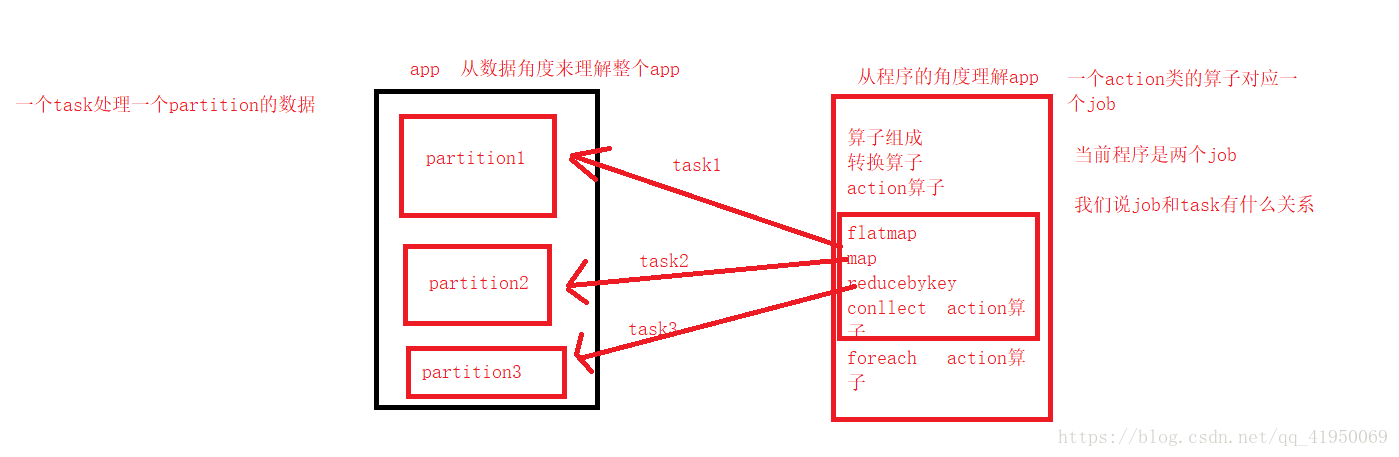
1.task、job、partition之间的关系
1.1一个task处理一个partition的数据
1.2partition的数量是根据一次任务需要处理的hdfs上的block的数量决定的
1.3一个action类算子对应一个job
1.4一个job处理一个或多个partition的数据,所以一个job对应多个partition
关系图如下:
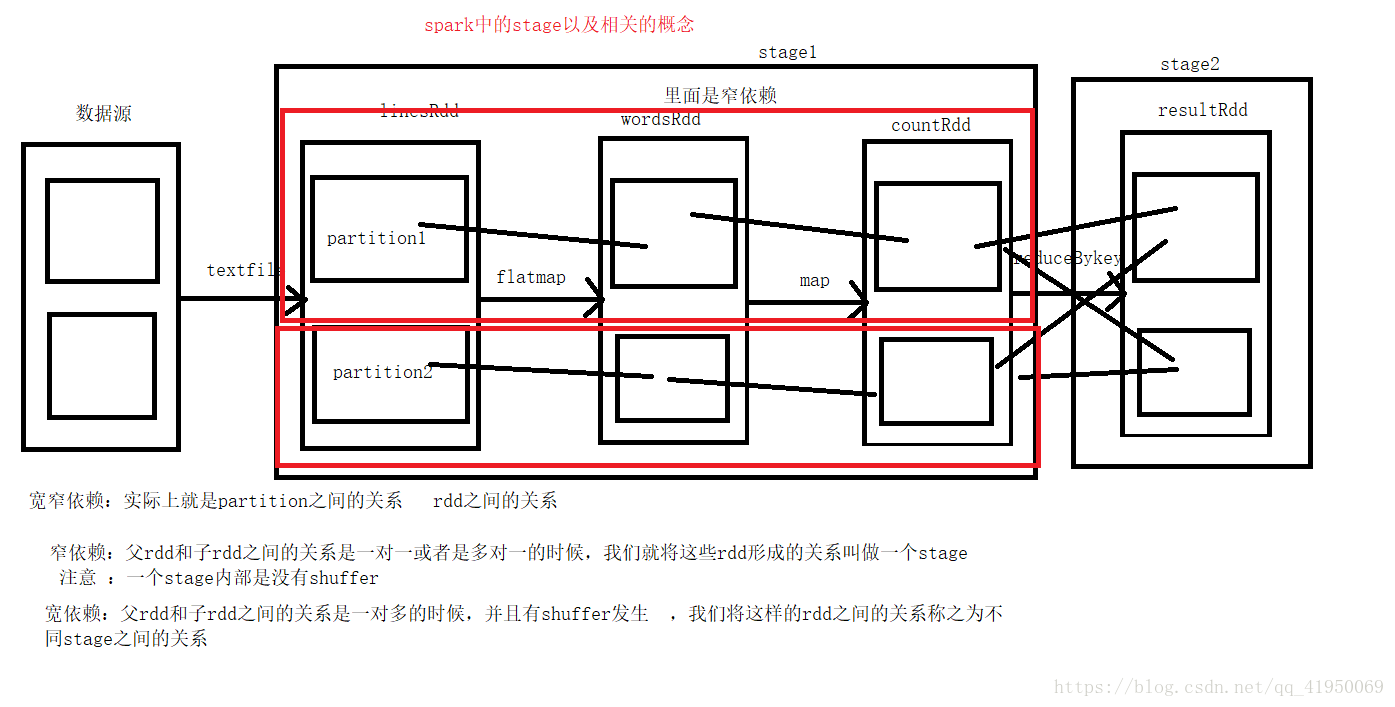
2.宽窄依赖
宽窄依赖实际上就是partition之间的关系或rdd之间有没有落地的shuffer,没有落地磁盘
2.1窄依赖:父rdd和子rdd之间的关系是一对一或者是多对一的时候,我们 就将这些rdd形成的关系叫做stage
注意:一个stage内部是没有shuffer的
2.2宽依赖:父rdd和子rdd之间的关系是一对多的时候,并且有shuffer发生,数据落地到磁盘,我们将这样rdd之间的关系称之为不同stage之间的关系
2.3stage内部全是窄依赖,两个stage之间的关系是宽依赖,而且肯定有shuffer。
关系图如下:
3.spark任务调度:
执行任务的逻辑流程称之为Dag有向无环图
首先程序根据stage的划分,将整个业务形成一个Dag有向无环图,发送给dagscheduler
然后dag调度器(dagscheduler)接收到有向无环图之后对图里的宽窄依赖进行stage的划分,之后将stage(一个stage相当于一个task,一个job拆分成一组的stage)切分成taskSet发送到taskscheduler第二个调度器
然后taskscheduler将taskSet拆分成一个一个task,一个一个的发送到work中进行
worker接收到task之后将task转换成一个一个的线程进行执行,一个task一个线程执行
所有的程序都是在worker中的executor中的线程池里执行的
容错机制:当一个task执行失败之后,一共有15次执行的机会,如果还没有结果,会执行另一个容错机制:再开启一个task执行也叫推测执行默认开启(数据量大了不建议开启)
4.其他知识:
take()提取结果的一部分,参数为int类型
sortByKey(false)是倒序