目录
流程
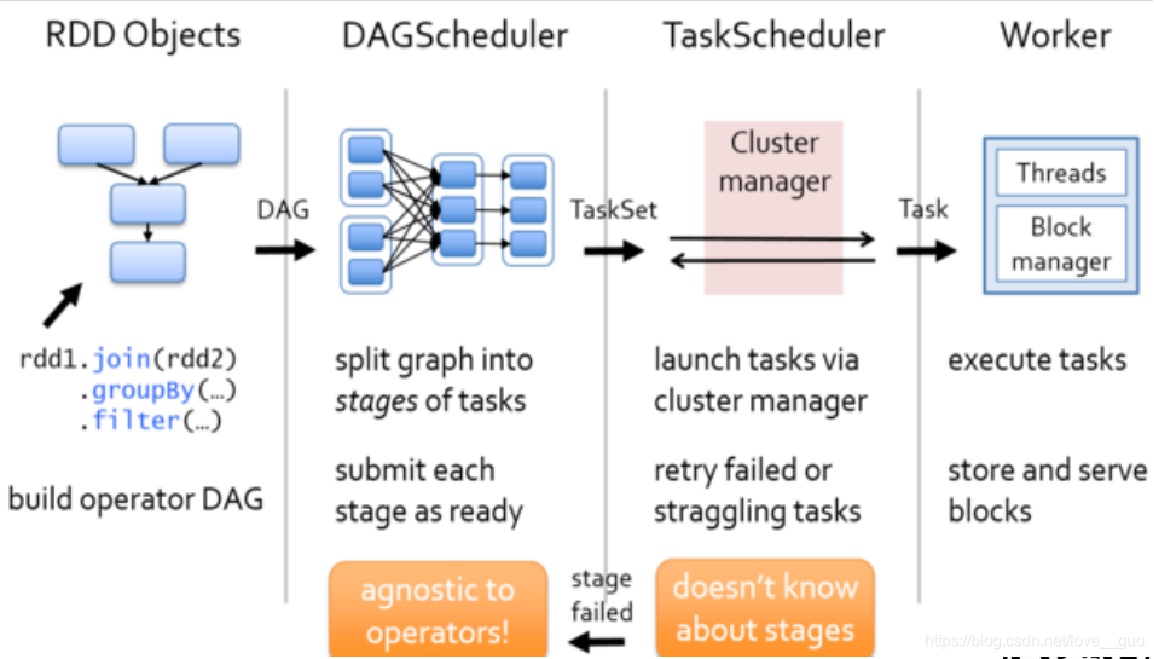
1.Soark中,我们写的应用程序都是一个个RDD对象组成的。可以根据代码画出来一个DAG有向无环图,将DAG有向无环图交给DAG Scheduler;
2.DAG Scheduler根据款窄依赖将DAG有有向无环图切割成一个个的stage,将切割出来的stage封装成另一个对象TaskSet,TaskSet就是一个个的stage。然后DAG Scheduler将一个个的taskSet发送给TaskScheduler;
3.Task Scheduler拿到TaskSet后,会遍历这个集合,拿到每一个task,然后去调用HDFS上某一个方法获取数据的位置。依据数据的位置来分发Task到Worker节点的Executor进程中的线程池中执行;
4.Task Scheduler会实时跟踪每一个task的执行情况,若执行失败,Task Scheduler会重试提交task,不会无休止的重试,默认重试3次。若重试3次依然失败,那么这个task所在的stage就失败了;
5.此时Task Scheduler会向DAG Scheduler汇报,当前stage是顾拜,此时DAG Scheduler会重试提交stage(每一次重试提交的stage,已经充公执行的不会再次分发到Executor进程执行,知识重试失败的);
6.如果DAG Scheduler重试了4次依然失败,那么stage所在的job就失败了,job失败是不会进行重试的。
Q:什么是挣扎(掉队 )任务?
A:如果应用程序中有1W个task,其中有9999个已经运行成功,剩下1个task仍在运行,那么我们认为这1个tasl就是挣扎任务。当Task Scheduler遇到挣扎的任务,它会重试,此时Task Scheduler会重新提交一个和挣扎的的tsk一模一样的task到集群中运行(挣扎的task不会被kill掉),让两个task再集群中比赛执行,谁先执行完毕就以谁的结果为准。
Q:什么是推测执行机制?
A:标准:100ms,1.5,75%
当所有的task的75%以上全部执行完毕,那么才会每隔100ms计算一次查看哪些task需要推测执行。
如果应用程序中有100个task,已经有76个task执行完毕,还有24个正在运行,此时它会计算这24个task已经执行时间的中位数,然后将中位数*1.5=时间,用这个时间去查看哪一些task超时,此时这些task就是挣扎的task。
Q:如果1T数据,单击运行需要30min,但是使用Spark(4node)需要2h,为什么?
A:1.计算发生了数据倾斜
2.开启了推测执行机制
Q:对于ETL(Extract Transform Load,数据清洗流程)类型的业务,开启推测执行、重试机制,对于最终的结果会不会有影响?
A:有影响,最终的数据库中会有重复数据。如果第一个task执行90%失败,第二个task执行成功,那么第一个task的数据也会插入到数据库中。
解决方法:1.关闭各种推测、重试机制;
2.设置一张事务表。