概述
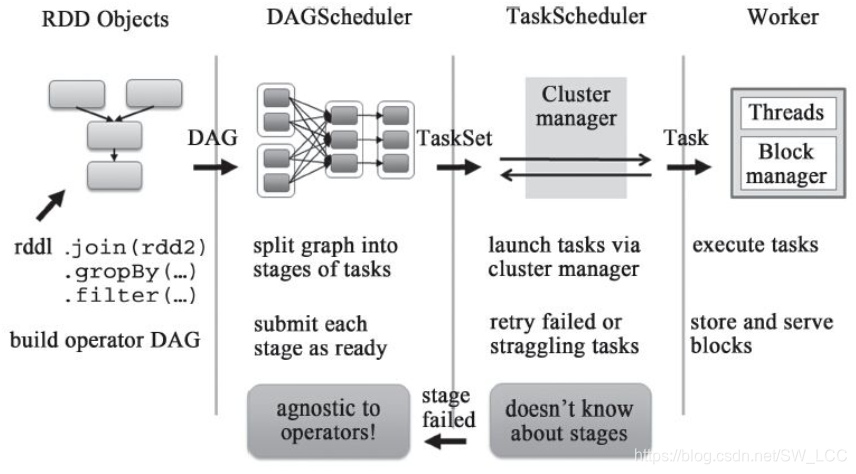
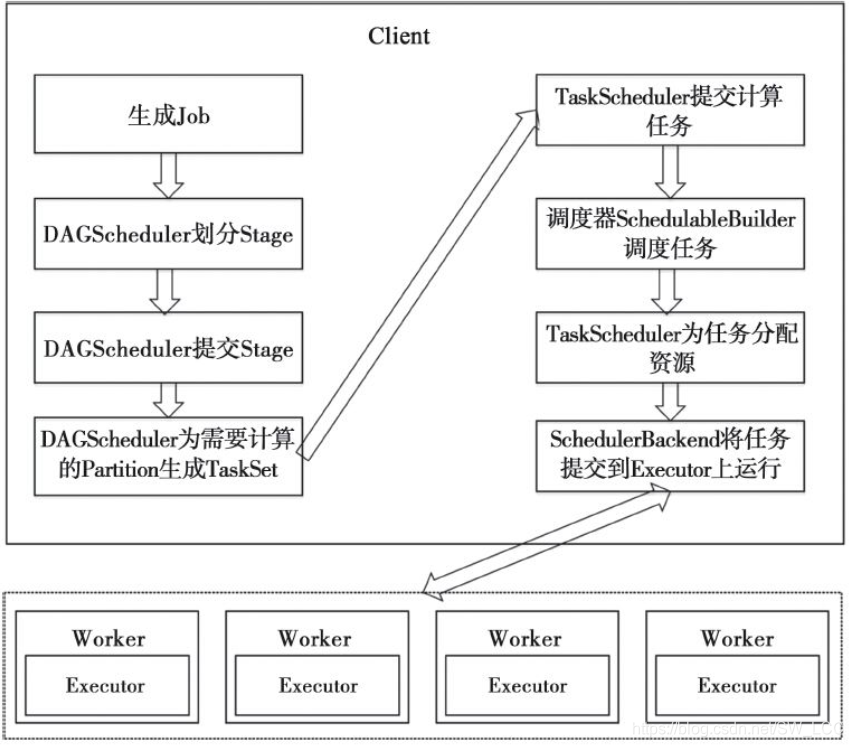
任务调度模块分为DAGScheduler和TaskScheduler两个组件,将用户提交的job划分不同阶段并提交到集群。
DAGScheduler分析用户提交的应用, 并根据计算任务的依赖关系建立DAG, 然后将DAG划分为不同的Stage(阶段) , 其中每个Stage由可以并发执行的一组Task构成, 这些Task的执行逻辑完全相同, 只是作用于不同的数据。 而且DAG在不同的资源管理框架(即部署方式, 包括Standalone、 Mesos、 YARN等) 下的实现是相同的。
在DAGScheduler将这组Task划分完成后, 会将这组Task提交到TaskScheduler。 TaskScheduler通过Cluster Manager在集群中的某个Worker的Executor上启动任务。 在Executor中运行的任务, 如果缓存中没有计算结果, 那么就需要开始计算, 同时, 计算的结果会回传到Driver或者保存在本地。 在不同的资源管理框架下, TaskScheduler的实现方式是有差别的, 但是最重要的实现是org.apache.spark.scheduler.TaskSchedulerImpl。 对于Local、 Standalone和Mesos来说, 它们的TaskScheduler就是TaskSchedulerImpl; 对于YARN Cluster和YARN Client的TaskScheduler的实现也是继承自TaskSchedulerImpl。
整体框架
Scheduler实现
GAGScheduler实现runJob,对用户提交的job做处理,包括stage划分,Task生成。
DAGScheduler创建
DAGTaskScheduler和TaskScheduler都在SparkContext创建
DAGScheduler
private[spark]
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = SystemClock)
extends Logging {
}
TaskScheduler
def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
}
Job提交
job的调用栈如下:
- org.apache.spark.rdd.RDD#count
- org.apache.spark.SparkContext#runJob
- org.apache.spark.scheduler.DAGScheduler#runJob
- org.apache.spark.scheduler.DAGScheduler#submitJob
- org.apache.spark.scheduler.DAGSchedulerEventProcessActor#receive
(JobSubmitted ) - org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
DAGScheduler的实现如下:
val waiter = submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler,properties)
waiter.awaitResult() match {
case JobSucceeded => {
logInfo("Job %d finished: %s, took %f s".format(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
}
case JobFailed(exception: Exception) =>
logInfo("Job %d failed: %s, took %f s".format(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
throw exception
}
其中submitJob会生成一个JobID,且生成一个JobWaiter的实例来监听Job的执行。
JobWaiter会监听Job的执行状态, 而Job是由多个Task组成的, 因此只有Job的所有Task都成功完成, Job才标记为成功; 任意一个Task失败都会标记该Job失败。
Stage划分
对于需要经过shuffle的RDD,是需要划分stage将DAG分为不同的阶段进行计算。stage有依赖关系,不能进行并行计算,后面的stage依赖与前面的stage。
1.划分依据
对RDD的划分要看该RDD是宽依赖还是窄依赖。如果是窄依赖则个体个Partition依赖固定的parentRDD的Partition,因此不同的Partition可以用Task并行计算。宽依赖急需要shuffle,所以只有parent RDD的Partition Shuffle完成才会生成新的Partition,Task才接着进行处理。
因此宽依赖是DAG的Stage的划分依据。
如图:
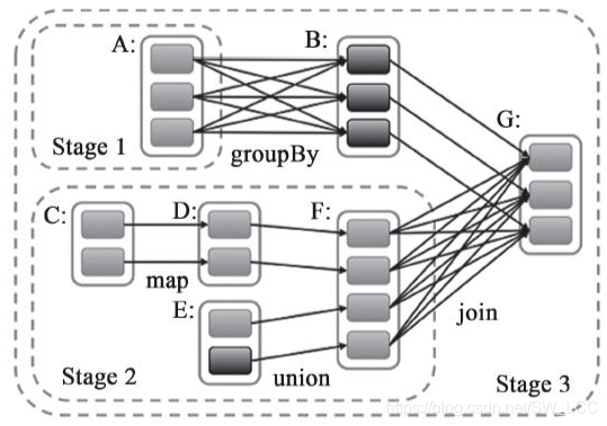
Stage划分从最后触发Action的RDD开始。
