目录

目标
- 深入理解 RDD 的内在逻辑
- 能够使用 RDD 的算子
- 理解 RDD 算子的 Shuffle 和缓存
- 理解 RDD 整体的使用流程
- 理解 RDD 的调度原理
- 理解 Spark 中常见的分布式变量共享方式
一、 深入 RDD
目标
-
深入理解 RDD 的内在逻辑, 以及 RDD 的内部属性(RDD 由什么组成)
1.1. 案例
数据
190.217.63.59 - - [01/Nov/2017:00:00:15 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
76.114.21.96 - - [01/Nov/2017:00:00:31 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//tricolor.entravision.com/sacramento/escucha-en-vivo/&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
206.126.121.204 - - [01/Nov/2017:00:00:46 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//zone.msn.com/gameplayer/gameplayer.aspx%3Fgame%3Dfamilyfeud&cat=internet-portal HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
154.121.8.18 - - [01/Nov/2017:00:01:01 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fwww.google.dz%2Fsearch&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 5.1; rv:11.0) Gecko/20100101 Firefox/11.0"
190.238.37.217 - - [01/Nov/2017:00:01:17 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
147.147.163.182 - - [01/Nov/2017:00:01:31 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fs-usweb.dotomi.com%2Frenderer%2FdelPublishersCookies.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:56.0) Gecko/20100101 Firefox/56.0"
200.78.93.132 - - [01/Nov/2017:00:01:45 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.facebook.com/login/device-based/regular/login/&cat=social-networking HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
24.200.173.170 - - [01/Nov/2017:00:01:59 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/glade.js&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
189.252.185.4 - - [01/Nov/2017:00:02:15 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fwww.google.cm%2Fblank.html&cat=internet-portal HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; rv:34.0) Gecko/20100101 Firefox/34.0"
190.90.22.125 - - [01/Nov/2017:00:02:29 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//www.raicesdeeuropa.com/grandes-obras-de-los-principales-escritores-nacidos-durante-el-siglo-xix/&cat=unknown HTTP/1.1" 200 134 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
181.64.62.158 - - [01/Nov/2017:00:02:45 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//bancaporinternet.interbank.com.pe/Warhol/redireccionaInicioLogueo&cat=financial-service HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36"
122.54.153.240 - - [01/Nov/2017:00:03:00 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
181.64.62.158 - - [01/Nov/2017:00:03:16 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.google.com.pe/&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
190.236.239.8 - - [01/Nov/2017:00:03:33 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.google.com.pe/search%3Frlz%3D1C2AOHY_esPE760PE760%26source%3Dhp%26ei%3DUw_5WeGVA4TjmAHO8aCgDw%26q%3Dfb%26oq%3Dfb%26gs_l%3Dpsy-ab.3..0i131k1j0l4j0i131k1l2j0l3.1767.1916.0.2135.2.2.0.0.0.0.144.269.0j2.2.0....0...1.1.64.psy-ab..0.2.267....0.pWGbpZy6zwg%26safe%3Dhigh&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"需求
- 给定一个网站的访问记录, 俗称 Access log
- 计算其中出现的独立 IP, 以及其访问的次数


针对这个小案例,提出互相关联但是又方向不同的五个问题
1. 假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理?
放在集群中, 利用集群多台计算机来并行处理
2.如何放在集群中运行?
简单来讲, 并行计算就是同时使用多个计算资源解决一个问题, 有如下四个要点
- 要解决的问题必须可以分解为多个可以并发计算的部分
- 每个部分要可以在不同处理器上被同时执行
- 需要一个共享内存的机制
- 需要一个总体上的协作机制来进行调度
3.如果放在集群中的话, 可能要对整个计算任务进行分解, 如何分解?
- 对于 HDFS 中的文件, 是分为不同的 Block 的
- 在进行计算的时候, 就可以按照 Block 来划分, 每一个 Block 对应一个不同的计算单元
RDD 并没有真实的存放数据, 数据是从 HDFS 中读取的, 在计算的过程中读取即可
RDD至少是需要可以 分片 的, 因为HDFS中的文件就是分片的,RDD分片的意义在于表示对源数据集每个分片的计算,RDD可以分片也意味着 可以并行计算
4.移动数据不如移动计算是一个基础的优化, 如何做到?
每一个计算单元需要记录其存储单元的位置, 尽量调度过去
5. 在集群中运行, 需要很多节点之间配合, 出错的概率也更高, 出错了怎么办?
RDD1 → RDD2 → RDD3 这个过程中, RDD2 出错了, 有两种办法可以解决
- 缓存 RDD2 的数据, 直接恢复 RDD2, 类似 HDFS 的备份机制
- 记录 RDD2 的依赖关系, 通过其父级的 RDD 来恢复 RDD2, 这种方式会少很多数据的交互和保存
如何通过父级 RDD 来恢复?
- 记录 RDD2 的父亲是 RDD1 (Dependencies, )
- 记录 RDD2 的计算函数, 例如记录
RDD2 = RDD1.map(…),map(…)就是计算函数 - 当 RDD2 计算出错的时候, 可以通过父级 RDD 和计算函数来恢复 RDD2
6.假如任务特别复杂, 流程特别长, 有很多 RDD 之间有依赖关系, 如何优化
上面提到了可以使用依赖关系来进行容错, 但是如果依赖关系特别长的时候, 这种方式其实也比较低效, 这个时候就应该使用另外一种方式, 也就是记录数据集的状态
在 Spark 中有两个手段可以做到
- 缓存
- Checkpoint
1.2. 再谈 RDD
目标
-
理解 RDD 为什么会出现
-
理解 RDD 的主要特点
-
理解 RDD 的五大属性
1.2.1. RDD 为什么会出现?
在 RDD 出现之前, 当时 MapReduce 是比较主流的, 而 MapReduce 如何执行迭代计算的任务呢?
多个 MapReduce 任务之间没有基于内存的数据 共享方式, 只能通过磁盘来进行共享
这种方式明显比较低效
RDD 如何解决迭代计算非常低效的问题呢?
在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度,
1.2.2. RDD
RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
RDD 的算子大致分为两类:
- Transformation 转换操作, 例如
mapflatMapfilter等 - Action 动作操作, 例如
reducecollectshow等
执行 RDD 的时候, 在执行到转换操作的时候, 并不会立刻执行, 直到遇见了 Action 操作, 才会触发真正的执行, 这个特点叫做 惰性求值
RDD 可以分区
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
RDD 是只读的
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改.
- RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
- 如果因为支持修改, 而必须保存数据的话, 怎么容错?
- 如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
RDD 是可以容错的
RDD 的容错有两种方式
- 保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
- 直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
1.2.3. 什么叫做弹性分布式数据集
分布式
RDD 支持分区, 可以运行在集群中
弹性
- RDD 支持高效的容错
- RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
- RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
- RDD 也可以缓存起来, 相当于存储具体数据
总结: RDD 的五大属性
首先整理一下上面所提到的 RDD 所要实现的功能:
- RDD 有分区
- RDD 要可以通过依赖关系和计算函数进行容错
- RDD 要针对数据本地性进行优化
- RDD 支持 MapReduce 形式的计算, 所以要能够对数据进行 Shuffled
对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
-
Partition List分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目 -
Compute Function为了实现容错, 需要记录 RDD 之间转换所执行的计算函数 -
RDD DependenciesRDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算 -
Partitioner为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区

二、RDD 的算子
目标
-
理解 RDD 的算子分类, 以及其特性
-
理解常见算子的使用
分类
RDD 中的算子从功能上分为两大类
-
Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
-
Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
-
针对基础类型(例如 String)处理的普通算子
-
针对
Key-Value数据处理的byKey算子 -
针对数字类型数据处理的计算算子
特点
-
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
-
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
2.1. Transformations 算子
| Transformation function |
解释 |
|---|---|
|
|
作用
签名 参数
注意点
|
|
|
作用
调用 参数
注意点
|
|
|
作用
|
|
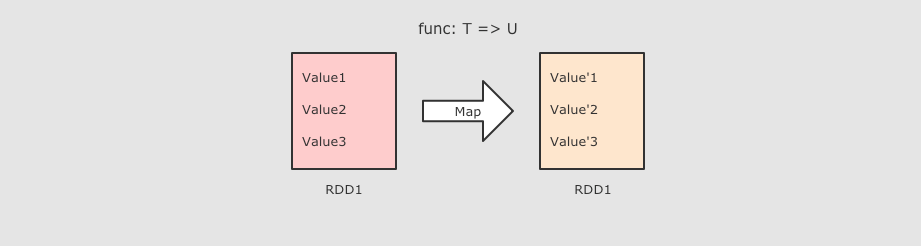
RDD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换 |
|
|
和 mapPartitions 类似, 只是在函数中增加了分区的 Index |
|
|
作用
|
|
|
作用
参数
|
|
|
|
|
|
作用
|
|
|
(RDD[T], RDD[T]) ⇒ RDD[T] 差集, 可以设置分区数 |
|
|
作用
注意点
|
|
|
作
调用
参数
注意点
|
|
|
作用
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
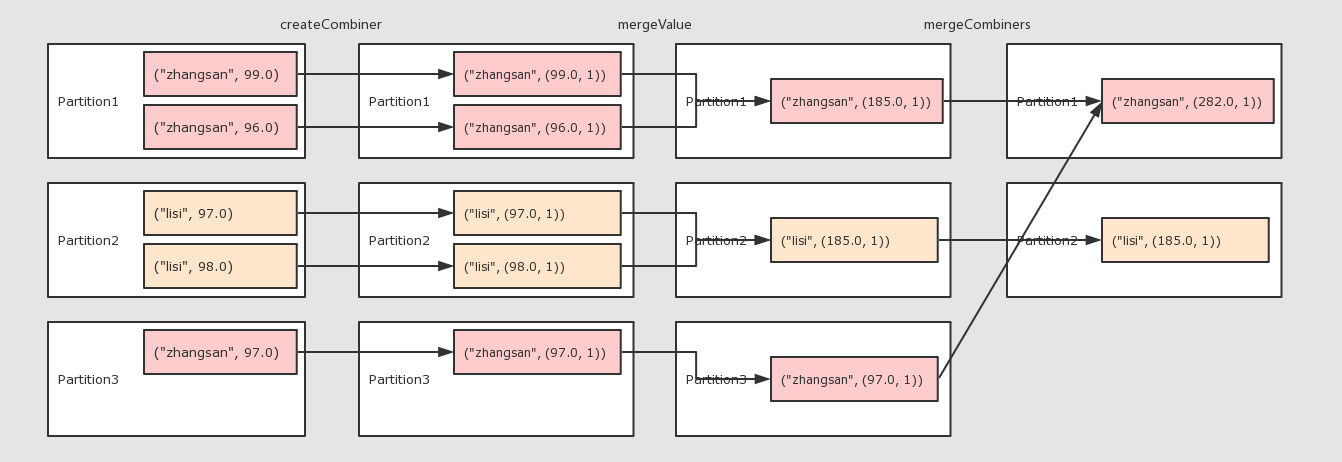
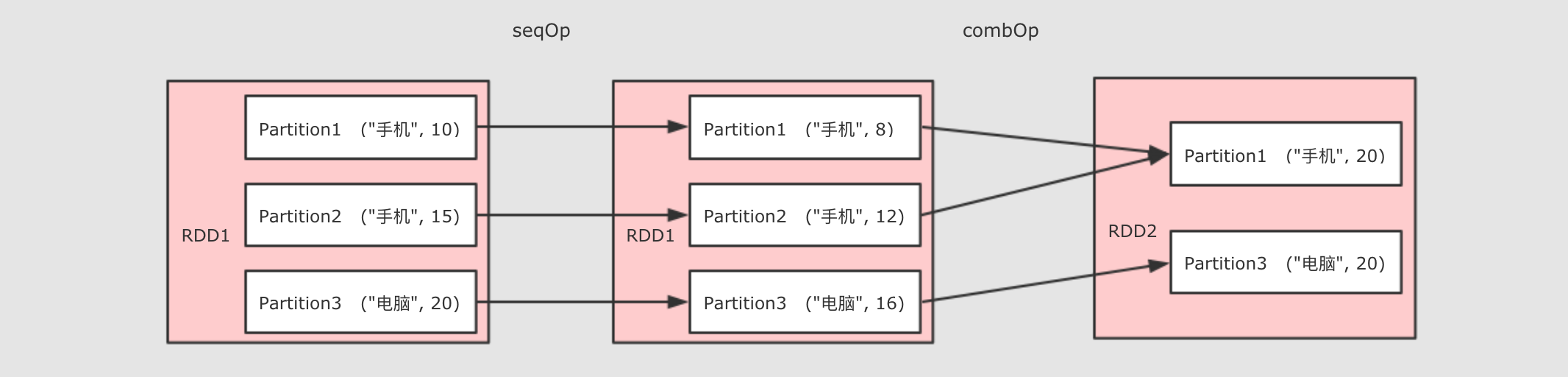
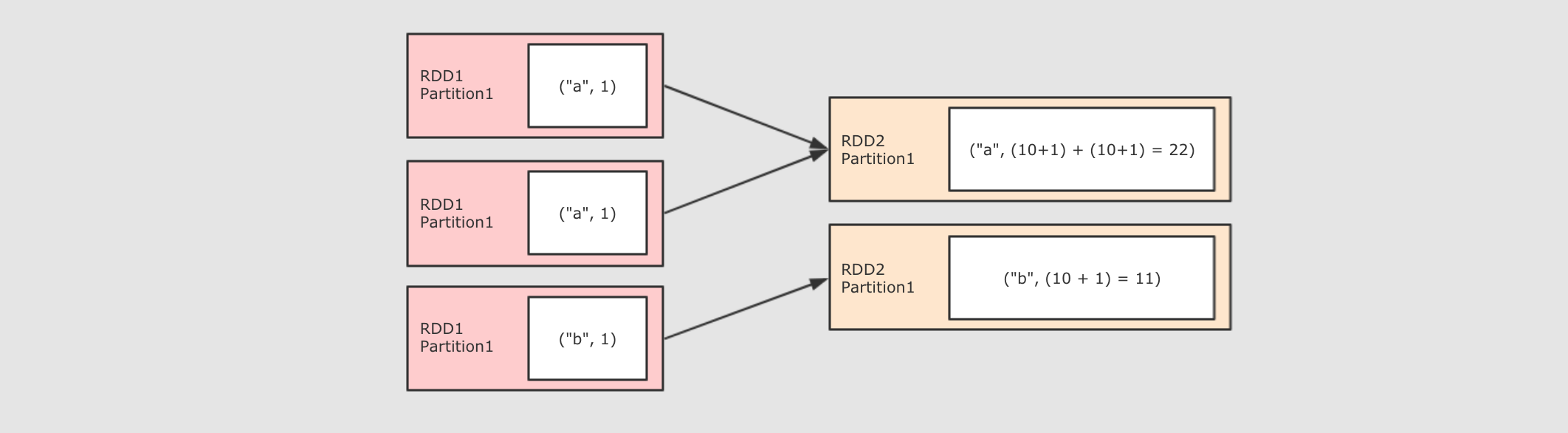
注意点 * 为什么需要两个函数? aggregateByKey 运行将一个 和 reduceByKey 的区别:
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
作用
调用
参数
注意点
|
|
|
(RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成两个 RDD 的笛卡尔积 |
|
|
作用
调用
参数
注意点
|
|
|
使用用传入的 partitioner 重新分区, 如果和当前分区函数相同, 则忽略操作 |
|
|
减少分区数 作用
调用
参数
注意点
|
|
|
重新分区 |
|
|
重新分区的同时升序排序, 在 |




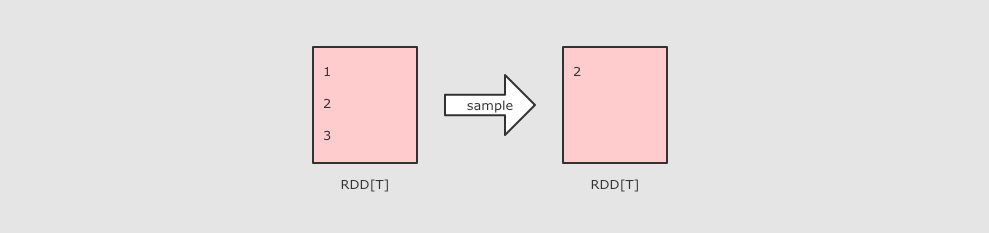

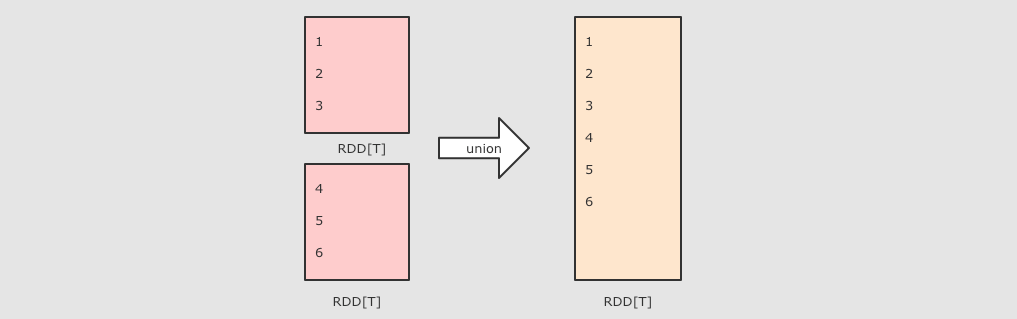

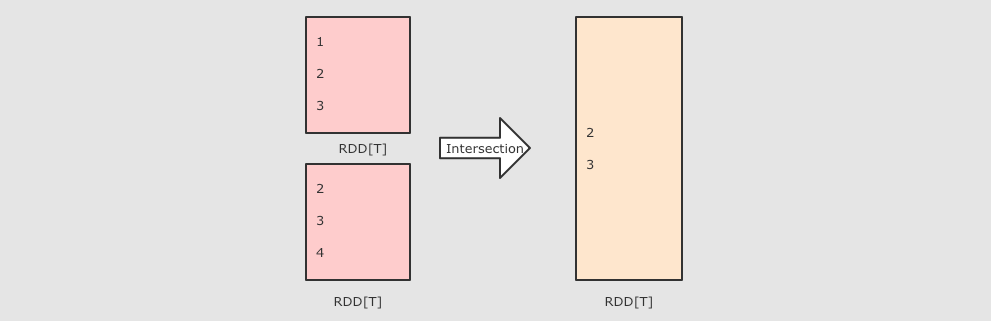





分区操作的算子补充:

2.2. Action 算子
| Action function | 解释 |
|---|---|
|
|
作用
调用
注意点
|
|
|
以数组的形式返回数据集中所有元素 |
|
|
返回元素个数 |
|
|
返回第一个元素 |
|
|
返回前 N 个元素 |
|
|
类似于 sample, 区别在这是一个Action, 直接返回结果 |
|
|
指定初始值和计算函数, 折叠聚合整个数据集 |
|
|
将结果存入 path 对应的文件中 |
|
|
将结果存入 path 对应的 Sequence 文件中 |
|
|
作用
注意点
|
|
|
遍历每一个元素 |
总结
RDD 的算子大部分都会生成一些专用的 RDD
map,flatMap,filter等算子会生成MapPartitionsRDD
coalesce,repartition等算子会生成CoalescedRDD常见的 RDD 有两种类型
转换型的 RDD, Transformation
动作型的 RDD, Action
常见的 Transformation 类型的 RDD
map
flatMap
filter
groupBy
reduceByKey
常见的 Action 类型的 RDD
collect
countByKey
reduce
2.3. RDD 对不同类型数据的支持
目标
- 理解 RDD 对 Key-Value 类型的数据是有专门支持的
- 理解 RDD 对数字类型也有专门的支持
一般情况下 RDD 要处理的数据有三类
- 字符串
- 键值对
- 数字型
RDD 的算子设计对这三类不同的数据分别都有支持
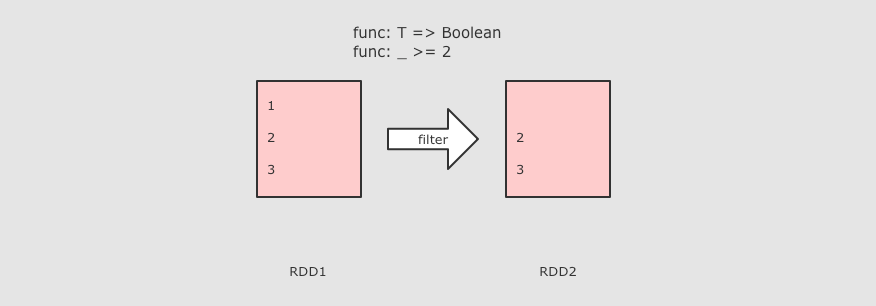
- 对于以字符串为代表的基本数据类型是比较基础的一些的操作, 诸如 map, flatMap, filter 等基础的算子
- 对于键值对类型的数据, 有额外的支持, 诸如 reduceByKey, groupByKey 等 byKey 的算子
- 同样对于数字型的数据也有额外的支持, 诸如 max, min 等
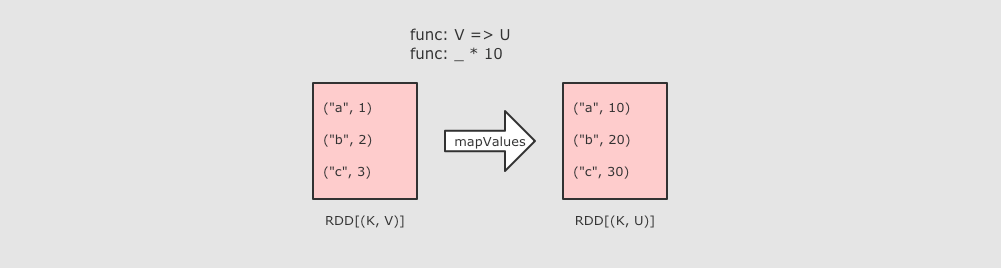
RDD 对键值对数据的额外支持
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为
RDD[(K, V)]RDD 对键值对的额外支持是通过隐式支持来完成的, 一个
RDD[(K, V)], 可以被隐式转换为一个PairRDDFunctions对象, 从而调用其中的方法.
既然对键值对的支持是通过
PairRDDFunctions提供的, 那么从PairRDDFunctions中就可以看到这些支持有什么
类别 算子 聚合操作
reduceByKey
foldByKey
combineByKey分组操作
cogroup
groupByKey连接操作
join
leftOuterJoin
rightOuterJoin排序操作
sortBy
sortByKeyAction
countByKey
take
collect
RDD 对数字型数据的额外支持
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作
算子 含义
count个数
mean均值
sum求和
max最大值
min最小值
variance方差
sampleVariance从采样中计算方差
stdev标准差
sampleStdev采样的标准差
val rdd = sc.parallelize(Seq(1, 2, 3)) // 结果: 3 println(rdd.max())
2.4. 阶段练习和总结
导读
-
通过本节, 希望大家能够理解 RDD 的一般使用步骤
// 1. 创建 SparkContext
val conf = new SparkConf().setMaster("local[6]").setAppName("stage_practice1")
val sc = new SparkContext(conf)
// 2. 创建 RDD
val rdd1 = sc.textFile("dataset/BeijingPM20100101_20151231_noheader.csv")
// 3. 处理 RDD
val rdd2 = rdd1.map { item =>
val fields = item.split(",")
((fields(1), fields(2)), fields(6))
}
val rdd3 = rdd2.filter { item => !item._2.equalsIgnoreCase("NA") }
val rdd4 = rdd3.map { item => (item._1, item._2.toInt) }
val rdd5 = rdd4.reduceByKey { (curr, agg) => curr + agg }
val rdd6 = rdd5.sortByKey(ascending = false)
// 4. 行动, 得到结果
println(rdd6.first())通过上述代码可以看到, 其实 RDD 的整体使用步骤如下
三、 RDD 的 Shuffle 和分区
目标
- RDD 的分区操作
- Shuffle 的原理
分区的作用
RDD 使用分区来分布式并行处理数据, 并且要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 读取数据的时候, 会尽量的在物理上靠近数据源, 比如说在读取 Cassandra 或者 HDFS 中数据的时候, 会尽量的保持 RDD 的分区和数据源的分区数, 分区模式等一 一对应
分区和 Shuffle 的关系
分区的主要作用是用来实现并行计算, 本质上和 Shuffle 没什么关系, 但是往往在进行数据处理的时候, 例如
reduceByKey,groupByKey等聚合操作, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区, 于是理解分区才能理解 Shuffle 的根本原理
Spark 中的 Shuffle 操作的特点
只有 Key-Value 型的 RDD 才会有 Shuffle 操作, 例如 RDD[(K, V)], 但是有一个特例, 就是 repartition 算子可以对任何数据类型 Shuffle
-
早期版本 Spark 的 Shuffle 算法是
Hash base shuffle, 后来改为Sort base shuffle, 更适合大吞吐量的场景
3.1. RDD 的分区操作
查看分区数
scala> sc.parallelize(1 to 100).count res0: Long = 100
之所以会有 8 个 Tasks, 是因为在启动的时候指定的命令是
spark-shell --master local[8], 这样会生成 1 个 Executors, 这个 Executors 有 8 个 Cores, 所以默认会有 8 个 Tasks, 每个 Cores 对应一个分区, 每个分区对应一个 Tasks, 可以通过rdd.partitions.size来查看分区数量
同时也可以通过 spark-shell 的 WebUI 来查看 Executors 的情况
默认的分区数量是和 Cores 的数量有关的, 也可以通过如下三种方式修改或者重新指定分区数量
创建 RDD 时指定分区数
scala> val rdd1 = sc.parallelize(1 to 100, 6)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> rdd1.partitions.size
res1: Int = 6
scala> val rdd2 = sc.textFile("hdfs:///dataset/wordcount.txt", 6)
rdd2: org.apache.spark.rdd.RDD[String] = hdfs:///dataset/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> rdd2.partitions.size
res2: Int = 7rdd1 是通过本地集合创建的, 创建的时候通过第二个参数指定了分区数量. rdd2 是通过读取 HDFS 中文件创建的, 同样通过第二个参数指定了分区数, 因为是从 HDFS 中读取文件, 所以最终的分区数是由 Hadoop 的 InputFormat 来指定的, 所以比指定的分区数大了一个.
通过 coalesce 算子指定
coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]numPartitions
- 新生成的 RDD 的分区数
shuffle
- 是否 Shuffle
scala> val source = sc.parallelize(1 to 100, 6) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> source.partitions.size res0: Int = 6 scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false) noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26 scala> noShuffleRdd.toDebugString res1: String = (6) CoalescedRDD[1] at coalesce at <console>:26 [] | ParallelCollectionRDD[0] at parallelize at <console>:24 [] scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false) noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26 scala> shuffleRdd.toDebugString res3: String = (8) MapPartitionsRDD[5] at coalesce at <console>:26 [] | CoalescedRDD[4] at coalesce at <console>:26 [] | ShuffledRDD[3] at coalesce at <console>:26 [] +-(6) MapPartitionsRDD[2] at coalesce at <console>:26 [] | ParallelCollectionRDD[0] at parallelize at <console>:24 [] scala> noShuffleRdd.partitions.size res4: Int = 6 scala> shuffleRdd.partitions.size res5: Int = 8
* 如果 shuffle参数指定为false, 运行计划中确实没有ShuffledRDD, 没有shuffled这个过程* 如果 shuffle参数指定为true, 运行计划中有一个ShuffledRDD, 有一个明确的显式的shuffled过程* 如果 shuffle参数指定为false却增加了分区数, 分区数并不会发生改变, 这是因为增加分区是一个宽依赖, 没有shuffled过程无法做到, 后续会详细解释宽依赖的概念
通过 repartition 算子指定
repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
repartition算子本质上就是coalesce(numPartitions, shuffle = true)
scala> val source = sc.parallelize(1 to 100, 6) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24 scala> source.partitions.size res7: Int = 6 scala> source.repartition(100).partitions.size res8: Int = 100 scala> source.repartition(1).partitions.size res9: Int = 1
repartition算子无论是增加还是减少分区都是有效的, 因为本质上repartition会通过shuffle操作把数据分发给新的 RDD 的不同的分区, 只有shuffle操作才可能做到增大分区数, 默认情况下, 分区函数是RoundRobin(轮询), 如果希望改变分区函数, 也就是数据分布的方式, 可以通过自定义分区函数来实现
3.2. RDD 的 Shuffle 是什么
val sourceRdd = sc.textFile("hdfs://node01:9020/dataset/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
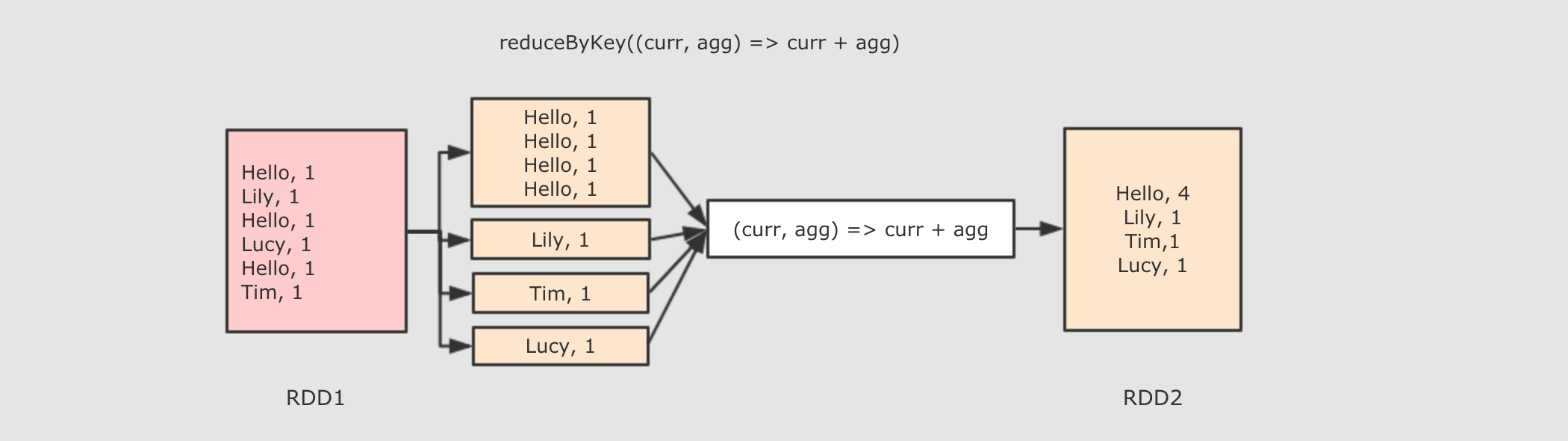
val result = aggCountRdd.collectreduceByKey 这个算子本质上就是先按照 Key 分组, 后对每一组数据进行 reduce, 所面临的挑战就是 Key 相同的所有数据可能分布在不同的 Partition 分区中, 甚至可能在不同的节点中, 但是它们必须被共同计算.
为了让来自相同 Key 的所有数据都在
reduceByKey的同一个reduce中处理, 需要执行一个all-to-all的操作, 需要在不同的节点(不同的分区)之间拷贝数据, 必须跨分区聚集相同 Key 的所有数据, 这个过程叫做Shuffle.
3.3. RDD 的 Shuffle 原理(简单介绍)
Spark 的 Shuffle 发展大致有两个阶段: Hash base shuffle 和 Sort base shuffle(具体来说分为 三个阶段)
Hash base shuffle
大致的原理是分桶, 假设 Reducer 的个数为 R, 那么每个 Mapper 有 R 个桶, 按照 Key 的 Hash 将数据映射到不同的桶中, Reduce 找到每一个 Mapper 中对应自己的桶拉取数据.
假设 Mapper 的个数为 M, 整个集群的文件数量是 M * R, 如果有 1,000 个 Mapper 和 Reducer, 则会生成 1,000,000 个文件, 这个量非常大了.
过多的文件会导致文件系统打开过多的文件描述符, 占用系统资源. 所以这种方式并不适合大规模数据的处理, 只适合中等规模和小规模的数据处理, 在 Spark 1.2 版本中废弃了这种方式.
Sort base shuffle
对于 Sort base shuffle 来说, 每个 Map 侧的分区只有一个输出文件, Reduce 侧的 Task 来拉取, 大致流程如下
-
Map 侧将数据全部放入一个叫做 AppendOnlyMap 的组件中, 同时可以在这个特殊的数据结构中做聚合操作
-
然后通过一个类似于 MergeSort 的排序算法 TimSort 对 AppendOnlyMap 底层的 Array 排序先按照 Partition ID 排序, 后按照 Key 的 HashCode 排序
-
最终每个 Map Task 生成一个 输出文件, Reduce Task 来拉取自己对应的数据
从上面可以得到结论, Sort base shuffle 确实可以大幅度减少所产生的中间文件, 从而能够更好的应对大吞吐量的场景, 在 Spark 1.2 以后, 已经默认采用这种方式.
四、 缓存
概要
-
缓存的意义
-
缓存相关的 API
-
缓存级别以及最佳实践
4.1. 缓存的意义
使用缓存的原因 - 多次使用 RDD
需求: 在日志文件中找到访问次数最少的 IP 和访问次数最多的 IP
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string") val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt") .map(item => (item.split(" ")(0), 1)) .filter(item => StringUtils.isNotBlank(item._1)) .reduceByKey((curr, agg) => curr + agg) val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first() val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()
这是一个 Shuffle 操作, Shuffle 操作会在集群内进行数据拷贝
在上述代码中, 多次使用到了
interimRDD, 导致文件读取两次, 计算两次, 有没有什么办法增进上述代码的性能?

使用缓存的原因 - 容错
当在计算 RDD3 的时候如果出错了, 会怎么进行容错?
会再次计算 RDD1 和 RDD2 的整个链条, 假设 RDD1 和 RDD2 是通过比较昂贵的操作得来的, 有没有什么办法减少这种开销?
上述两个问题的解决方案其实都是
缓存, 除此之外, 使用缓存的理由还有很多, 但是总结一句, 就是缓存能够帮助开发者在进行一些昂贵操作后, 将其结果保存下来, 以便下次使用无需再次执行, 缓存能够显著的提升性能.所以, 缓存适合在一个 RDD 需要重复多次利用, 并且还不是特别大的情况下使用, 例如迭代计算等场景.
4.2. 缓存相关的 API
可以使用 cache 方法进行缓存
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string") val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt") .map(item => (item.split(" ")(0), 1)) .filter(item => StringUtils.isNotBlank(item._1)) .reduceByKey((curr, agg) => curr + agg) .cache() val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first() val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()方法签名如下
cache(): this.type = persist()cache 方法其实是
persist方法的一个别名

也可以使用 persist 方法进行缓存
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string") val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt") .map(item => (item.split(" ")(0), 1)) .filter(item => StringUtils.isNotBlank(item._1)) .reduceByKey((curr, agg) => curr + agg) .persist(StorageLevel.MEMORY_ONLY) val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first() val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()方法签名如下
persist(): this.type persist(newLevel: StorageLevel): this.type
persist方法其实有两种形式,persist()是persist(newLevel: StorageLevel)的一个别名,persist(newLevel: StorageLevel)能够指定缓存的级别
缓存其实是一种空间换时间的做法, 会占用额外的存储资源, 如何清理?
根据缓存级别的不同, 缓存存储的位置也不同, 但是使用 unpersist 可以指定删除 RDD 对应的缓存信息, 并指定缓存级别为 NONE
4.3. 缓存级别
其实如何缓存是一个技术活, 有很多细节需要思考, 如下
-
是否使用磁盘缓存?
-
是否使用内存缓存?
-
是否使用堆外内存?
-
缓存前是否先序列化?
-
是否需要有副本?
如果要回答这些信息的话, 可以先查看一下 RDD 的缓存级别对象
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist()
println(interimRDD.getStorageLevel)
sc.stop()打印出来的对象是 StorageLevel, 其中有如下几个构造参数
根据这几个参数的不同, StorageLevel 有如下几个枚举对象
| 缓存级别 | userDisk 是否使用磁盘 |
useMemory 是否使用内存 |
useOffHeap 是否使用堆外内存 |
deserialized 是否以反序列化形式存储 |
replication 副本数 |
|---|---|---|---|---|---|
|
|
false |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
2 |
|
|
false |
true |
false |
true |
1 |
|
|
false |
true |
false |
true |
2 |
|
|
false |
true |
false |
false |
1 |
|
|
false |
true |
false |
false |
2 |
|
|
true |
true |
false |
true |
1 |
|
|
true |
true |
false |
true |
2 |
|
|
true |
true |
false |
false |
1 |
|
|
true |
true |
false |
false |
2 |
|
|
true |
true |
true |
false |
1 |
如何选择分区级别
Spark 的存储级别的选择,核心问题是在 memory 内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择:
如果您的 RDD 适合于默认存储级别(MEMORY_ONLY)。这是 CPU 效率最高的选项,允许 RDD 上的操作尽可能快地运行.
如果不是,试着使用 MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用 Spark 来服务 来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在 RDD 上运行任务,而无需等待重新计算一个丢失的分区.
五、 Checkpoint
目标
-
Checkpoint 的作用
-
Checkpoint 的使用
5.1. Checkpoint 的作用
Checkpoint 的主要作用是斩断 RDD 的依赖链, 并且将数据存储在可靠的存储引擎中, 例如支持分布式存储和副本机制的 HDFS.
Checkpoint 的方式
-
可靠的 将数据存储在可靠的存储引擎中, 例如 HDFS
-
本地的 将数据存储在本地
什么是斩断依赖链
斩断依赖链是一个非常重要的操作, 接下来以 HDFS 的 NameNode 的原理来举例说明
HDFS 的 NameNode 中主要职责就是维护两个文件, 一个叫做 edits, 另外一个叫做 fsimage. edits 中主要存放 EditLog, FsImage 保存了当前系统中所有目录和文件的信息. 这个 FsImage 其实就是一个 Checkpoint.
HDFS 的 NameNode 维护这两个文件的主要过程是, 首先, 会由 fsimage 文件记录当前系统某个时间点的完整数据, 自此之后的数据并不是时刻写入 fsimage, 而是将操作记录存储在 edits 文件中. 其次, 在一定的触发条件下, edits 会将自身合并进入 fsimage. 最后生成新的 fsimage 文件, edits 重置, 从新记录这次 fsimage 以后的操作日志.
如果不合并 edits 进入 fsimage 会怎样? 会导致 edits 中记录的日志过长, 容易出错.
所以当 Spark 的一个 Job 执行流程过长的时候, 也需要这样的一个斩断依赖链的过程, 使得接下来的计算轻装上阵.
Checkpoint 和 Cache 的区别
Cache 可以把 RDD 计算出来然后放在内存中, 但是 RDD 的依赖链(相当于 NameNode 中的 Edits 日志)是不能丢掉的, 因为这种缓存是不可靠的, 如果出现了一些错误(例如 Executor 宕机), 这个 RDD 的容错就只能通过回溯依赖链, 重放计算出来.
但是 Checkpoint 把结果保存在 HDFS 这类存储中, 就是可靠的了, 所以可以斩断依赖, 如果出错了, 则通过复制 HDFS 中的文件来实现容错.
区别主要在以下三点
-
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中
-
Checkpoint 可以斩断 RDD 的依赖链, 而 Persist 和 Cache 不行
-
因为 CheckpointRDD 没有向上的依赖链, 所以程序结束后依然存在, 不会被删除. 而 Cache 和 Persist 会在程序结束后立刻被清除.
5.2. 使用 Checkpoint
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
sc.setCheckpointDir("checkpoint")
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
interimRDD.checkpoint()
interimRDD.collect().foreach(println(_))
sc.stop()- 在使用 Checkpoint 之前需要先设置 Checkpoint 的存储路径, 而且如果任务在集群中运行的话, 这个路径必须是 HDFS 上的路径
| 一个小细节
|
六、Spark 底层逻辑
案例
因为要理解执行计划, 重点不在案例, 所以本节以一个非常简单的案例作为入门, 就是我们第一个案例 WordCount
val sc = ...
val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}")
println(strRDD.toDebugString)
strRDD.collect.foreach(item => println(item))整个案例的运行过程大致如下:
-
通过代码的运行, 生成对应的
RDD逻辑执行图 -
通过
Action操作, 根据逻辑执行图生成对应的物理执行图, 也就是Stage和Task -
将物理执行图运行在集群中
逻辑执行图
对于上面代码中的
reduceRDD如果使用toDebugString打印调试信息的话, 会显式如下内容(6) MapPartitionsRDD[4] at map at WordCount.scala:20 [] | ShuffledRDD[3] at reduceByKey at WordCount.scala:19 [] +-(6) MapPartitionsRDD[2] at map at WordCount.scala:18 [] | MapPartitionsRDD[1] at flatMap at WordCount.scala:17 [] | ParallelCollectionRDD[0] at parallelize at WordCount.scala:16 []根据这段内容, 大致能得到这样的一张逻辑执行图
其实 RDD 并没有什么严格的逻辑执行图和物理执行图的概念, 这里也只是借用这个概念, 从而让整个 RDD 的原理可以解释, 好理解.
对于 RDD 的逻辑执行图, 起始于第一个入口 RDD 的创建, 结束于 Action 算子执行之前, 主要的过程就是生成一组互相有依赖关系的 RDD, 其并不会真的执行, 只是表示 RDD 之间的关系, 数据的流转过程.
物理执行图
当触发 Action 执行的时候, 这一组互相依赖的 RDD 要被处理, 所以要转化为可运行的物理执行图, 调度到集群中执行.
因为大部分 RDD 是不真正存放数据的, 只是数据从中流转, 所以, 不能直接在集群中运行 RDD, 要有一种 Pipeline 的思想, 需要将这组 RDD 转为 Stage 和 Task, 从而运行 Task, 优化整体执行速度.
以上的逻辑执行图会生成如下的物理执行图, 这一切发生在 Action 操作被执行时.
从上图可以总结如下几个点
-
在第一个
Stage中, 每一个这样的执行流程是一个Task, 也就是在同一个 Stage 中的所有 RDD 的对应分区, 在同一个 Task 中执行 -
Stage 的划分是由 Shuffle 操作来确定的, 有 Shuffle 的地方, Stage 断开
6.1. 逻辑执行图生成
6.1.1. RDD 的生成
重点内容
本章要回答如下三个问题
-
如何生成 RDD
-
生成什么 RDD
-
如何计算 RDD 中的数据
val sc = ...
val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop"))
val splitRDD = textRDD.flatMap(_.split(" "))
val tupleRDD = splitRDD.map((_, 1))
val reduceRDD = tupleRDD.reduceByKey(_ + _)
val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}")
println(strRDD.toDebugString)
strRDD.collect.foreach(item => println(item))明确逻辑计划的边界
在
Action调用之前, 会生成一系列的RDD, 这些RDD之间的关系, 其实就是整个逻辑计划例如上述代码, 如果生成逻辑计划的, 会生成如下一些
RDD, 这些RDD是相互关联的, 这些RDD之间, 其实本质上生成的就是一个 计算链
接下来, 采用迭代渐进式的方式, 一步一步的查看一下整体上的生成过程
textFile 算子的背后
研究
RDD的功能或者表现的时候, 其实本质上研究的就是RDD中的五大属性, 因为RDD透过五大属性来提供功能和表现, 所以如果要研究textFile这个算子, 应该从五大属性着手, 那么第一步就要看看生成的RDD是什么类型的RDD
textFile生成的是HadoopRDD
HadoopRDD的Partitions对应了HDFS的Blocks
其实本质上每个
HadoopRDD的Partition都是对应了一个Hadoop的Block, 通过InputFormat来确定Hadoop中的Block的位置和边界, 从而可以供一些算子使用
HadoopRDD的compute函数就是在读取HDFS中的Block本质上,
compute还是依然使用InputFormat来读取HDFS中对应分区的Block
textFile这个算子生成的其实是一个MapPartitionsRDD
textFile这个算子的作用是读取HDFS上的文件, 但是HadoopRDD中存放是一个元组, 其Key是行号, 其Value是Hadoop中定义的Text对象, 这一点和MapReduce程序中的行为是一致的但是并不适合
Spark的场景, 所以最终会通过一个map算子, 将(LineNum, Text)转为String形式的一行一行的数据, 所以最终textFile这个算子生成的RDD并不是HadoopRDD, 而是一个MapPartitionsRDD


map 算子的背后
map算子生成了MapPartitionsRDD由源码可知, 当
val rdd2 = rdd1.map()的时候, 其实生成的新RDD是rdd2,rdd2的类型是MapPartitionsRDD, 每个RDD中的五大属性都会有一些不同, 由map算子生成的RDD中的计算函数, 本质上就是遍历对应分区的数据, 将每一个数据转成另外的形式
MapPartitionsRDD的计算函数是collection.map( function )真正运行的集群中的处理单元是
Task, 每个Task对应一个RDD的分区, 所以collection对应一个RDD分区的所有数据, 而这个计算的含义就是将一个RDD的分区上所有数据当作一个集合, 通过这个Scala集合的map算子, 来执行一个转换操作, 其转换操作的函数就是传入map算子的function传入
map算子的函数会被清理
这个清理主要是处理闭包中的依赖, 使得这个闭包可以被序列化发往不同的集群节点运行 (闭包:一个函数把外部的那些不属于自己的对象也包含进来)


flatMap 算子的背后
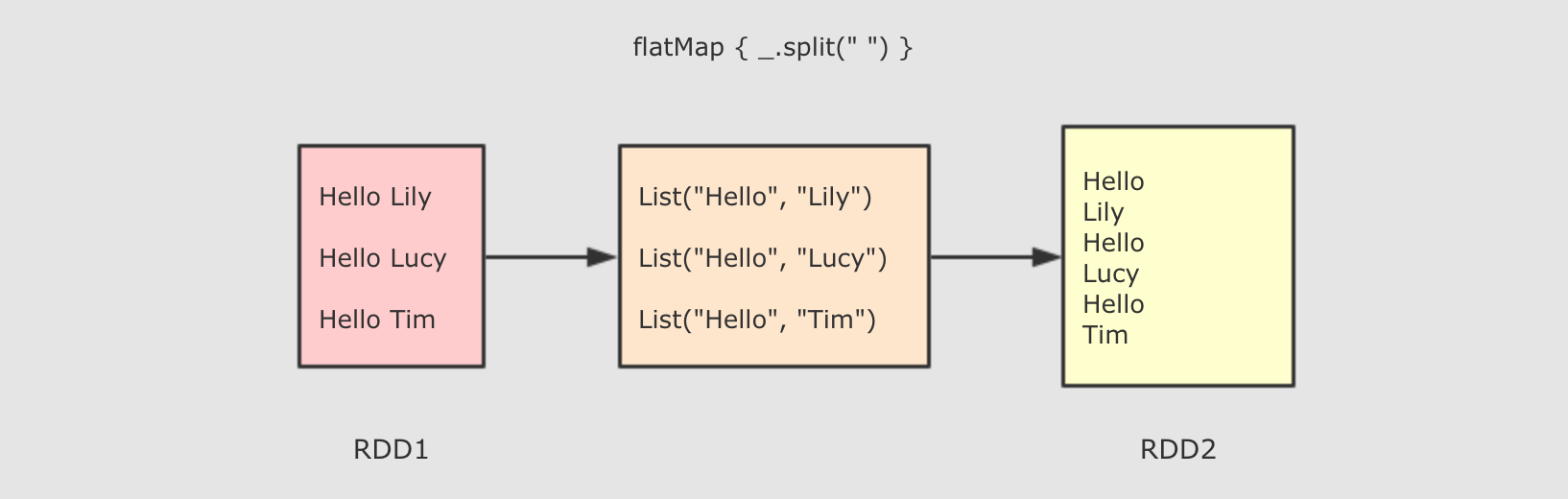
flatMap和map算子其实本质上是一样的, 其步骤和生成的RDD都是一样, 只是对于传入函数的处理不同,map是collect.map( function )而flatMap是collect.flatMap( function )从侧面印证了, 其实
Spark中的flatMap和Scala基础中的flatMap其实是一样的

textRDD → splitRDD → tupleRDD
由
textRDD到splitRDD再到tupleRDD的过程, 其实就是调用map和flatMap算子生成新的RDD的过程, 所以如下图所示, 就是这个阶段所生成的逻辑计划
总结
如何生成
RDD?生成
RDD的常见方式有三种
从本地集合创建
从外部数据集创建
从其它
RDD衍生通过外部数据集创建
RDD, 是通过Hadoop或者其它外部数据源的SDK来进行数据读取, 同时如果外部数据源是有分片的话,RDD会将分区与其分片进行对照通过其它
RDD衍生的话, 其实本质上就是通过不同的算子生成不同的RDD的子类对象, 从而控制compute函数的行为来实现算子功能生成哪些
RDD?不同的算子生成不同的
RDD, 生成RDD的类型取决于算子, 例如map和flatMap都会生成RDD的子类MapPartitions的对象如何计算
RDD中的数据 ?虽然前面我们提到过
RDD是偏向计算的, 但是其实RDD还只是表示数据, 纵观RDD的五大属性中有三个是必须的, 分别如下
Partitions List分区列表
Compute function计算函数
Dependencies依赖虽然计算函数是和计算有关的, 但是只有调用了这个函数才会进行计算,
RDD显然不会自己调用自己的Compute函数, 一定是由外部调用的, 所以RDD更多的意义是用于表示数据集以及其来源, 和针对于数据的计算所以如何计算
RDD中的数据呢? 一定是通过其它的组件来计算的, 而计算的规则, 由RDD中的Compute函数来指定, 不同类型的RDD子类有不同的Compute函数
6.1.2. RDD 之间的依赖关系
导读
-
讨论什么是 RDD 之间的依赖关系
-
继而讨论 RDD 分区之间的关系
-
最后确定 RDD 之间的依赖关系分类
-
完善案例的逻辑关系图
什么是 RDD 之间的依赖关系?
-
什么是关系(依赖关系) ?
从算子视角上来看,
splitRDD通过map算子得到了tupleRDD, 所以splitRDD和tupleRDD之间的关系是map但是
RDD这个概念本身并不是数据容器, 数据真正应该存放的地方是RDD的分区, 所以如果把视角放在数据这一层面上的话, 直接讲这两个 RDD 之间有关系是不科学的, 应该从这两个 RDD 的分区之间的关系来讨论它们之间的关系 -
那这些分区之间是什么关系?
如果仅仅说
splitRDD和tupleRDD之间的话, 那它们的分区之间就是一对一的关系但是
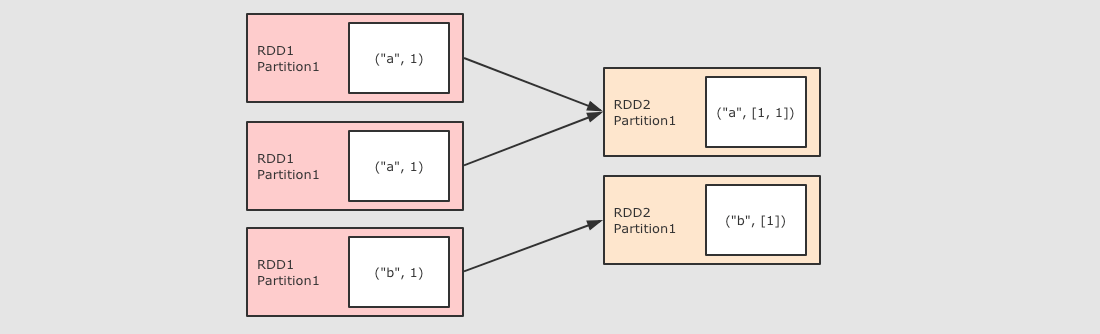
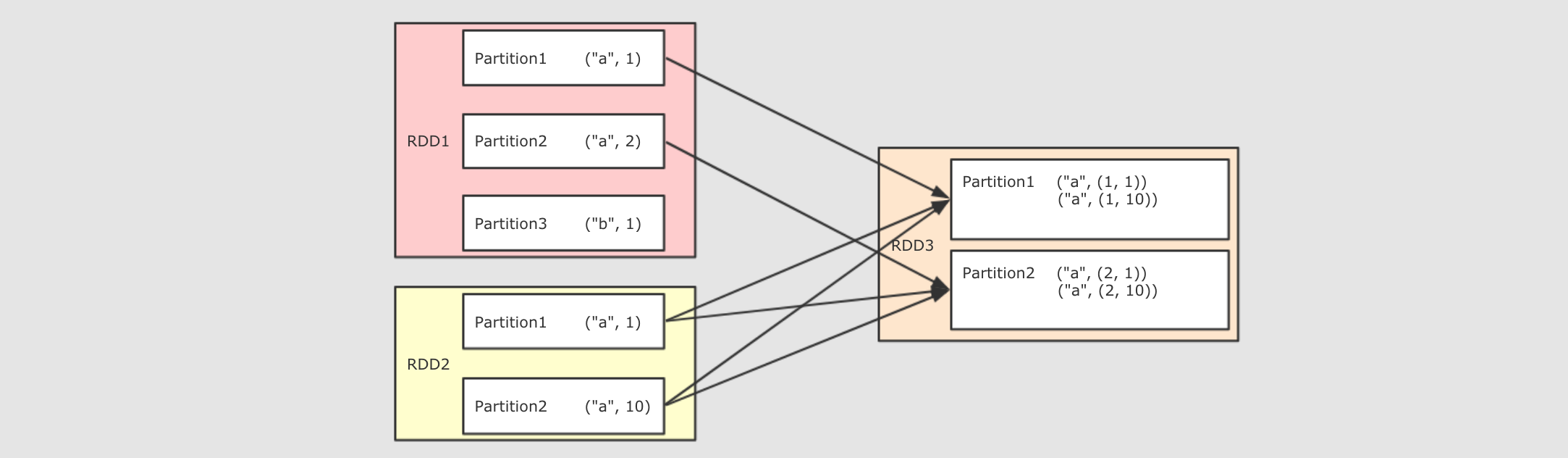
tupleRDD到reduceRDD呢?tupleRDD通过算子reduceByKey生成reduceRDD, 而这个算子是一个Shuffle操作,Shuffle操作的两个RDD的分区之间并不是一对一,reduceByKey的一个分区对应tupleRDD的多个分区
reduceByKey 算子会生成 ShuffledRDD
reduceByKey是由算子combineByKey来实现的,combineByKey内部会创建ShuffledRDD返回, 具体的代码请大家通过IDEA来进行查看, 此处不再截图, 而整个reduceByKey操作大致如下过程
去掉两个
reducer端的分区, 只留下一个的话, 如下
所以, 对于
reduceByKey这个Shuffle操作来说,reducer端的一个分区, 会从多个mapper端的分区拿取数据, 是一个多对一的关系至此为止, 出现了两种分区间的关系了, 一种是一对一, 一种是多对一
整体上的流程图
6.1.3. RDD 之间的依赖关系详解
导读
上个小节通过例子演示了 RDD 的分区间的关系有两种形式
一对一, 一般是直接转换
多对一, 一般是 Shuffle
本小节会说明如下问题:
如果分区间得关系是一对一或者多对一, 那么这种情况下的 RDD 之间的关系的正式命名是什么呢?
RDD 之间的依赖关系, 具体有几种情况呢?
窄依赖
假如
rddB = rddA.transform(…), 如果rddB中一个分区依赖rddA也就是其父RDD的少量分区, 这种RDD之间的依赖关系称之为窄依赖换句话说, 子 RDD 的每个分区依赖父 RDD 的少量个数的分区, 这种依赖关系称之为窄依赖
举个栗子
val sc = ... val rddA = sc.parallelize(Seq(1, 2, 3)) val rddB = sc.parallelize(Seq("a", "b")) /** * 运行结果: (1,a), (1,b), (2,a), (2,b), (3,a), (3,b) */ rddA.cartesian(rddB).collect().foreach(println(_))
上述代码的
cartesian是求得两个集合的笛卡尔积上述代码的运行结果是
rddA中每个元素和rddB中的所有元素结合, 最终的结果数量是两个RDD数量之和
rddC有两个父RDD, 分别为rddA和rddB对于
cartesian来说, 依赖关系如下
它们之间是窄依赖, 事实上在
cartesian中也是NarrowDependency这个所有窄依赖的父类的唯一一次直接使用, 为什么呢?因为所有的分区之间是拷贝关系, 并不是 Shuffle 关系
rddC中的每个分区并不是依赖多个父RDD中的多个分区
rddC中每个分区的数量来自一个父RDD分区中的所有数据, 是一个FullDependence, 所以数据可以直接从父RDD流动到子RDD不存在一个父
RDD中一部分数据分发过去, 另一部分分发给其它的RDD

宽依赖
并没有所谓的宽依赖, 宽依赖应该称作为
ShuffleDependency在
ShuffleDependency的类声明上如下写到Represents a dependency on the output of a shuffle stage.上面非常清楚的说道, 宽依赖就是
Shuffle中的依赖关系, 换句话说, 只有Shuffle产生的地方才是宽依赖那么宽窄依赖的判断依据就非常简单明确了, 是否有 Shuffle
举个
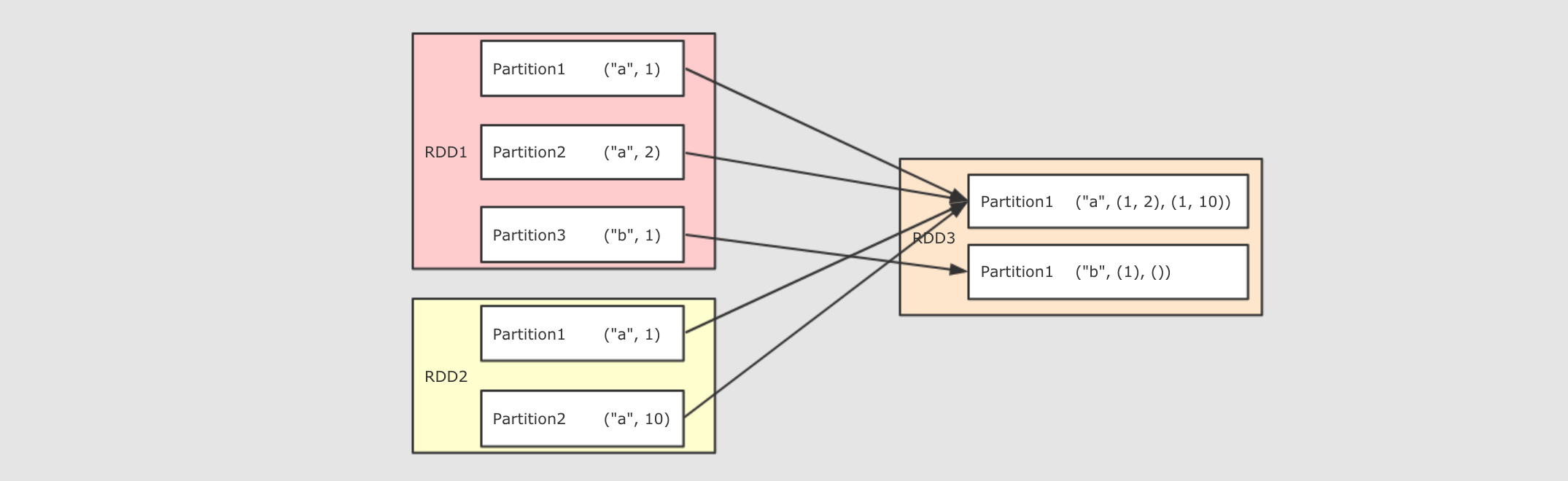
reduceByKey的例子,rddB = rddA.reduceByKey( (curr, agg) ⇒ curr + agg )会产生如下的依赖关系
rddB的每个分区都几乎依赖rddA的所有分区对于
rddA中的一个分区来说, 其将一部分分发给rddB的p1, 另外一部分分发给rddB的p2, 这不是数据流动, 而是分发
如何分辨宽窄依赖 ?
其实分辨宽窄依赖的本身就是在分辨父子
RDD之间是否有Shuffle, 大致有以下的方法
如果是
Shuffle, 两个RDD的分区之间不是单纯的数据流动, 而是分发和复制一般
Shuffle的子RDD的每个分区会依赖父RDD的多个分区但是这样判断其实不准确, 如果想分辨某个算子是否是窄依赖, 或者是否是宽依赖, 则还是要取决于具体的算子,看源码就行。
总结
RDD 的逻辑图本质上是对于计算过程的表达, 例如数据从哪来, 经历了哪些步骤的计算
每一个步骤都对应一个 RDD, 因为数据处理的情况不同, RDD 之间的依赖关系又分为窄依赖和宽依赖
6.1.4. 常见的窄依赖类型
一对一窄依赖
其实 RDD 中默认的是 OneToOneDependency, 后被不同的 RDD 子类指定为其它的依赖类型, 常见的一对一依赖是 map 算子所产生的依赖, 例如 rddB = rddA.map(…)
-
每个分区之间一 一对应, 所以叫做一对一窄依赖
Range 窄依赖
Range 窄依赖其实也是一对一窄依赖, 但是保留了中间的分隔信息, 可以通过某个分区获取其父分区, 目前只有一个算子生成这种窄依赖, 就是 union 算子, 例如 rddC = rddA.union(rddB)
-
rddC其实就是rddA拼接rddB生成的, 所以rddC的p5和p6就是rddB的p1和p2 -
所以需要有方式获取到
rddC的p5其父分区是谁, 于是就需要记录一下边界, 其它部分和一对一窄依赖一样
多对一窄依赖
多对一窄依赖其图形和 Shuffle 依赖非常相似, 所以在遇到的时候, 要注意其 RDD 之间是否有 Shuffle 过程, 比较容易让人困惑, 常见的多对一依赖就是重分区算子 coalesce, 例如 rddB = rddA.coalesce(2, shuffle = false), 但同时也要注意, 如果 shuffle = true 那就是完全不同的情况了
-
因为没有
Shuffle, 所以这是一个窄依赖
再谈宽窄依赖的区别
宽窄依赖的区别非常重要, 因为涉及了一件非常重要的事情: 如何计算
RDD?宽窄以来的核心区别是: 窄依赖的
RDD可以放在一个Task中运行
6.2. 物理执行图生成
谁来计算 RDD ?
问题一: RDD 是什么, 用来做什么 ?
回顾一下
RDD的五个属性
A list of partitions
A function for computing each split
A list of dependencies on other RDDs
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)简单的说就是: 分区列表, 计算函数, 依赖关系, 分区函数, 最佳位置
分区列表, 分区函数, 最佳位置, 这三个属性其实说的就是数据集在哪, 在哪更合适, 如何分区
计算函数和依赖关系, 这两个属性其实说的是数据集从哪来
所以结论是
RDD是一个数据集的表示, 不仅表示了数据集, 还表示了这个数据集从哪来, 如何计算问题二: 谁来计算 ?
前面我们明确了两件事,
RDD在哪被计算? 在Executor中.RDD是什么? 是一个数据集以及其如何计算的图纸.直接使用
Executor也是不合适的, 因为一个计算的执行总是需要一个容器, 例如JVM是一个进程, 只有进程中才能有线程, 所以这个计算RDD的线程应该运行在一个进程中, 这个进程就是Exeutor,Executor有如下两个职责
和
Driver保持交互从而认领属于自己的任务
接受任务后, 运行任务
所以, 应该由一个线程来执行
RDD的计算任务, 而Executor作为执行这个任务的容器, 也就是一个进程, 用于创建和执行线程, 这个执行具体计算任务的线程叫做Task问题三: Task 该如何设计 ?
第一个想法是每个
RDD都由一个Task来计算 第二个想法是一整个逻辑执行图中所有的RDD都由一组Task来执行 第三个想法是分阶段执行第一个想法: 为每个 RDD 的分区设置一组 Task
第二个想法: 让数据流动
很自然的, 第一个想法的问题是数据需要存储和交换, 那不存储不就好了吗? 对, 可以让数据流动起来
第一个要解决的问题就是, 要为数据创建管道(
Pipeline), 有了管道, 就可以流动
简单来说, 就是为所有的
RDD有关联的分区使用同一个Task, 但是就没问题了吗? 请关注红框部分
这两个
RDD之间是Shuffle关系, 也就是说, 右边的RDD的一个分区可能依赖左边RDD的所有分区, 这样的话, 数据在这个地方流不动了, 怎么办?第三个想法: 划分阶段
既然在
Shuffle处数据流不动了, 那就可以在这个地方中断一下, 后面Stage部分详解
如何划分阶段 ?
为了减少执行任务, 减少数据暂存和交换的机会, 所以需要创建管道, 让数据沿着管道流动, 其实也就是原先每个
RDD都有一组Task, 现在改为所有的RDD共用一组Task, 但是也有问题, 问题如下
就是说, 在
Shuffle处, 必须断开管道, 进行数据交换, 交换过后, 继续流动, 所以整个流程可以变为如下样子
把
Task断开成两个部分,Task4可以从Task 1, 2, 3中获取数据, 后Task4又作为管道, 继续让数据在其中流动但是还有一个问题, 说断开就直接断开吗? 不用打个招呼的呀? 所以可以为这个断开增加一个概念叫做阶段, 按照阶段断开, 阶段的英文叫做
Stage, 如下
所以划分阶段的本身就是设置断开点的规则, 那么该如何划分阶段呢?
第一步, 从最后一个
RDD, 也就是逻辑图中最右边的RDD开始, 向前滑动Stage的范围, 为Stage0第二步, 遇到
ShuffleDependency断开Stage, 从下一个RDD开始创建新的Stage, 为Stage1第三步, 新的
Stage按照同样的规则继续滑动, 直到包裹所有的RDD总结来看, 就是针对于宽窄依赖来判断, 一个
Stage中只有窄依赖, 因为只有窄依赖才能形成数据的Pipeline.如果要进行
Shuffle的话, 数据是流不过去的, 必须要拷贝和拉取. 所以遇到RDD宽依赖的两个RDD时, 要切断这两个RDD的Stage.这样一个 RDD 依赖的链条, 我们称之为 RDD 的血统(lineage), 其中有宽依赖也有窄依赖
数据怎么流动 ?
val sc = ... val textRDD = sc.parallelize(Seq("Hadoop Spark", "Hadoop Flume", "Spark Sqoop")) val splitRDD = textRDD.flatMap(_.split(" ")) val tupleRDD = splitRDD.map((_, 1)) val reduceRDD = tupleRDD.reduceByKey(_ + _) val strRDD = reduceRDD.map(item => s"${item._1}, ${item._2}") strRDD.collect.foreach(item => println(item))上述代码是我们一直使用的代码流程, 如下是其完整的逻辑执行图
如果放在集群中运行, 通过
WebUI可以查看到如下DAG结构
Step 1: 从
ResultStage开始执行最接近
Result部分的Stage id为 0, 这个Stage被称之为ResultStage由代码可以知道, 最终调用
Action促使整个流程执行的是最后一个RDD,strRDD.collect, 所以当执行RDD的计算时候, 先计算的也是这个RDDStep 2:
RDD之间是有关联的前面已经知道, 最后一个
RDD先得到执行机会, 先从这个RDD开始执行, 但是这个RDD中有数据吗 ? 如果没有数据, 它的计算是什么? 它的计算是从父RDD中获取数据, 并执行传入的算子的函数简单来说, 从产生
Result的地方开始计算, 但是其RDD中是没数据的, 所以会找到父RDD来要数据, 父RDD也没有数据, 继续向上要, 所以, 计算从Result处调用, 但是从整个逻辑图中的最左边RDD开始, 类似一个递归的过程
这个过程就像 往 HDFS 上传 数据一样,建立 pinpline , 上传 ,返回 ack。 且 这样理解吧
6.3. 调度过程
导读
-
生成逻辑图和物理图的系统组件
-
Job和Stage,Task之间的关系 -
如何调度
Job
逻辑图
逻辑图如何生成
一段
Scala代码的执行结果就是最后一行的执行结果,最后一个RDD也可以认为就是逻辑执行图, 为什么呢?例如
rdd2 = rdd1.map(…)中, 其实本质上rdd2是一个类型为MapPartitionsRDD的对象, 而创建这个对象的时候, 会通过构造函数传入当前RDD对象, 也就是父RDD, 也就是调用map算子的rdd1,rdd1是rdd2的父RDD一个
RDD依赖另外一个RDD, 这个RDD又依赖另外的RDD, 一个RDD可以通过getDependency获得其父RDD, 这种环环相扣的关系, 最终从最后一个RDD就可以推演出前面所有的RDD逻辑图是什么, 干啥用
逻辑图其实本质上描述的就是数据的计算过程, 数据从哪来, 经过什么样的计算, 得到什么样的结果, 再执行什么计算, 得到什么结果
可是数据的计算是描述好了, 这种计算该如何执行呢?
物理图
数据的计算表示好了, 该正式执行了, 但是如何执行? 如何执行更快更好更酷? 就需要为其执行做一个规划, 所以需要生成物理执行图
strRDD.collect.foreach(item => println(item))上述代码其实就是最后的一个
RDD调用了Action方法, 调用Action方法的时候, 会请求一个叫做DAGScheduler的组件,DAGScheduler会创建用于执行RDD的Stage和Task
DAGScheduler是一个由SparkContext创建, 运行在Driver上的组件, 其作用就是将由RDD构建出来的逻辑计划, 构建成为由真正在集群中运行的Task组成的物理执行计划,DAGScheduler主要做如下三件事
帮助每个
Job计算DAG并发给TaskSheduler调度确定每个
Task的最佳位置跟踪
RDD的缓存状态, 避免重新计算从字面意思上来看,
DAGScheduler是调度DAG去运行的,DAG被称作为有向无环图, 其实可以将DAG理解为就是RDD的逻辑图, 其呈现两个特点:RDD的计算是有方向的,RDD的计算是无环的, 所以DAGScheduler也可以称之为RDD Scheduler, 但是真正运行在集群中的并不是RDD, 而是Task和Stage,DAGScheduler负责这种转换
Job 是什么 ?
Job什么时候生成 ?当一个
RDD调用了Action算子的时候, 在Action算子内部, 会使用sc.runJob()调用SparkContext中的runJob方法, 这个方法又会调用DAGScheduler中的runJob, 后在DAGScheduler中使用消息驱动的形式创建Job简而言之,
Job在RDD调用Action算子的时候生成, 而且调用一次Action算子, 就会生成一个Job, 如果一个SparkApplication中调用了多次Action算子, 会生成多个Job串行执行, 每个Job独立运作, 被独立调度, 所以RDD的计算也会被执行多次
Job是什么 ?如果要将
Spark的程序调度到集群中运行,Job是粒度最大的单位, 调度以Job为最大单位, 将Job拆分为Stage和Task去调度分发和运行, 一个Job就是一个Spark程序从读取 → 计算 → 运行的过程一个
Spark Application可以包含多个Job, 这些Job之间是串行的, 也就是第二个Job需要等待第一个Job的执行结束后才会开始执行
Job 和 Stage 的关系
Job是一个最大的调度单位, 也就是说DAGScheduler会首先创建一个Job的相关信息, 后去调度Job, 但是没办法直接调度Job, 比如说现在要做一盘手撕包菜, 不可能直接去炒一整颗包菜, 要切好撕碎, 再去炒为什么
Job需要切分 ?
因为
Job的含义是对整个RDD血统求值, 但是RDD之间可能会有一些宽依赖如果遇到宽依赖的话, 两个
RDD之间需要进行数据拉取和复制如果要进行拉取和复制的话, 那么一个
RDD就必须等待它所依赖的RDD所有分区先计算完成, 然后再进行拉取由上得知, 一个
Job是无法计算完整个RDD血统的如何切分 ?
创建一个
Stage, 从后向前回溯RDD, 遇到Shuffle依赖就结束Stage, 后创建新的Stage继续回溯. 这个过程上面已经详细的讲解过, 但是问题是切分以后如何执行呢, 从后向前还是从前向后, 是串行执行多个Stage, 还是并行执行多个Stage问题一: 执行顺序
在图中,
Stage 0的计算需要依赖Stage 1的数据, 因为reduceRDD中一个分区可能需要多个tupleRDD分区的数据, 所以tupleRDD必须先计算完, 所以, 应该在逻辑图中自左向右执行Stage问题二: 串行还是并行
Stage 1不仅需要先执行, 而且Stage 1执行完之前Stage 0无法执行, 它们只能串行执行总结
一个
Stage就是物理执行计划中的一个步骤, 一个Spark Job就是划分到不同Stage的计算过程
Stage之间的边界由Shuffle操作来确定
Stage内的RDD之间都是窄依赖, 可以放在一个管道中执行而
Shuffle后的Stage需要等待前面Stage的执行
Stage有两种
ShuffMapStage, 其中存放窄依赖的RDD
ResultStage, 每个Job只有一个, 负责计算结果, 一个ResultStage执行完成标志着整个Job执行完毕
Stage 和 Task 的关系
前面我们说到
Job无法直接执行, 需要先划分为多个Stage, 去执行Stage, 那么Stage可以直接执行吗?
第一点:
Stage中的RDD之间是窄依赖因为
Stage中的所有RDD之间都是窄依赖, 窄依赖RDD理论上是可以放在同一个Pipeline(管道, 流水线)中执行的, 似乎可以直接调度Stage了? 其实不行, 看第二点第二点: 别忘了
RDD还有分区一个
RDD只是一个概念, 而真正存放和处理数据时, 都是以分区作为单位的
Stage对应的是多个整体上的RDD, 而真正的运行是需要针对RDD的分区来进行的第三点: 一个
Task对应一个RDD的分区一个比
Stage粒度更细的单元叫做Task,Stage是由Task组成的, 之所以有Task这个概念, 是因为Stage针对整个RDD, 而计算的时候, 要针对RDD的分区假设一个
Stage中有 10 个RDD, 这些RDD中的分区各不相同, 但是分区最多的RDD有 30 个分区, 而且很显然, 它们之间是窄依赖关系那么, 这个
Stage中应该有多少Task呢? 应该有 30 个Task, 因为一个Task计算一个RDD的分区. 这个Stage至多有 30 个分区需要计算总结
一个
Stage就是一组并行的Task集合Task 是 Spark 中最小的独立执行单元, 其作用是处理一个 RDD 分区
一个 Task 只可能存在于一个 Stage 中, 并且只能计算一个 RDD 的分区
TaskSet
梳理一下这几个概念, Job > Stage > Task, Job 中包含 Stage 中包含 Task
而 Stage 中经常会有一组 Task 需要同时执行, 所以针对于每一个 Task 来进行调度太过繁琐, 而且没有意义, 所以每个 Stage 中的 Task 们会被收集起来, 放入一个 TaskSet 集合中
-
一个
Stage有一个TaskSet -
TaskSet中Task的个数由Stage中的最大分区数决定
整体执行流程
6.4. Shuffle 过程
Shuffle 过程的组件结构
从整体视角上来看, Shuffle 发生在两个 Stage 之间, 一个 Stage 把数据计算好, 整理好, 等待另外一个 Stage 来拉取
放大视角, 会发现, 其实 Shuffle 发生在 Task 之间, 一个 Task 把数据整理好, 等待 Reducer 端的 Task 来拉取
如果更细化一下, Task 之间如何进行数据拷贝的呢? 其实就是一方 Task 把文件生成好, 然后另一方 Task 来拉取
现在是一个 Reducer 的情况, 如果有多个 Reducer 呢? 如果有多个 Reducer 的话, 就可以在每个 Mapper 为所有的 Reducer 生成各一个文件, 这种叫做 Hash base shuffle, 这种 Shuffle 的方式问题大家也知道, 就是生成中间文件过多, 而且生成文件的话需要缓冲区, 占用内存过大
那么可以把这些文件合并起来, 生成一个文件返回, 这种 Shuffle 方式叫做 Sort base shuffle, 每个 Reducer 去文件的不同位置拿取数据
如果再细化一下, 把参与这件事的组件也放置进去, 就会是如下这样
有哪些 ShuffleWriter ?
大致上有三个 ShufflWriter, Spark 会按照一定的规则去使用这三种不同的 Writer
-
BypassMergeSortShuffleWriter这种
Shuffle Writer也依然有Hash base shuffle的问题, 它会在每一个Mapper端对所有的Reducer生成一个文件, 然后再合并这个文件生成一个统一的输出文件, 这个过程中依然是有很多文件产生的, 所以只适合在小量数据的场景下使用Spark有考虑去掉这种Writer, 但是因为结构中有一些依赖, 所以一直没去掉当
Reducer个数小于spark.shuffle.sort.bypassMergeThreshold, 并且没有Mapper端聚合的时候启用这种方式 -
SortShuffleWriter这种
ShuffleWriter写文件的方式非常像MapReduce了, 后面详说当其它两种
Shuffle不符合开启条件时, 这种Shuffle方式是默认的 -
UnsafeShuffleWriter这种
ShuffWriter会将数据序列化, 然后放入缓冲区进行排序, 排序结束后Spill到磁盘, 最终合并Spill文件为一个大文件, 同时在进行内存存储的时候使用了Java得Unsafe API, 也就是使用堆外内存, 是钨丝计划的一部分也不是很常用, 只有在满足如下三个条件时候才会启用
-
序列化器序列化后的数据, 必须支持排序
-
没有
Mapper端的聚合 -
Reducer的个数不能超过支持的上限 (2 ^ 24)
-
SortShuffleWriter 的执行过程
整个 SortShuffleWriter 如上述所说, 大致有如下几步
-
首先
SortShuffleWriter在write方法中回去写文件, 这个方法中创建了ExternalSorter -
write中将数据insertAll到ExternalSorter中 -
在
ExternalSorter中排序-
如果要聚合, 放入
AppendOnlyMap中, 如果不聚合, 放入PartitionedPairBuffer中 -
在数据结构中进行排序, 排序过程中如果内存数据大于阈值则溢写到磁盘
-
-
使用
ExternalSorter的writePartitionedFile写入输入文件-
将所有的溢写文件通过类似
MergeSort的算法合并 -
将数据写入最终的目标文件中
-
七、 RDD 的分布式共享变量
目标
-
理解闭包以及 Spark 分布式运行代码的根本原理
-
理解累加变量的使用场景
-
理解广播的使用场景
什么是闭包
闭包是一个必须要理解, 但是又不太好理解的知识点, 先看一个小例子
@Test def test(): Unit = { val areaFunction = closure() val area = areaFunction(2) println(area) } def closure(): Int => Double = { val factor = 3.14 val areaFunction = (r: Int) => math.pow(r, 2) * factor areaFunction }上述例子中, `closure`方法返回的一个函数的引用, 其实就是一个闭包, 闭包本质上就是一个封闭的作用域, 要理解闭包, 是一定要和作用域联系起来的.
能否在
test方法中访问closure定义的变量?@Test def test(): Unit = { println(factor) } def closure(): Int => Double = { val factor = 3.14 }有没有什么间接的方式?
@Test def test(): Unit = { val areaFunction = closure() areaFunction() } def closure(): () => Unit = { val factor = 3.14 val areaFunction = () => println(factor) areaFunction }什么是闭包?
val areaFunction = closure() areaFunction()通过
closure返回的函数areaFunction就是一个闭包, 其函数内部的作用域并不是test函数的作用域, 这种连带作用域一起打包的方式, 我们称之为闭包, 在 Scala 中Scala 中的闭包本质上就是一个对象, 是 FunctionX 的实例
分发闭包
sc.textFile("dataset/access_log_sample.txt") .flatMap(item => item.split("")) .collect()上述这段代码中,
flatMap中传入的是另外一个函数, 传入的这个函数就是一个闭包, 这个闭包会被序列化运行在不同的 Executor 中
class MyClass { val field = "Hello" def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(x => field + x) } }这段代码中的闭包就有了一个依赖, 依赖于外部的一个类, 因为传递给算子的函数最终要在 Executor 中运行, 所以需要 序列化
MyClass发给每一个Executor, 从而在Executor访问MyClass对象的属性
总结
闭包就是一个封闭的作用域, 也是一个对象
Spark 算子所接受的函数, 本质上是一个闭包, 因为其需要封闭作用域, 并且序列化自身和依赖, 分发到不同的节点中运行
7.1. 累加器
一个小问题
var count = 0
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
sc.parallelize(Seq(1, 2, 3, 4, 5))
.foreach(count += _)
println(count)上面这段代码是一个非常错误的使用, 请不要仿照, 这段代码只是为了证明一些事情
先明确两件事, var count = 0 是在 Driver 中定义的, foreach(count += _) 这个算子以及传递进去的闭包运行在 Executor 中
这段代码整体想做的事情是累加一个变量, 但是这段代码的写法却做不到这件事, 原因也很简单, 因为具体的算子是闭包, 被分发给不同的节点运行, 所以这个闭包中累加的并不是 Driver 中的这个变量
全局累加器
Accumulators(累加器) 是一个只支持 added(添加) 的分布式变量, 可以在分布式环境下保持一致性, 并且能够做到高效的并发.
原生 Spark 支持数值型的累加器, 可以用于实现计数或者求和, 开发者也可以使用自定义累加器以实现更高级的需求
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
val counter = sc.longAccumulator("counter")
sc.parallelize(Seq(1, 2, 3, 4, 5))
.foreach(counter.add(_))
// 运行结果: 15
println(counter.value)注意点:
-
Accumulator 是支持并发并行的, 在任何地方都可以通过
add来修改数值, 无论是 Driver 还是 Executor -
只能在 Driver 中才能调用
value来获取数值
在 WebUI 中关于 Job 部分也可以看到 Accumulator 的信息, 以及其运行的情况
累计器件还有两个小特性, 第一, 累加器能保证在 Spark 任务出现问题被重启的时候不会出现重复计算. 第二, 累加器只有在 Action 执行的时候才会被触发.
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
val counter = sc.longAccumulator("counter")
sc.parallelize(Seq(1, 2, 3, 4, 5))
.map(counter.add(_)) // 这个地方不是 Action, 而是一个 Transformation
// 运行结果是 0
println(counter.value)自定义累加器
开发者可以通过自定义累加器来实现更多类型的累加器, 累加器的作用远远不只是累加, 比如可以实现一个累加器, 用于向里面添加一些运行信息
class InfoAccumulator extends AccumulatorV2[String, Set[String]] {
private val infos: mutable.Set[String] = mutable.Set()
override def isZero: Boolean = {
infos.isEmpty
}
override def copy(): AccumulatorV2[String, Set[String]] = {
val newAccumulator = new InfoAccumulator()
infos.synchronized {
newAccumulator.infos ++= infos
}
newAccumulator
}
override def reset(): Unit = {
infos.clear()
}
override def add(v: String): Unit = {
infos += v
}
override def merge(other: AccumulatorV2[String, Set[String]]): Unit = {
infos ++= other.value
}
override def value: Set[String] = {
infos.toSet
}
}
@Test
def accumulator2(): Unit = {
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
val infoAccumulator = new InfoAccumulator()
sc.register(infoAccumulator, "infos")
sc.parallelize(Seq("1", "2", "3"))
.foreach(item => infoAccumulator.add(item))
// 运行结果: Set(3, 1, 2)
println(infoAccumulator.value)
sc.stop()
}注意点:
-
可以通过继承
AccumulatorV2来创建新的累加器 -
有几个方法需要重写
-
reset 方法用于把累加器重置为 0
-
add 方法用于把其它值添加到累加器中
-
merge 方法用于指定如何合并其他的累加器
-
-
value需要返回一个不可变的集合, 因为不能因为外部的修改而影响自身的值
7.2. 广播变量
目标
-
理解为什么需要广播变量, 以及其应用场景
-
能够通过代码使用广播变量
广播变量的作用
广播变量允许开发者将一个
Read-Only的变量缓存到集群中每个节点中, 而不是传递给每一个 Task 一个副本.
集群中每个节点, 指的是一个机器
每一个 Task, 一个 Task 是一个 Stage 中的最小处理单元, 一个 Executor 中可以有多个 Stage, 每个 Stage 有多个 Task
所以在需要跨多个 Stage 的多个 Task 中使用相同数据的情况下, 广播特别的有用
广播变量的API
| 方法名 | 描述 |
|---|---|
|
|
唯一标识 |
|
|
广播变量的值 |
|
|
在 Executor 中异步的删除缓存副本 |
|
|
销毁所有此广播变量所关联的数据和元数据 |
|
|
字符串表示 |
使用广播变量的一般套路
可以通过如下方式创建广播变量
val b = sc.broadcast(1)如果 Log 级别为 DEBUG 的时候, 会打印如下信息
DEBUG BlockManager: Put block broadcast_0 locally took 430 ms DEBUG BlockManager: Putting block broadcast_0 without replication took 431 ms DEBUG BlockManager: Told master about block broadcast_0_piece0 DEBUG BlockManager: Put block broadcast_0_piece0 locally took 4 ms DEBUG BlockManager: Putting block broadcast_0_piece0 without replication took 4 ms创建后可以使用
value获取数据b.value获取数据的时候会打印如下信息
DEBUG BlockManager: Getting local block broadcast_0 DEBUG BlockManager: Level for block broadcast_0 is StorageLevel(disk, memory, deserialized, 1 replicas)广播变量使用完了以后, 可以使用
unpersist删除数据b.unpersist删除数据以后, 可以使用
destroy销毁变量, 释放内存空间b.destroy销毁以后, 会打印如下信息
DEBUG BlockManager: Removing broadcast 0 DEBUG BlockManager: Removing block broadcast_0_piece0 DEBUG BlockManager: Told master about block broadcast_0_piece0 DEBUG BlockManager: Removing block broadcast_0使用
value方法的注意点方法签名
value: T在
value方法内部会确保使用获取数据的时候, 变量必须是可用状态, 所以必须在变量被destroy之前使用value方法, 如果使用value时变量已经失效, 则会爆出以下错误org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27) at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144) at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:69) ... 48 elided使用
destroy方法的注意点方法签名
destroy(): Unit
destroy方法会移除广播变量, 彻底销毁掉, 但是如果你试图多次destroy广播变量, 则会爆出以下错误org.apache.spark.SparkException: Attempted to use Broadcast(0) after it was destroyed (destroy at <console>:27) at org.apache.spark.broadcast.Broadcast.assertValid(Broadcast.scala:144) at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:107) at org.apache.spark.broadcast.Broadcast.destroy(Broadcast.scala:98) ... 48 elided
广播变量的使用场景
假设我们在某个算子中需要使用一个保存了项目和项目的网址关系的
Map[String, String]静态集合, 如下val pws = Map("Apache Spark" -> "http://spark.apache.org/", "Scala" -> "http://www.scala-lang.org/") val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pws).collect上面这段代码是没有问题的, 可以正常运行的, 但是非常的低效, 因为虽然可能
pws已经存在于某个Executor中了, 但是在需要的时候还是会继续发往这个Executor, 如果想要优化这段代码, 则需要尽可能的降低网络开销可以使用广播变量进行优化, 因为广播变量会缓存在集群中的机器中, 比
Executor在逻辑上更 "大"val pwsB = sc.broadcast(pws) val websites = sc.parallelize(Seq("Apache Spark", "Scala")).map(pwsB.value).collect上面两段代码所做的事情其实是一样的, 但是当需要运行多个
Executor(以及多个Task) 的时候, 后者的效率更高
扩展
正常情况下使用 Task 拉取数据的时候, 会将数据拷贝到 Executor 中多次, 但是使用广播变量的时候只会复制一份数据到 Executor 中, 所以在两种情况下特别适合使用广播变量
一个 Executor 中有多个 Task 的时候
一个变量比较大的时候
而且在 Spark 中还有一个约定俗称的做法, 当一个 RDD 很大并且还需要和另外一个 RDD 执行
join的时候, 可以将较小的 RDD 广播出去, 然后使用大的 RDD 在算子map中直接join, 从而实现在 Map 端joinval acMap = sc.broadcast(myRDD.map { case (a,b,c,b) => (a, c) }.collectAsMap) val otherMap = sc.broadcast(myOtherRDD.collectAsMap) myBigRDD.map { case (a, b, c, d) => (acMap.value.get(a).get, otherMap.value.get(c).get) }.collect一般情况下在这种场景下, 会广播 Map 类型的数据, 而不是数组, 因为这样容易使用 Key 找到对应的 Value 简化使用
总结
-
广播变量用于将变量缓存在集群中的机器中, 避免机器内的 Executors 多次使用网络拉取数据
-
广播变量的使用步骤: (1) 创建 (2) 在 Task 中获取值 (3) 销毁
