第一问:YOLOv4算法的网络整体架构
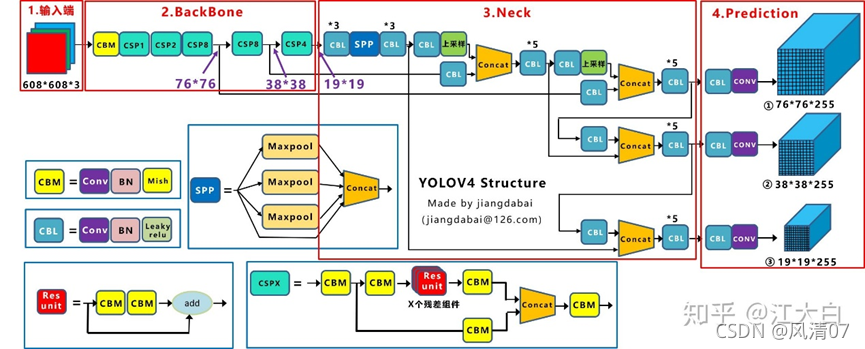
图片来源:https://zhuanlan.zhihu.com/p/172121380
如图所示,YOLOv4的网络架构整体分为三部分:BackBone(主干网络)、Neck、Prediction(预测)。
其中主干网络包括CBM和CSP结构。CBM由Conv+BN+Mish组成。CSP又由多个CBM以及残差组件res unit组成。
Neck包括CBL、SPP、上采样、Concat结构。CBL由Conv+BN+Leaky relu组成。而SPP又由多个池化层maxpool和Concat组成。 Prediction包括CBL和conv结构。
第二问:网络结构中各组件、结构的原理及作用是什么?
- Mish激活函数:激活函数是用来提高网络的学习能力,提升梯度的传递效率。常用的激活函数有多种。其中Mish激活函数的计算复杂度比ReLu高很多,因此,当计算资源不充足时可以考虑用LeakyRelu代替Mish。(由上图我们可以知道,Neck中使用的就是CBL,而主干网络中依旧采用的CBM,L和M指的就是LeakyRelu和Mish激活函数。)
参考学习文章链接:https://blog.csdn.net/EasonCcc/article/details/108879514- BN:BN是batch normalization的缩写,中文翻译过来是批量标准化处理(或者是归一化批处理)。BN的作用就是每一层的数据在进入神经元进行激活函数的训练前进行批量的标准化处理,使得数据服从高斯分布。(疑问:什么是标准化处理、什么是高斯分布)数据经过每一层的运算后都发生了较大的变化,而归一化减少了变化的程度,使得数据又一次分布在函数的中间,通过两个参数(γ、β)可以还原数据的原始特征。
PS: a) 什么是归一化处理?
数据的标准化就是将数据按比例缩放,使其落入一个小的特定区间。在某些比较以及评价的指标处理中经常会用到标准化处理,取出数据的单位限制,将其转化为无量纲化的纯数值,以便于不同单位或两级的指标能够进行比较和加权。其中最典型的数据标准化处理方法就是归一化处理,就是将数据统一映射到[0,1]区间上。
那归一化处理有什么优势吗?有的:首先。对数值类型的特征做归一化可以将所有特征都统一到一个大致相同的数值区间内。(如果此时你问我为什么要统一到一个大致相同的数值区间内的话,我想应该是便于对数据处理,而且小范围的区间更加便于提高模型的收敛速度,但是我想至于为什么要归一化还是得具体问题具体分析。)其次,归一化让不同维度之间的特征在数值上具有了可比较性,可以大大提高分类器的准确性。
**那么哪些模型需要做归一化处理呢?**首先。需要使用梯度下降的模型要做归一化处理。这是因为不做归一化会是收敛的路径呈Z字型下降,导致收敛路径太慢,而且不容易找到最优解。因此,线性回归、逻辑回归、GDBT(gradient boosting decision tree:梯度提升决策树。这是一种迭代的决策树算法,该算法由多种决策树组成,所有树的答案累加起来作为最终答案。用来最回归预测,调整后也可以用于分类(它在提出之初就和SVM一起被认为是泛化能力较强的算法(泛化能力可以理解为对新鲜样本数据的适应能力))。
GDBT学习文章:https://www.jianshu.com/p/005a4e6ac775)等这些模型都需要做归一化处理。(什么是梯度下降?梯度的本意就是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,就是函数在该点处沿着该方向(梯度的方向)变化最快,变化率最大(为该梯度的模)。)
所以综上所述,归一化可以加快梯度下降求最优解的速度,也有可能提高模型检测的精度。
b) 什么是高斯分布?
高斯分布就是正态分布,还称为常态分布。某度提供的高斯分布图:
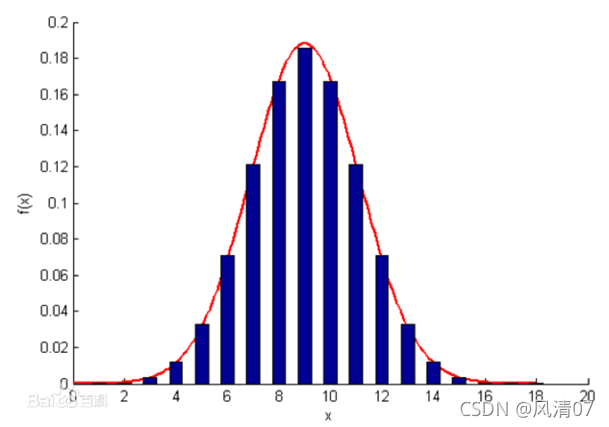
那为什么要将数据转化为服从高斯分布呢? 有的博主说在进行机器学习或者深度学习训练的时候,往往希望数据越接近高斯分布越好,这样对于训练效果会有明显的提升。(显然,此时我还不是很理解这句话,为什么说这样训练效果就会有明显的提升?但是,我觉得可以从高斯分布的特点入手。)
高斯分布与其他的很多分布不同,高斯分布进行适当的变换之后,仍然是高斯分布。比如说:两个高斯分布之积仍然是高斯分布;两个独立的服从高斯分布的随机变量之和服从高斯分布。对一个高斯分布进行高斯卷积还是高斯分布;高斯分布经过傅里叶变换后仍然是高斯分布。另外,高斯分布还有一个明显的特征就是简洁。它的均值、中值、众数都相同,只需要两个参数就可以确定整个分布。我现在就暂且认为基于以上以及其他的一些原因我们在训练时总是倾向于让数据服从高斯分布。
3. 卷积模块(CML、CML):这是网络结构的一个基本组件,由卷积层+BN层+Leaky relu激活层组成(Conv+BN+Leaky relu/Mish),到后来大多情况三者都绑定在了一起(出最后一层卷积外)。 卷积层的作用:卷积是一种有效提取图片特征的方法。一般用一个正方形卷积核遍历图片上的每一个像素点。图片与卷积核重合区域内相对应的每一个像素值,乘卷积核内相对应点的权重,然后求和,再加上偏置后,最后得到输出图片中的一个像素值。
而图片分为灰度图片和彩色图片,卷积核也可以分为单个和多个,因此卷积操作也可以分为单通道输入,单卷积核;多通道输入,单卷积核;多通道输入,多卷积核(深度神经网络中最常见的形式)。
4. 池化层:卷积层中通过调节步长参数s实现特征图的高宽成倍缩放,从而降低了网络的参数量。另一种方法是利用一种专门的网络层来实现尺寸缩减功能,这个网络层就是池化层(pooling layer)。
池化层同样基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。 通常用到两种池化进行下采样:一种是最大池化(Max pooling),这也是我们YOLOv4的模型中用到的,其含义就是从局部相关元素集中选取最大的一个元素值。另一种是平均池化(average pooling),其含义是从局部相关元素集中计算平均值并返回。5. 下采样与上采样:
a)了解到的采样可用于通信领域,通过对数字信号进行重采,将重采时的采样率与原来获得该数字信号的采样率作比较,大于原信号的称为上采样,小于原信号的称为下采样,而上采样的实质也就是内插或者差值。显然,我们这里要讨论的采样不是应用于通信领域,而是应用在图像上。对图像进行下采样的话就是缩小图像,又称为降采样,这样做的目的一般有:一是使得图像符合显示区域的大小,二是生成对应图像的缩略图。这样看来,上采样就是放大图像了,或者称为图像插值,这样做的目的主要是放大原图像,从而可以显示在更高分辨率的显示设备上。(但是对于图像的缩放操作并不能带来更多关于该图像的信息,因此图像的质量就会收到影响。不过,也确实存在一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量。
b) 那么采样的原理简单来说是怎么回事呢?对于下采样的原理其实就是得到图像宽高的公约数,再分别用宽高除以公约数(这里仅是简单理解)。上采样的原理就是采用内插值方法,就是在原有图像像素的基础上在像素点之间采用合适的差值算法插入新的元素。差值算法有传统差值,基于边缘图像的差值,基于区域的图像差值等等。
6. Concat:concat就是张量拼接,它和add结构不一样的是,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。拼接的目的就是通过特征融合让模型同时利用到提取的浅层特征和深层特征。
7. 残差模块(res):残差结构可以保证网络结构在很深的情况下仍然可以收敛,使模型能训练下去。(可以深入学习残差结构的文章:https://zhuanlan.zhihu.com/p/106764370)
学习参考文章链接:https://blog.csdn.net/wjinjie/article/details/105016766
https://zhuanlan.zhihu.com/p/105997357