问题,x1是房子的大小,则x1的取值会比较大,所以
也会比较大,而如果x2为房间的数量,则x2的取值会比较小,所以我们的
也会比较小,导致最后的值主要依赖于
,所以我们在计算核函数前,我们需要对特征进行比例变换,这个我们在前面章节也有所介绍,在这里具体就不再解释了。
对于内核的选择,其实并不是相似内核就可以对任意的问题进行很好的分类,我们还有其他的内核可以选择,比如,或者
等等。
我们在前面给大家介绍的都是两类的分类器,关于有两种以上的类别问题,我们的SVM也有对应的软件包,另外,训练
K SVMs,我们需要输出结果y=i(i=1,2,..,K),分别会得到,选择
最大的为第i类。
以上则是这一章的所有内容,内容比较多,很多可能还没有解释清楚,因为我也是刚接触SVM,在后面等我有了进一步的学习和认识,我会进行纠正和补充。