\quad \quad RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
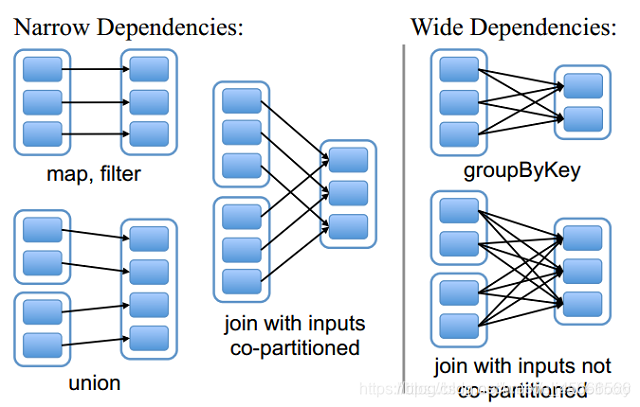
1、窄依赖(narrow dependency)
- 窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用 (一对一的关系)
- 总结·:窄依赖我们形象的比喻为独生子女
- 常见算子:map flatmap filter union sample 等等
2、宽依赖(wide dependency)
- 宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition (一对多的关系)
- 总结:宽依赖我们形象的比喻为超生
- 常见算子:groupByKey reduceByKey sortByKey join 等等
如何区分宽窄依赖?
- 窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
- 宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
易出错之处:子RDD的一个分区依赖多个父RDD是宽依赖还是窄依赖?
- 不能确定,也就是宽窄依赖的划分依据是父RDD的一个分区是否被子RDD的多个分区所依赖,是,就是宽依赖,或者从shuffle的角度去判断,有shuffle就是宽依赖
3、作用
窄依赖:
- Spark可以并行计算
- 如果有一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可,不需要重新计算整个任务,提高容错。
宽依赖:
-
是划分Stage的依据
-
容错(针对复杂业务逻辑,当执行到宽依赖的时候,进行适当的cache,担心任务异常结束,数据重跑)