前置知识
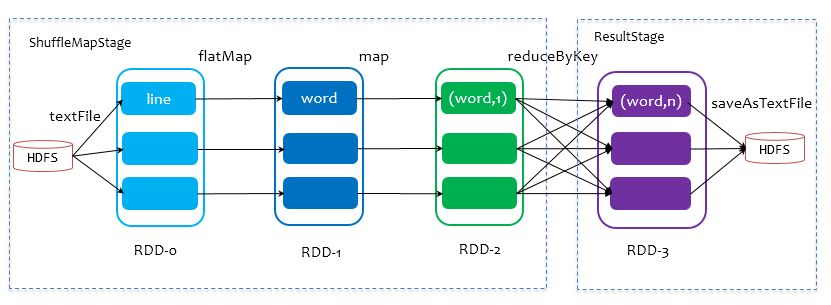
spark任务模型
- job:action的调用,触发了DAG的提交和整个job的执行。
- stage:stage是由是否shuffle来划分,如果发生shuffle,则分为2个stage。
- taskSet:每一个stage对应1个taskset.1个taskset有多个task, 由RDD的partition数据决定,并行度就是各自RDD的partition数目。
- task:同一个stage中同一个partition中的数据与处理过程,视为1个task. task从横向上看,与partition数量一致;从纵向上看,task包含1个stage中的处理过程,如下面中的mapstage中的flatmap、map、reduceBykey.
spark资源模型
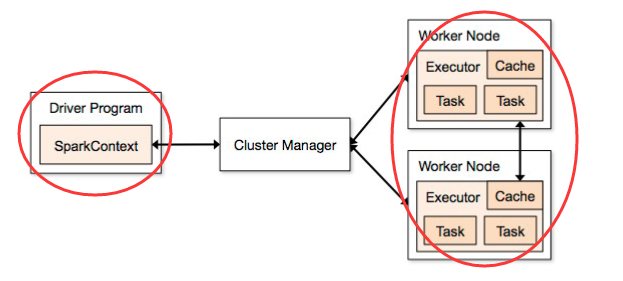
Executor是真正执行任务的进程,本身拥有若干cpu和内存,可以执行以线程为单位的计算任务,它是资源管理系统能够给予的最小单位。
yarn资源

YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
ResourceManager是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等;
NodeManager是Slave上一个独立运行的进程,负责上报节点的状态;
App Master和Container是运行在Slave上的组件,Container是yarn中分配资源的一个单位,包涵内存、CPU等等资源,yarn以Container为单位分配资源。spark executor与yarn container的关系
Running Spark Applications on YARN
When running Spark on YARN, each Spark executor runs as a YARN container. 在spark on yarn模式,每个executor运行在1个yarn container上。
- Cluster Deployment Mode
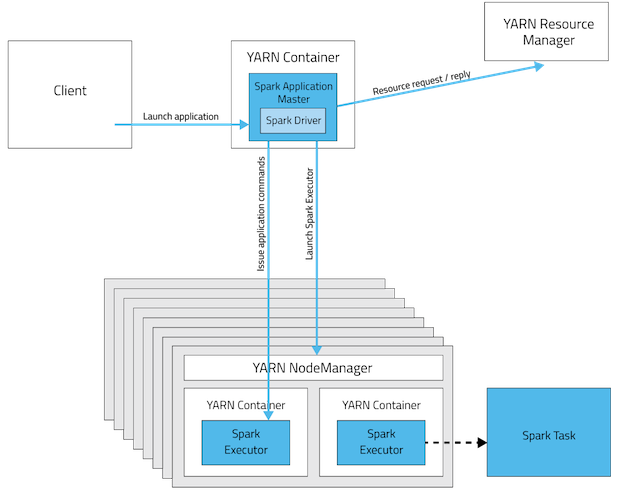
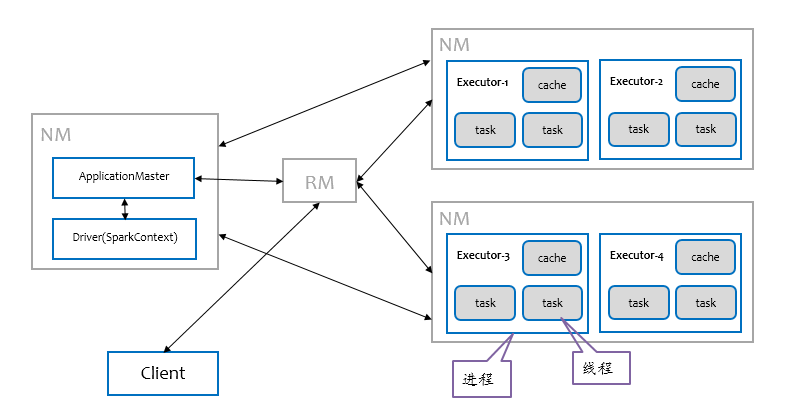
两层模型
spark的任务模型与资源模型是如何匹配?
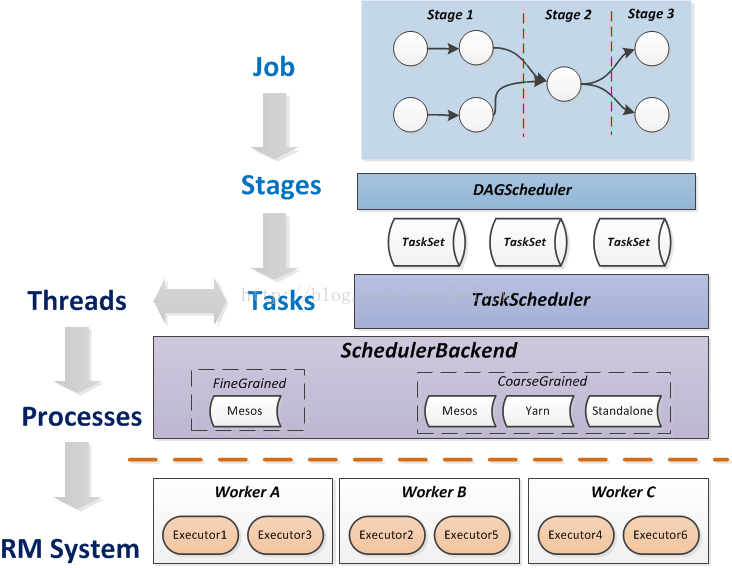
如上图所示:关键在于TaskScheduler与SchedulerBackend,由它们来适配task与executor。
spark的任务模型将提交的job分解成最小的任务单位task, 由TaskScheduler根据调度策略和task的资源申请情况来调用具体的SchedulerBackend(如yarn)。
SchedulerBackend的最小资源管理单位是executor。看workers中executros的资源“够不够”,“符不符合”task,ok的话task就被正式launch起来。注意,这里资源"够不够"是很好判断的,在TaskScheduler里设置了每个task启动需要的cpu个数,默认是1,所以只需要做核数的大小判断和减1操作就可以遍历分配下去。而"符不符合"这件事情,取决于每个tasks的locality设置。
task的locality有五种,按优先级高低排:PROCESS_LOCAL,NODE_LOCAL,NO_PREF,RACK_LOCAL,ANY。也就是最好在同个进程里,次好是同个node(即机器)上,再次是同机架,或任意都行。task有自己的locality,如果本次资源里没有想要的locality资源,怎么办呢?spark有一个spark.locality.wait参数,默认是3000ms。对于process,node,rack,默认都使用这个时间作为locality资源的等待时间。所以一旦task需要locality,就可能会触发delay scheduling。
SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行。
调度策略
- FIFO(默认): 谁先提交谁先执行,后面的任务需要等待前面的任务执行。
- FAIR: 支持在调度池中为任务进行分组,不同的调度池权重不同,任务可以按照权重来决定执行顺序。