《基于caffe的表情识别》系列文章索引:http://blog.csdn.net/pangyunsheng/article/details/79434263
一、数据集介绍
在本实验中我采用的数据集是fer2013人脸表情数据集。fer2013,即Kaggle facial expression recognition challenge dataset,是目前较大的人脸表情识别公开数据库。
该数据库共包含35887张人脸图片,其中训练集28709张、验证集3589张、测试集3589张。数据库中的图片均为灰度图片,大小为48*48像素,样本被分为0=anger(生气)、1=disgust(厌恶)、2=fear(恐惧)、3=happy(开心)、4=sad(伤心)、5=surprised(惊讶)、6=normal(中性)七类,各种类型分布基本均匀。
数据分布(训练集):angry:3995 、disgust:436 、fear:4097 、happy:7215 、sad:4830 、surprise:3171 、normal:4965
二、数据集处理
1.下载数据集
fer2013数据库实际为kaggle一个比赛项目提供的数据,官方给出的文件格式为csv,我手动将其转换成了图片格式,提供下面链接供大家下载。
https://pan.baidu.com/s/1i6p40jb
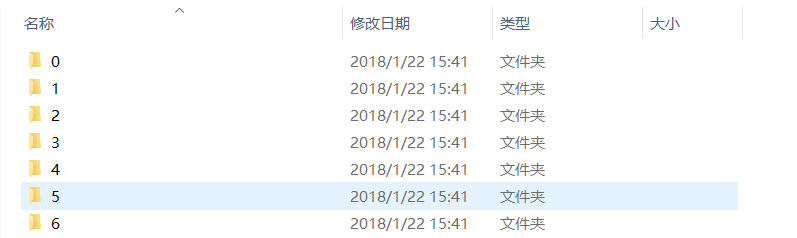
下载完成后解压得到三个目录,分别是训练集、验证集和测试集的图片数据,每个目录下都有7个子目录,分别存储了7类不同表情的图片数据。

2.准备数据
首先我创建了一个名为faceR的文件夹,用来存放该实验用到的所有文件和数据,然后在该目录下创建了一个名为data的文件夹用来存放我们的数据集,并将刚刚下载的三个文件夹(训练集、验证集、测试集)放到data目录下。

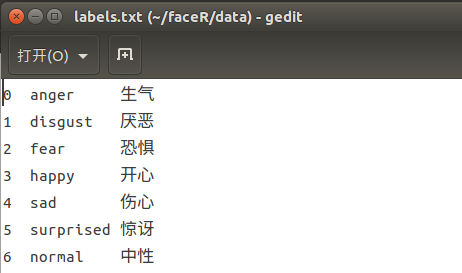
1)准备labels.txt文件,表示分类序号于分类对应关系
在data目录下创建一个空白文档,取名为labels.txt,并输入下面内容:
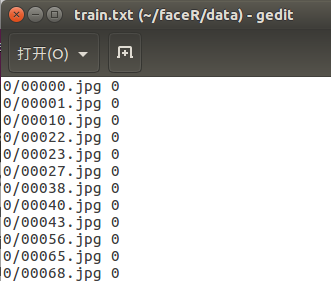
2)准备train.txt,标明训练图片路径及其对应分类,路径和分类序号直接用空格分隔
在data目录下使用下面指令,可以使train目录下的7类训练集图片数据生成train.txt文件
ls train/0 | sed "s:^:0/:" | sed "s:$: 0:" >> train.txt
ls train/1 | sed "s:^:1/:" | sed "s:$: 1:" >> train.txt
ls train/2 | sed "s:^:2/:" | sed "s:$: 2:" >> train.txt
ls train/3 | sed "s:^:3/:" | sed "s:$: 3:" >> train.txt
ls train/4 | sed "s:^:4/:" | sed "s:$: 4:" >> train.txt
ls train/5 | sed "s:^:5/:" | sed "s:$: 5:" >> train.txt
ls train/6 | sed "s:^:6/:" | sed "s:$: 6:" >> train.txt

3)准备val.txt,标明验证图片路径及其对应分类
同理,在data目录下将指令修改为如下,可以使val目录下的7类训练集图片数据生成train.txt文件
ls val/0 | sed "s:^:0/:" | sed "s:$: 0:" >> val.txt
ls val/1 | sed "s:^:1/:" | sed "s:$: 1:" >> val.txt
ls val/2 | sed "s:^:2/:" | sed "s:$: 2:" >> val.txt
ls val/3 | sed "s:^:3/:" | sed "s:$: 3:" >> val.txt
ls val/4 | sed "s:^:4/:" | sed "s:$: 4:" >> val.txt
ls val/5 | sed "s:^:5/:" | sed "s:$: 5:" >> val.txt
ls val/6 | sed "s:^:6/:" | sed "s:$: 6:" >> val.txt
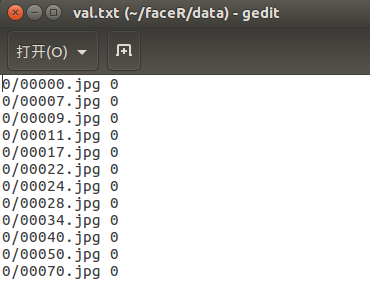
得到的val.txt文件(仅部分):
4)查看已准备的文件

3.生成lmdb文件
lmdb是caffe使用的一种输入数据格式,在训练前,我们必须把图片转换成caffe支持的格式才能进行训练,caffe中提供了create_imagenet.sh脚本,可以使图片转换为lmdb格式。
首先在faceR目录下创建一个文件夹,命名为lmbd。
将caffe/examples/Imagenet目录下的create_iamgenet.sh脚本拷贝到项目文件夹faceR的目录下,并修改其中的部分内容:

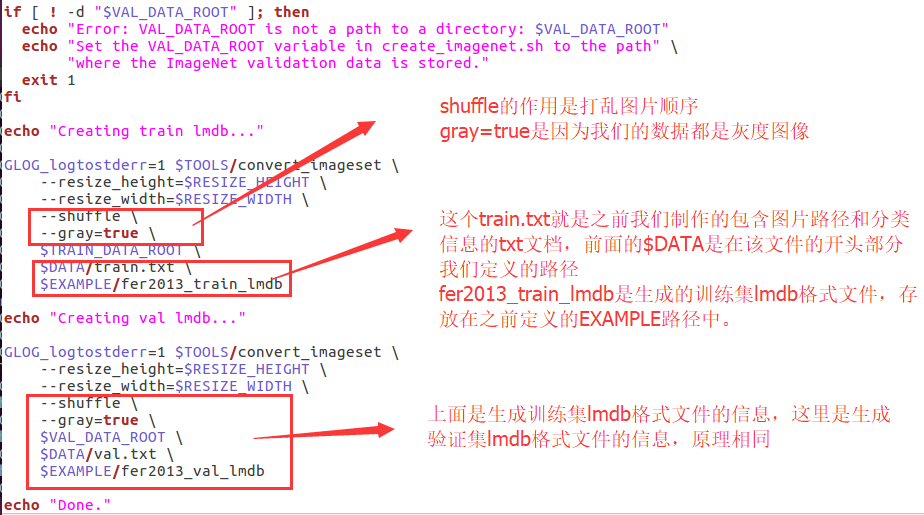
执行create_iamgenet.sh脚本:
查看生成的lmdb格式文件:

完成!!!

4.生成均值(mean_file)文件
可以用下面指令生成均值文件:
查看均值文件:


完成!!!
至此,数据集的处理工作已全部完成,下一篇文章将会介绍如何搭建用于表情识别的卷积神经网络模型。