大数据:spark内核调度
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
大数据:spark内核调度

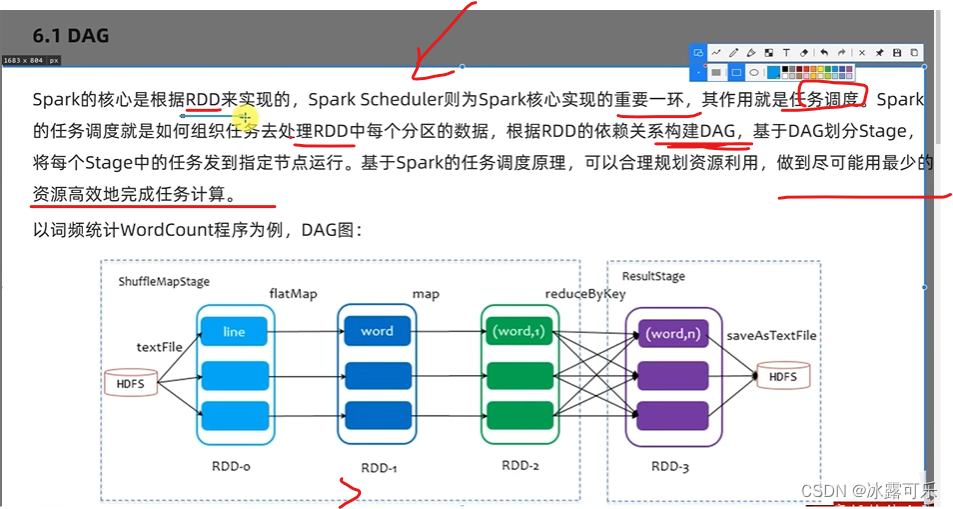
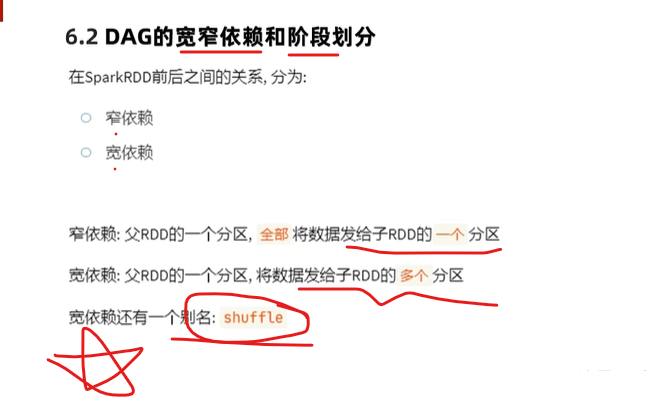
DAG,有方向direction ancircle 无环graph图
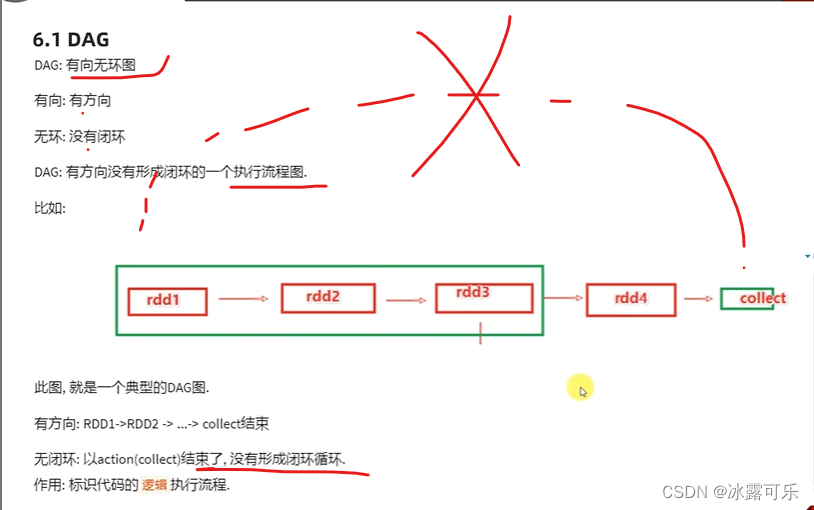
DAG有向无环图
action是执行开关
执行之前是有一个迭代链条哦
这个链条就是DAG有向无环图
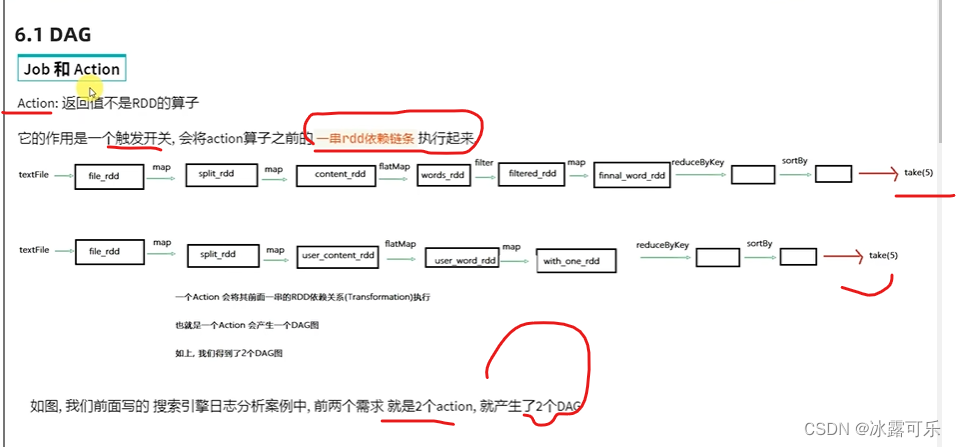
就是执行流程图,不需要运行,看代码就知道你要咋运行
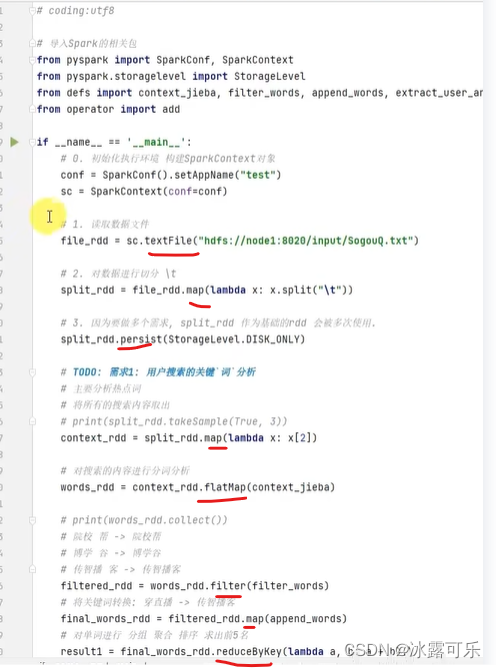
一步步走
构建DAG图

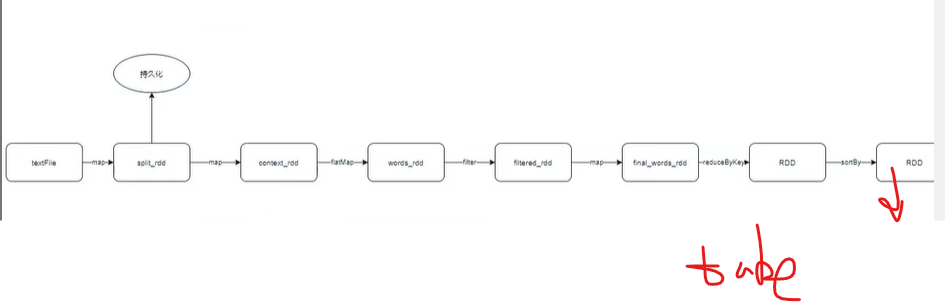
构建出来一个DAG
因为take启动就可以搞定所有的任务
继续需求2
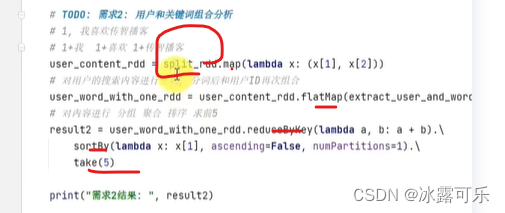
又是跟split_rdd开始玩的
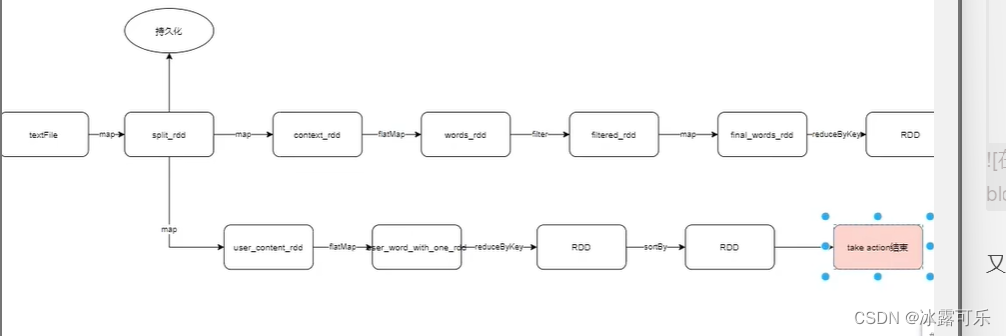
take就是触发开关
持久化了的缓存就可以直接用

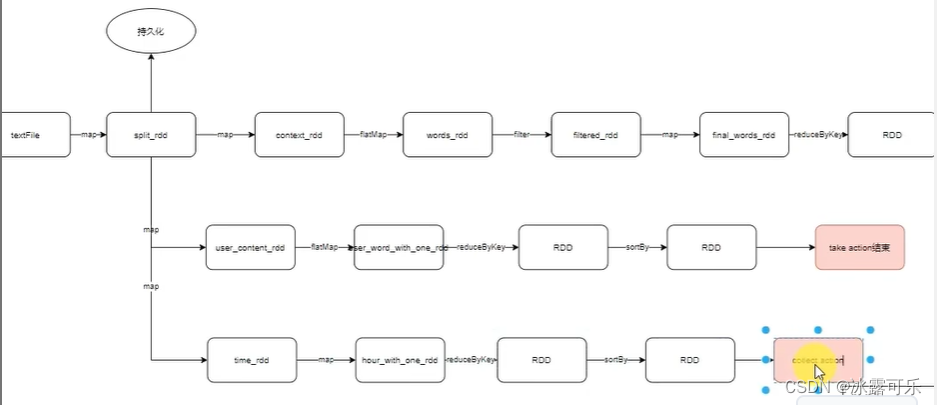
各个action,都有各自的链条
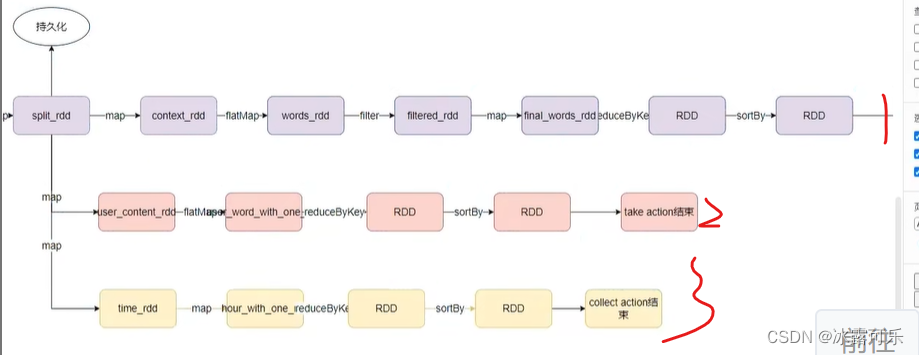
一个action触发一个工作应用程序子任务job
job
一条链子就是一个job
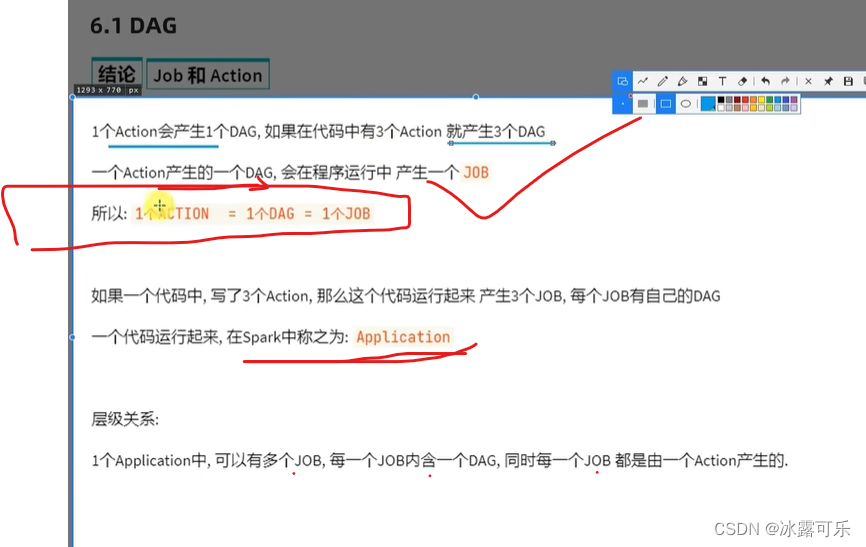
懂了,action有多少个,就有多少dag
一个application包含多个action,就是多个job
懂了
分叉
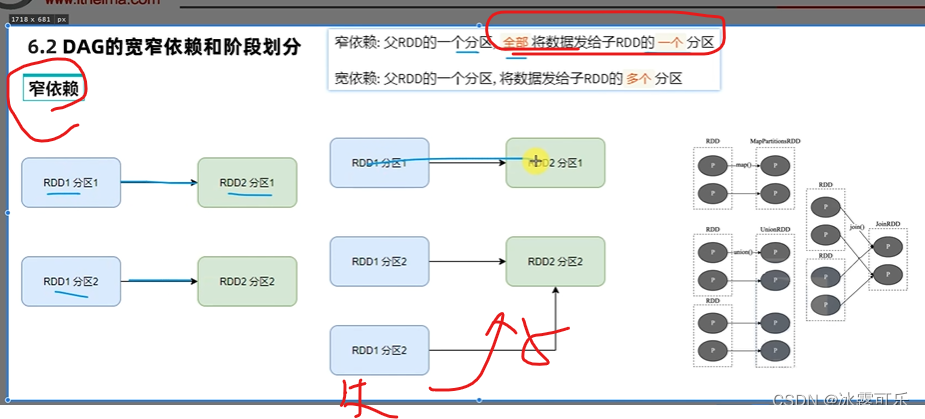
窄依赖美滋滋
线程运行在不同的executor
之间,那传输数据,可能造成网络io性能满
怎么说呢?
所以窄依赖的阶段,全部放同一个内存中计算?是不是不要传输io了
同一个线程中处理好不好?
很好
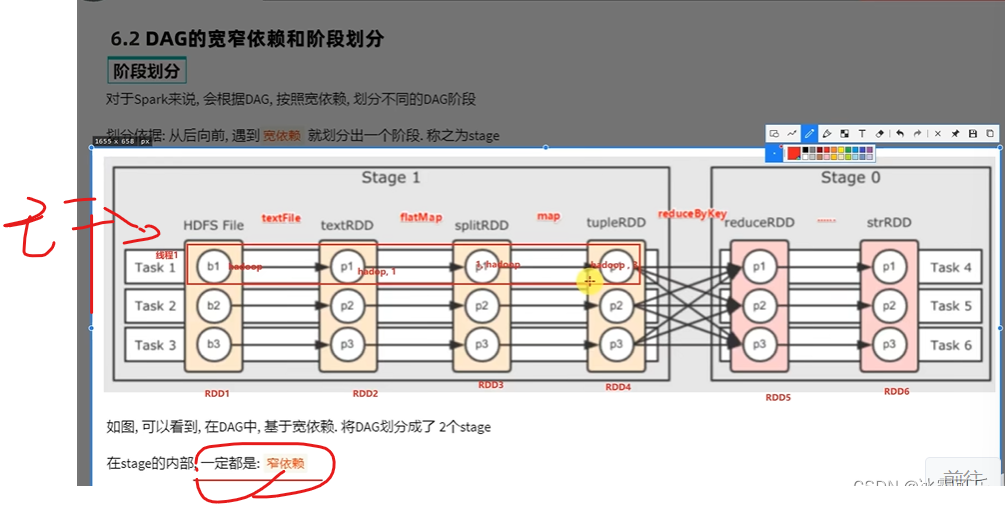
线程1全干一条线,内存中计算的一条管子,美滋滋,叫内存计算管道,叫pipeline
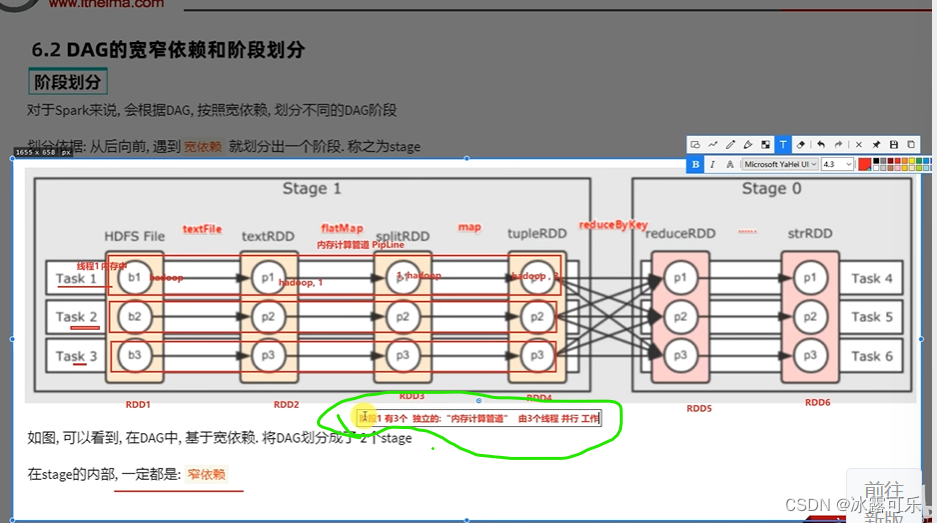
同理,右边一样
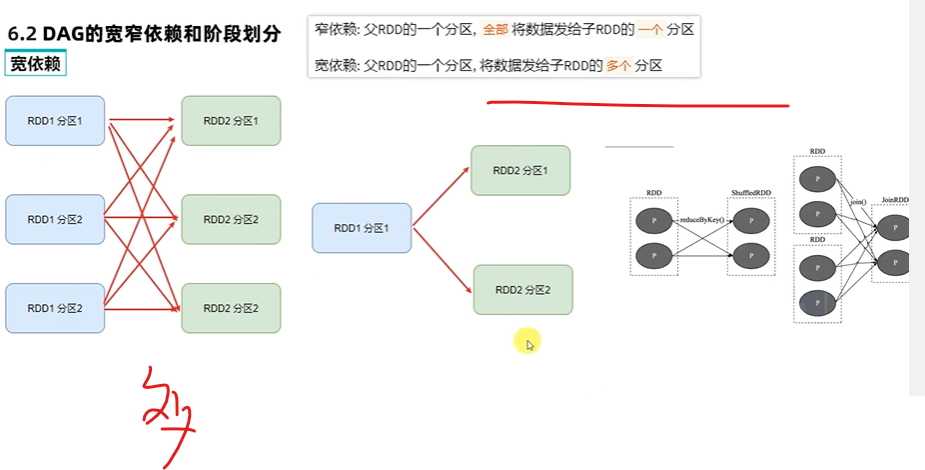
那宽依赖就必须走网络io了
或者都在同一个executor上,也是内存内部计算了【很难做到】
不得不走网络io的就得传输了,反正计算管道内部不就是美滋滋了
当然了,spark并行的优先级,是核心
内存计算是次要的
你想要全内存,知识local模式,绝对不是yarn模式
大数据做不到全内存内部计算的
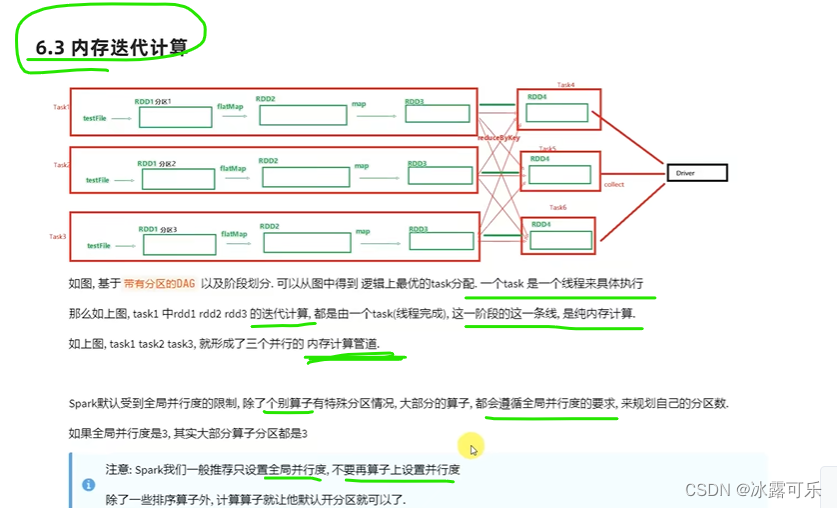
没事不要修改并行度
这样性能才能保证
懂了吧
不要乱
不要没事改分区数量
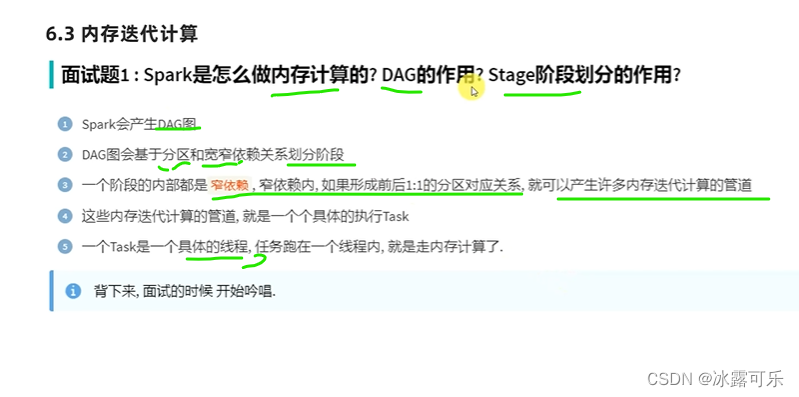
窄依赖直接做内存迭代,即内存计算管道,一个task干就完事了
不需要网络io传输,提高了性能
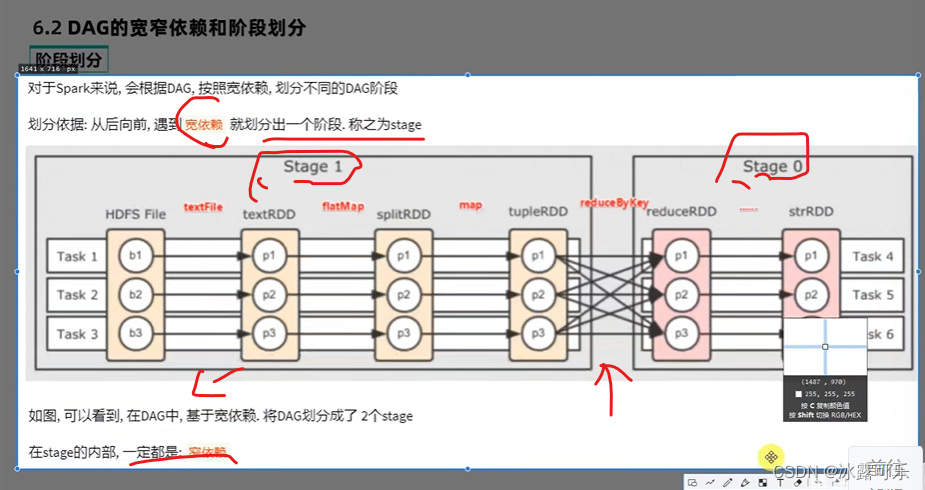
spark构建了DAG
DAG往后传输形成宽窄依赖
窄依赖内就是管道计算迭代
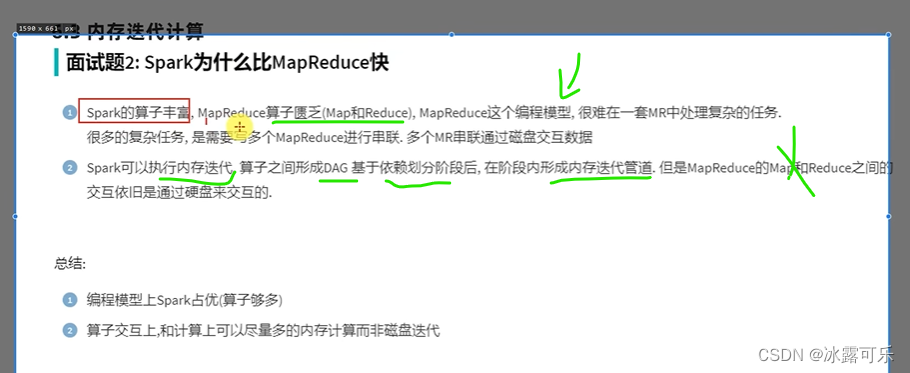
spark比MapReduce的好处就是算子多
spark有内存迭代管道,少了很多io网络传输,这性能一下子就高了
这就是面试的题目了,考试要区分好

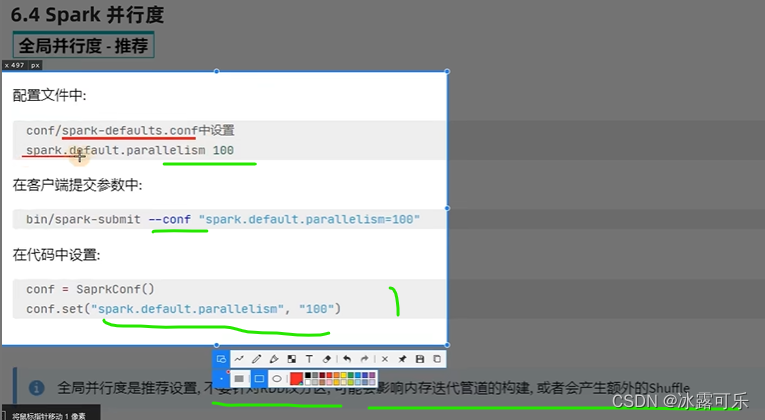
并行度,不是分区哦
最好分区就是和并行度类似

shuffle是洗牌
最好别洗网络io或者太多洗牌操作
难搞
计算复杂
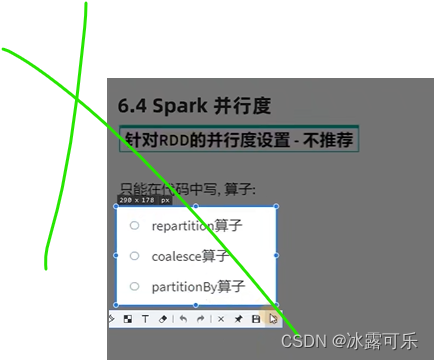
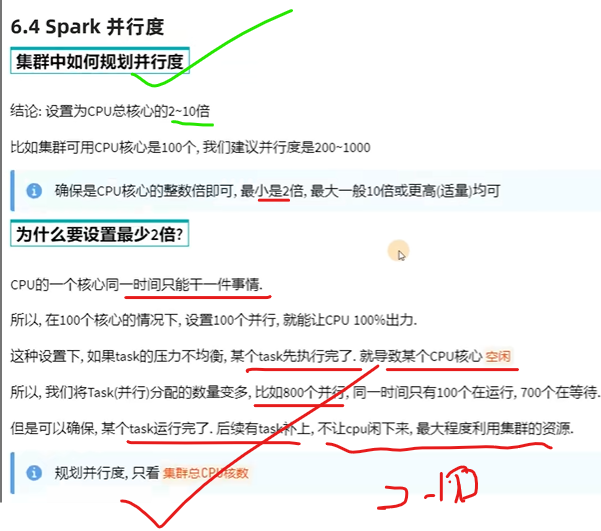
并行度是cpu数量的2–10倍
总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。