一、spark任务调度知识点
1、Spark中的一些专业术语
1.1、任务相关
Application:用户写的应用程序(DriverProgram +ExecutorProgram)。
Job:一个action类算子触发的操作。
stage:一组任务,例如:map task。
task:(thread)在集群运行时,最小的执行单元。
1.2、资源相关
Mstaer:资源管理主节点。
Worker:资源管理从节点。
Executor:执行任务的进程。
ThreadPool:线程池(存在于Executor进程中)
2、RDD的依赖关系
2.1、窄依赖
父RDD与子RDD,partition之间的关系是一对一,这种依赖关系不会有shuffle(父RDD不知道有几个子RDD,但是子RDD一定知道他的父RDD)
2.2、宽依赖
父RDD与子RDD是一对多,一般都会导致shuffle。默认情况下,groupByKey返回的RDD的分区数与父RDD是一致的,如果再使用groupByKey的时候,传入一个int类型的值,此时返回的RDD的分区数就是这个值
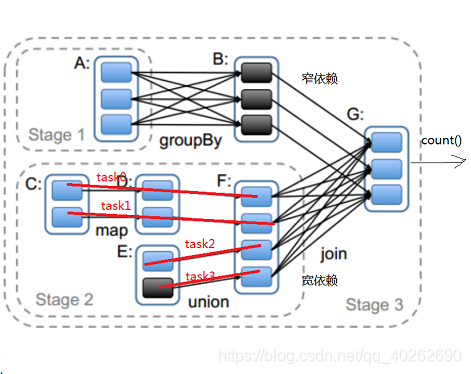
2.3、宽窄依赖的作用
将一个个job切割成一个个stage,stage与stage之间是宽依赖,stage内部是窄依赖
2.4、为什么我们需要把job切割成stage?
答:把job切割成stage之后,stage内部就可以很容易的划分出一个个的task任务(用一条线把task内部有关联的子RDD与父RDD串联起来),然后就可把task放到管道中运行了。
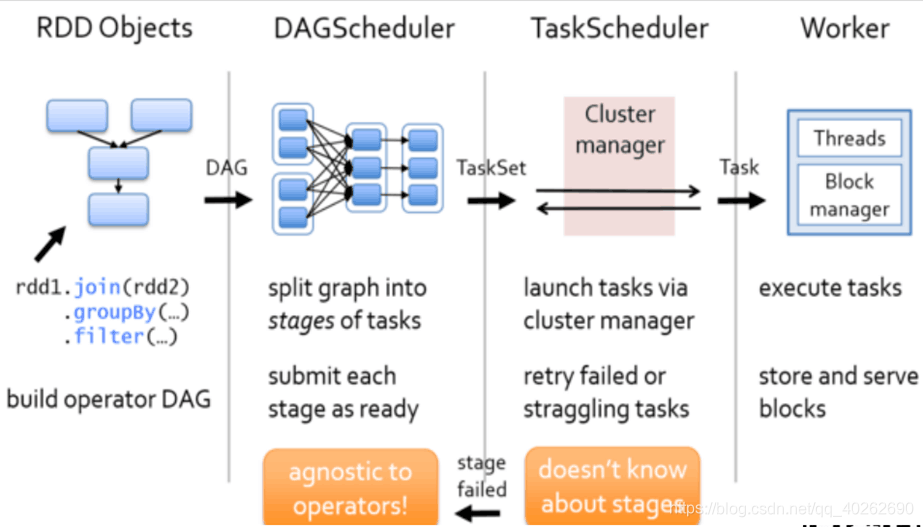
二、任务调度流程
1、根据RDD的宽窄依赖关系将DAG有向无环图切割成一个个stage将切割的stage封装到TaskSet=stage 然后将一个个taskSet给taskSccheduler
2、taskScheduler拿到task以后,会遍历整个集合,拿到每一个task然后去调用HDFS上的某一个方法,然后获取数据的位置,依据数据的位置来分发task到worker节点的Executor进程中的线程池中执行
3、taskSchedule会实时跟踪每一个task执行情况,若执行失败ts会重试提交task,不会无休止重试,默认重试3次
4、重试3次仍然失败,(每次重试提交的stage,已经成功执行 的不会再次分发到Executor进程执行,只是重试失败的)那么task所在的stage就失败了,此时taskSchedule向DAGScheduler汇报,当前stage失败,此时DS会重试提交stage(straggling task)
5、如果DS重试4次仍然失败,那么stage所在的job就失败了,job失败是不会进行重试的

三、问题思考
3.1、stage中的每一个task(管道计算模式)会在什么时候落地磁盘?
1、如果stage后面是跟的是action类算子
saveAsText:将每一个管道计算结果写入到指定目录。
collect:将每一个管道计算结果拉回到Driver端内存中。
count:将每一个管道计算结果,统计记录数,返回给Driver。
2、如果stage后面是跟的是stage
在shuffle write阶段会写磁盘。(为什么在shuffle write阶段写入磁盘?防止reduce task拉取文件失败,拉取失败后可以直接在磁盘再次拉取shuffle后的数据)
3.2、Spark在计算的过程中,是不是特别消耗内存?
不是。Spark是在管道中计算的,而管道中不是特别耗内存。即使有很多管道同时进行,也不是特别耗内存。
3.3、什么样的场景最耗内存?
使用控制类算子的时候耗内存,特别是使用cache时最耗内存。
3.4、如果管道中有cache逻辑,他是如何缓存数据的?
有cache时,会在一个task运行成功时(遇到action类算子时),将这个task的运行结果缓存到内存中。
3.5、RDD(弹性分布式数据集),为什么他不存储数据还叫数据集?
虽然RDD不具备存储数据的能力,但是他具备操作数据的能力。
3.6、如果有1T数据,单机运行需要30分钟,但是使用Saprk计算需要两个小时(4node),为什么?
1、发生了计算倾斜。大量数据给少量的task计算。少量数据却分配了大量的task。
2、开启了推测执行机制。
解决方案:关闭推测执行,后期更新如何解决数据倾斜
3.7、掉队(挣扎)任务?
大部分任务成功,部分未执行成功
TS遇到挣扎任务,他会重试,此时TS会重新提交一个挣扎的task一模一样的task到集群中运行,挣扎的task不会被kill掉,让他俩在集群中比赛执行,谁先执行完毕,以谁的结果为准(推测执行机制)
推测执行的标准 100ms 1.5 75%
可通过修改配置信息配置
spark.task.maxFailures TS重试失败的次数 默认3次
spark.stage.maxConsecutiveAttempts DS重试的次数 默认4次
spark.speculation.interval 100ms 推测执行机制
spark.speculation.multiplier 1.5
含义:每隔100ms计算一次集群是否有挣扎的任务,100task,76task执行完毕,24个未执行完毕,计算这24个task的已经执行时间的中位数,然后将中位数*1.5=时间,拿到这个最终计算出来的时间,查看哪一些task超时,那么,此时的task就是挣扎的task
当所有的task的75%以上全部执行完毕,那么才会每隔100ms计算
3.8、对于ETL(数据清洗流程)类型的数据,开启推测执行、重试机制,对于最终的执行结果会不会有影响?
有影响,最终数据库中会有重复数据。
解决方案:
1、关闭各种推测、重试机制。
2、设置一张事务表。