《基于caffe的表情识别》系列文章索引:http://blog.csdn.net/pangyunsheng/article/details/79434263
一、caffe网络模型规则
在caffe中,最常见的就是搭建一个卷积神经网络模型来解决一个识别问题,就如本例中,我们就是在alexnet上做适当修改,得到我们的卷积神经网络模型,在这里我简单称呼其为FacialNet,通过人脸表情数据训练,得到一个最终模型,从而能够识别人脸表情。
那么在实验过程中,我们需要编写或修改的主要有三个文件,如下图所示:
第一个文件deploy.prototxt是后面我们测试用的网络结构,这个后面文章会详细讲,这里不多说。
第二个文件facialnet_solver.prototxt是有关训练过程的一些参数配置,本篇会详细讲。
第三个文件train_val.prototxt是训练时用到的网络结构,本篇会详细讲。
注:三个文件的名字是我随意命名的,可以随意修改,但是注意.prototxt后缀不要改。
本篇文章我们只关注第二、三个文件。首先我们要搭建好训练时的网络结构(也就是有多少卷积层、池化层、全连接层,初始化每一层的一些参数等等),然后对训练过程配置一些参数(学习率、动量、学习率衰减等等),就可以拿去训练了,其实整个思路很简单,但是如果你之前对caffe一点都不了解,刚一上来就看到这些文件或许会有些迷茫,也可能不懂数据是如何在每一层之间传输的,经过每一层后又发了怎么样的变化等等,所以之前建议大家最好先跑一下mnist数据集,看看训练日志,再来继续看后面的内容。下面我会详细说明这两个文件中的内容。
二、搭建网络结构
1.网络结构说明
网络是在AlexNet上修改得到,减少了3个卷积层,现在的网络包含3个卷积层、3个池化层和3个全连接层。
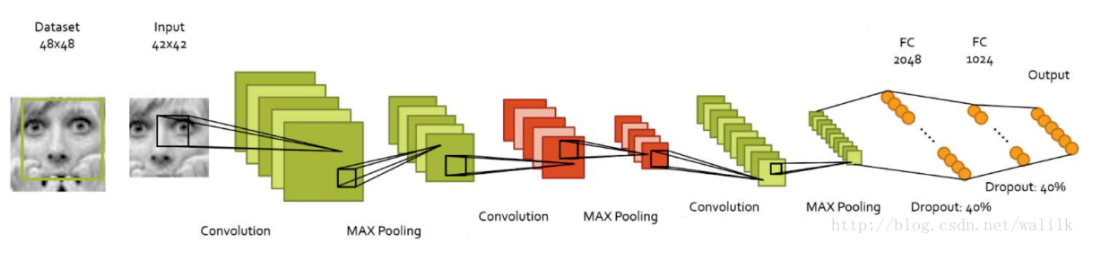
细节如下:
FacialNet model architecture
| type | kernel_size | kernel_num | stride | pad | output | dropout |
| Data | 42 x 42 x 1 | |||||
| Convolution | 5 x 5 | 32 | 1 | 2 | 42 x 42 x 32 | |
| Pooling | 3 x 3 | 2 | 21 x 21 x 32 | |||
| Convolution | 4 x 4 | 32 | 1 | 1 | 20 x 20 x 32 | |
| Pooling | 3 x 3 | 2 | 10 x 10 x 32 | |||
| Convolution | 5 x 5 | 64 | 1 | 2 | 10 x 10 x 64 | |
| Pooling | 3 x 3 | 2 | 5 x 5 x 64 | |||
| InnerProduct | 1 x 1 x 2048 | 0.5 | ||||
| InnerProduct | 1 x 1 x 1024 | 0.5 | ||||
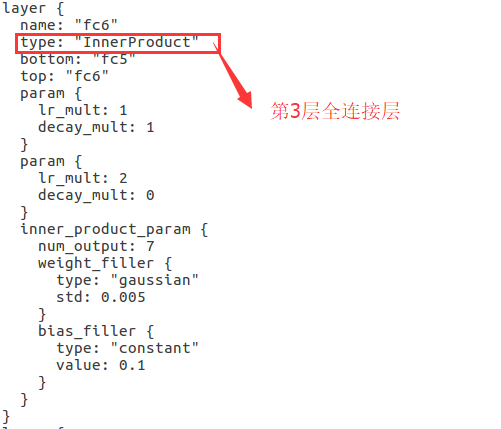
| InnerProduct | 1 x 1 x 7 |
type:网络中每一层的类型。我们的网络首先是一个Data层,然后紧跟3个卷积层和3个池化层,最后是3个全连接层
kernel_size:卷积核的尺寸
kernel_num:卷积核的个数
stride:步长,即卷积核每次移动的长度
pad:扩充边缘,使得图像经过卷积之后得到的特征图象不会改变尺寸
output:经过该层处理后,输出结果的维度
dropout:这个不多说了,减少过拟合
得到output的计算过程:
1)在Data层,我们的原始图像数据是48*48*1的,其中1代表只有一个通道,因为原始图像是灰度图像。经过一个裁剪操作后,将48*48的图像裁剪成42*42的大小(裁剪操作在上述表格中没有体现,后面在介绍Data层代码时会介绍到),所以Data层的output为42*42*1。
2)在第1个Convolution层,pad为2,即图像的宽高各增加2个像素,特征图像尺寸变为46*46,经过卷积之后,特征图像尺寸变为(46-5)/1+1=42,即42*42,发现经过卷积之后图像尺寸还是42*42没有改变,这其实是pad=2的功劳。由于卷积核的个数是32,因此在第1个Convolution层,output为42*42*32。
这里介绍一个特征图像的计算公式:特征图像尺寸=[(原特征图像尺寸-卷积核尺寸)/步长]+1
3)在第1个Pooling层,使用上面公式计算得到特征图像尺寸=(42-3)/2+1=20.5,进1得到21,经过池化层的特征图像大小为21*21。该层的output为21*21*32。
4)后面的第2个第3个Convolution层和Pooling层的计算方法跟上面相同,不再过多介绍。
5)全连接层的output不再过多介绍。
上面简单介绍了神经网络的结构,得到output的过程可能比较繁琐,需要读者有一定的卷积神经网络基础。output是网络自己得出的,并不需要我们手动来规定,这里介绍一下每一层得到的数据结果(也就是output)是为了让读者理解更清晰卷积神经网络的工作原理,不然下次自己去搭建一个网络时还是无从下手。至于说为什么第1个卷积层的卷积核尺寸是5x5,第2个是4x4等等这类的问题,只能说这是人们不断实验得到的比较理想的结果,如果有时间可以改变这些取值,看看最后的结果有什么影响,这里就不多说了。
2.编写train_val.prototxt

mean_file: "faceR/lmdb/meandata.binaryproto"
source: "faceR/lmdb/fer2013_train_lmdb"
(上图中的路径是之前项目的路径,这里截图时忘改了,不要照着抄上去)

注:这里的mean_file和source仍需要改。




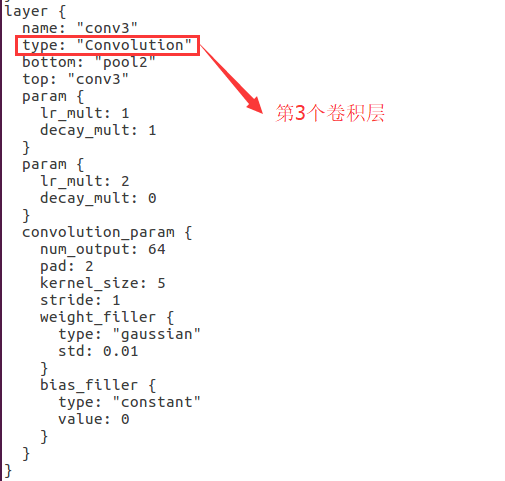

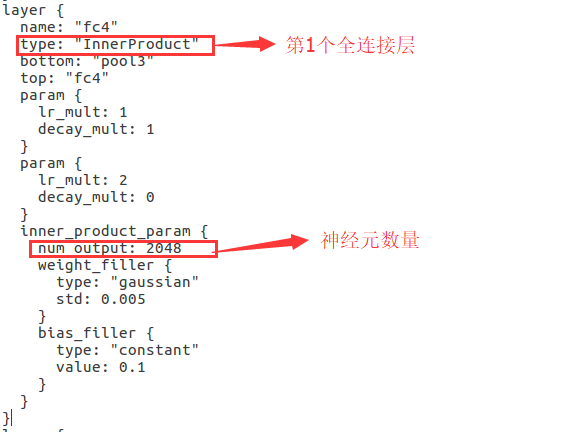




可以说讲的比较细了,但可能大家看到现在头都大了,我把本项目中用到的网络文件都放在下面的连接里了,所有参数都配置好了,都是我们这个实验的参数,只需要大家把train和test阶段的mean_file和source设置成自己的路径就行了。
3.使用画图工具画出网络结构
在这里我使用caffe-python中的画图工具画出了我们搭建的网络模型,指令如下:
python caffe/python/draw_net.py faceR/model/train_val.prototxt faceR/model/facialnet.png 画出的网络结构图:

三、配置网络训练参数
网络训练参数保存在facialnet_solver.prototxt文件中,同样在上面给出的链接里,也有这个文件,但仍需要修改部分代码,下图中蓝色字体的为读者需要修改的地方。
至此,搭建网络结构内容全部结束,下一篇将介绍如何用高性能的云服务来训练网络。
