基于Keras框架搭建并训练了卷积神经网络模型,用于人脸表情识别,训练集和测试集均采用fer2013数据集。
达到如下效果:




整个表情识别系统分为两个过程:卷积神经网络模型的训练 与 面部表情的识别。
1.卷积神经网络模型的训练
使用公开的数据集一方面可以节约收集数据的时间,另一方面可以更公平地评价模型以及人脸表情分类器的性能,因此,使用了kaggle面部表情识别竞赛所使用的fer2013人脸表情数据库。图片统一以csv的格式存储。首先用python将csv文件转为单通道灰度图片并根据标签将其分类在不同的文件夹中。
fer2013数据集链接: https://pan.baidu.com/s/1M6XS8ovXbn8-UfQwcUnvVQ 密码: jueq
代码如下:
先将其根据用途label分成三个csv(分别是训练集、测试集、验证集)
import csv
import os
database_path = 'E:/Python/DeepLearning/emotion_classifier/fer2013/'
datasets_path = './fer2013/'
csv_file = database_path+'fer2013.csv'
train_csv = datasets_path+'train.csv'
val_csv = datasets_path+'val.csv'
test_csv = datasets_path+ 'test.csv'
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
print(header)
rows = [row for row in csvr]
trn = [row[:-1] for row in rows if row[-1] == 'Training']
csv.writer(open(train_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + trn)
print(len(trn))
val = [row[:-1] for row in rows if row[-1] == 'PublicTest']
csv.writer(open(val_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + val)
print(len(val))
tst = [row[:-1] for row in rows if row[-1] == 'PrivateTest']
csv.writer(open(test_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + tst)
print(len(tst))将其转换为单通道灰度图
import csv
import os
from PIL import Image
import numpy as np
datasets_path = r'.\fer2013'
train_csv = os.path.join(datasets_path, 'train.csv')
val_csv = os.path.join(datasets_path, 'val.csv')
test_csv = os.path.join(datasets_path, 'test.csv')
train_set = os.path.join(datasets_path, 'train')
val_set = os.path.join(datasets_path, 'val')
test_set = os.path.join(datasets_path, 'test')
for save_path, csv_file in [(train_set, train_csv), (val_set, val_csv), (test_set, test_csv)]:
if not os.path.exists(save_path):
os.makedirs(save_path)
num = 1
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
for i, (label, pixel) in enumerate(csvr):
pixel = np.asarray([float(p) for p in pixel.split()]).reshape(48, 48)
subfolder = os.path.join(save_path, label)
if not os.path.exists(subfolder):
os.makedirs(subfolder)
im = Image.fromarray(pixel).convert('L')
image_name = os.path.join(subfolder, '{:05d}.jpg'.format(i))
#print(image_name)
im.save(image_name)最终效果:

每个文件夹里都是:

里面则是:

0-6文件夹分别label为:
angry ,disgust ,fear ,happy ,sad ,surprise ,neutral
根据google的论文Going deeper with convolutions中获得灵感,在输入层之后加入了1*1的卷积层使输入增加了非线性的表示、加深了网络、提升了模型的表达能力,同时基本不增加计算量。根据VGG网络的想法,尝试将5*5网络拆分但最后效果并不理想,最终网络模型结构如下:
| 种类 |
核 |
步长 |
填充 |
输出 |
丢弃 |
| 输入 |
48*48*1 |
||||
| 卷积层1 |
1*1 |
1 |
48*48*32 |
||
| 卷积层2 |
5*5 |
1 |
2 |
48*48*32 |
|
| 池化层1 |
3*3 |
2 |
23*23*32 |
||
| 卷积层3 |
3*3 |
1 |
1 |
23*23*32 |
|
| 池化层2 |
3*3 |
2 |
11*11*32 |
||
| 卷积层4 |
5*5 |
1 |
2 |
11*11*64 |
|
| 池化层3 |
3*3 |
2 |
5*5*64 |
||
| 全连接层1 |
1*1*2048 |
50% |
|||
| 全连接层2 |
1*1*1024 |
50% |
|||
| 输出 |
1*1*7 |
def build_model4(self):
self.model=Sequential()
self.model.add(Conv2D(32,(1,1),strides=1,padding='same',input_shape=(img_size,img_size,1)))
self.model.add(Activation('relu'))
self.model.add(Conv2D(32,(5,5),padding='same'))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2,2)))
self.model.add(Conv2D(32,(3,3),padding='same'))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2,2)))
self.model.add(Conv2D(64,(5,5),padding='same'))
self.model.add(Activation('relu'))
self.model.add(MaxPooling2D(pool_size=(2,2)))
self.model.add(Flatten())
self.model.add(Dense(2048))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(1024))
self.model.add(Activation('relu'))
self.model.add(Dropout(0.5))
self.model.add(Dense(num_classes))
self.model.add(Activation('softmax'))
self.model.summary()在训练过程中使用ImageDataGenerator实现数据增强,并通过flow_from_directory根据文件名划分label:
train_datagen = ImageDataGenerator(
rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip=True)
#归一化验证集
val_datagen = ImageDataGenerator(
rescale = 1./255)
eval_datagen = ImageDataGenerator(
rescale = 1./255)
#以文件分类名划分label
train_generator = train_datagen.flow_from_directory(
root_path+'/train',
target_size=(img_size,img_size),
color_mode='grayscale',
batch_size=batch_siz,
class_mode='categorical')优化算法选择了SGD
sgd=SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
#optimizer='rmsprop',
metrics=['accuracy'])而激活函数选择了硬饱和的ReLU。因为tanh和sigmoid在训练后期,产生了因没有进行归一化而梯度消失训练困难的问题。如下图:
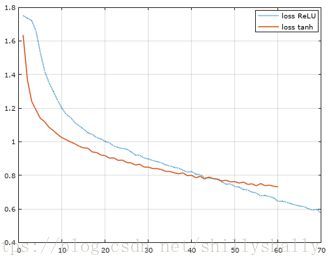
批尺寸在多次尝试之后最终选择了128,迭代50次(在这之后val_loss呈上升趋势,val_acc呈下降趋势)
| 批尺寸 |
256 |
128 |
64 |
32 |
1 |
| 每次迭代的步数 |
100 |
200 |
400 |
800 |
25600 |
| 一次迭代的时间 |
205s |
118s |
76s |
58s |
大于30min |
| 迭代的次数 |
50 |
50 | 50 |
50 |
---- |
| 测试集准确率 |
0.679 |
0.684 |
0.675 |
0.651 |
---- |
2.人脸表情识别模块
使用公开库opencv实现人脸识别,然后对识别到的人脸进行了裁切以及翻转,处理之后将图像进行几何归一化,通过双线内插值算法将图像统一重塑为48*48像素。
def face_detect(image_path):
rootPath='E:\Python\Opencv\opencv\sources\data\haarcascades\\'
cascPath=rootPath+'haarcascade_frontalface_alt.xml'
faceCasccade=cv2.CascadeClassifier(cascPath)
#load the img and convert it to bgrgray
#img_path=image_path
img=cv2.imread(image_path)
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#face detection
faces = faceCasccade.detectMultiScale(
img_gray,
scaleFactor=1.1,
minNeighbors=1,
minSize=(30,30),
)
#print('img_gray:',type(img_gray))
return faces,img_gray,img
然后使用之前训练好的模型进行预测
def predict_emotion(face_img):
face_img=face_img*(1./255)
resized_img=cv2.resize(face_img,(img_size,img_size))#,interpolation=cv2.INTER_LINEAR
rsz_img=[]
rsh_img=[]
results=[]
#print (len(resized_img[0]),type(resized_img))
rsz_img.append(resized_img[:,:])#resized_img[1:46,1:46]
rsz_img.append(resized_img[2:45,:])
rsz_img.append(cv2.flip(rsz_img[0],1))
#rsz_img.append(cv2.flip(rsz_img[1],1))
rsz_img.append(resized_img[0:45,0:45])
rsz_img.append(resized_img[2:47,0:45])
rsz_img.append(resized_img[2:47,2:47])
i=0
for rsz_image in rsz_img:
rsz_img[i]=cv2.resize(rsz_image,(img_size,img_size))
#=========================
#cv2.imshow('%d'%i,rsz_img[i])
i+=1
for rsz_image in rsz_img:
rsh_img.append(rsz_image.reshape(1,img_size,img_size,1))
i=0
for rsh_image in rsh_img:
list_of_list = model.predict_proba(rsh_image,batch_size=32,verbose=1)#predict
result = [prob for lst in list_of_list for prob in lst]
results.append(result)
return results通过实验证明,该方法可以提高表情识别分类器在空间上对局部位移和轻微形变的鲁棒性,可以有效提高表情识别系统分类的准确率。
| 模型 |
模型1 |
模型2 |
模型3(最终采用的模型) |
模型4 |
| 处理前的准确率 |
65.5 |
62.3 |
68.4 |
67.37 |
| 处理后的准确率 |
67.6 |
64.1 |
70.2 |
69.4 |
最终模型在测试集上的准确度为70.2%。
到这里整个人脸表情识别系统就算完成了。
3.效果展示
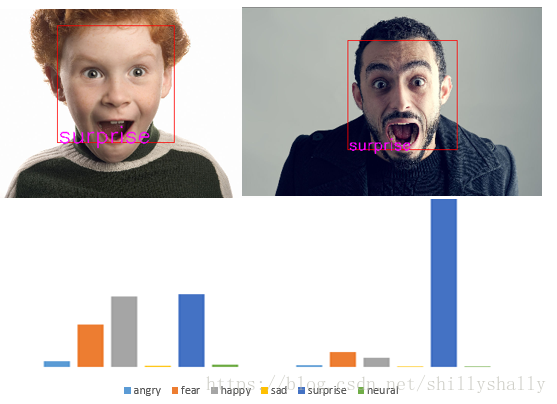
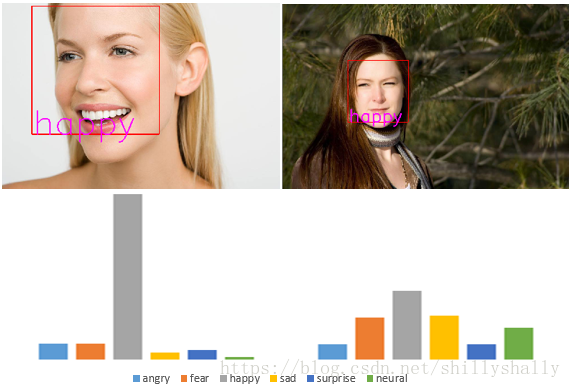

最后附上实验环境
PC:联想y50-70
系统:win10
语言:python3.6
显卡:gtx860m