《基于caffe的表情识别》系列文章索引:http://blog.csdn.net/pangyunsheng/article/details/79434263
一、注册申请Intel AI DevCloud
1.打开AI DevCloud申请的网址,请求访问:https://software.intel.com/zh-cn/ai-academy/tools/devcloud
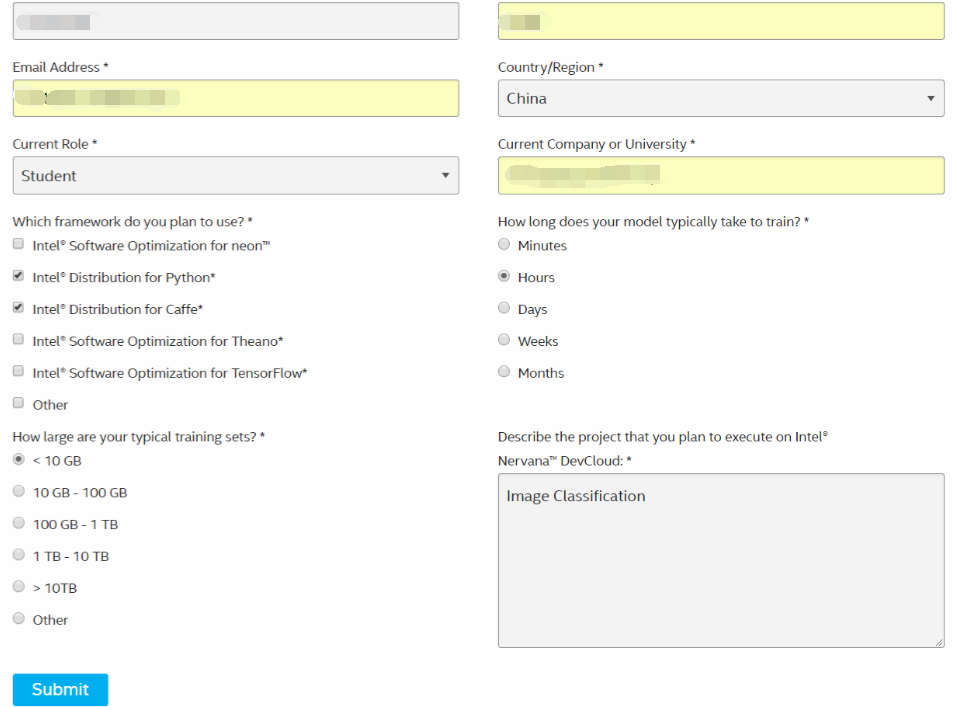
2.填写注册信息:
3.Submit提交,提交后会出现下面的界面:
4.说明已经申请成功了,大概等2个工作日左右,会收到一封邮件,邮件长这样:
第一个红框内的链接是使用教程,教你怎么连接到devcloud,要仔细阅读下。
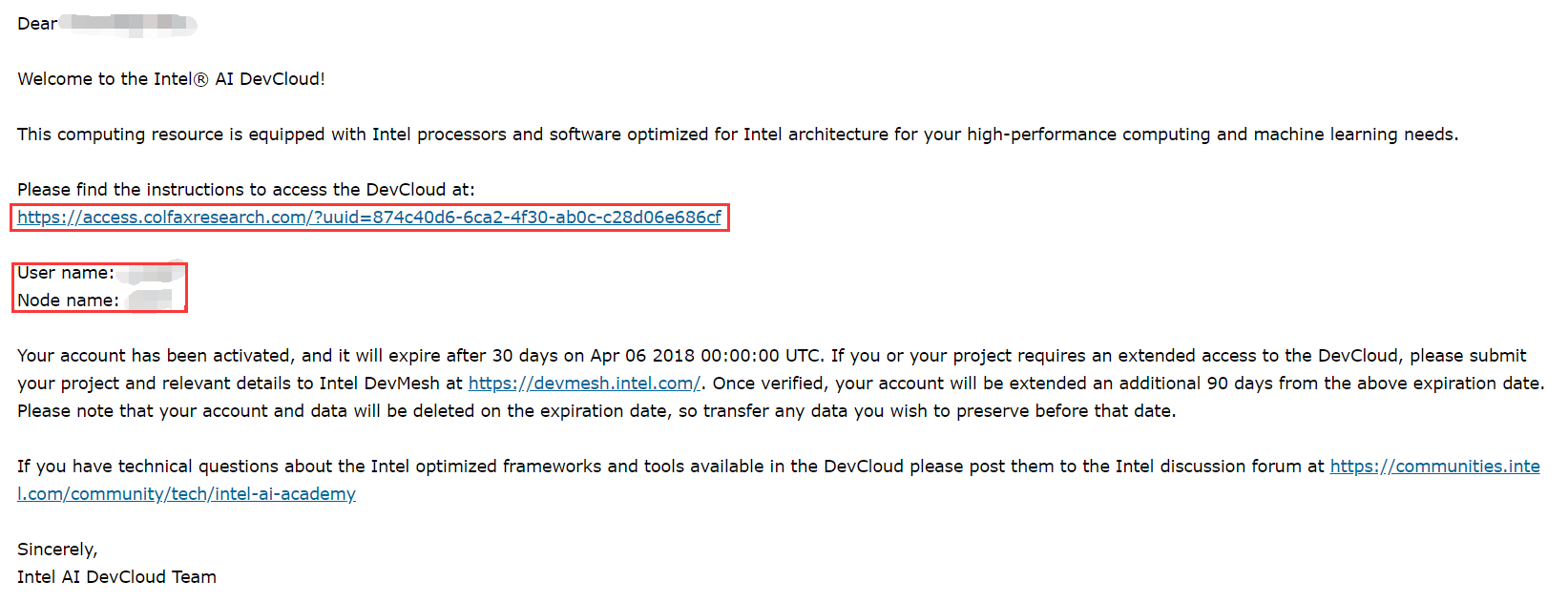
第二个红框内是你的user name和node name,这个要记下来。
二、从本地linux连接到DevCloud
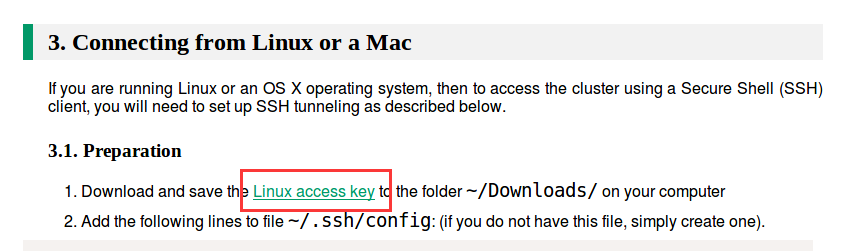
1.下载Linux access key
打开刚刚那封邮件中的链接(我用红框标注的),点击connect:
2.打开命令行,配置config文件。先输入下面指令:
cd .ssh
ls
vim config将你邮件中的下面这段内容(红框内的)拷贝到config文件中:
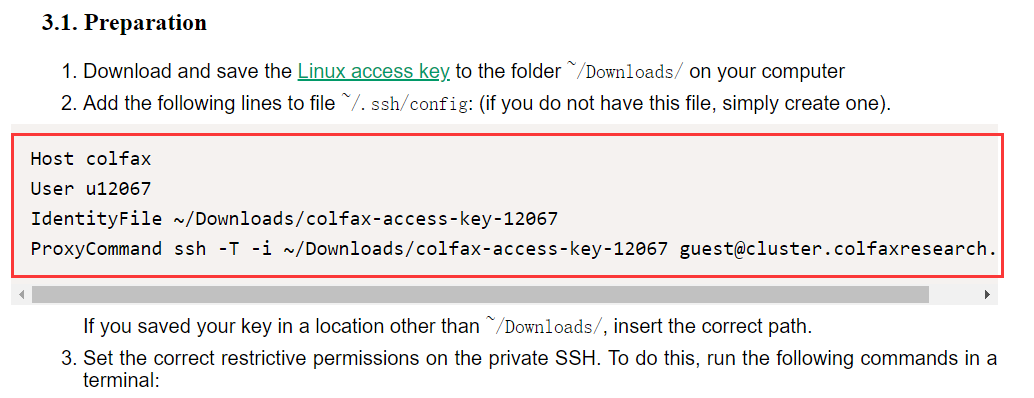
!!注:不要照着我的抄上去,因为每个人的用户信息不同,下载的密钥也不同,根据你邮箱中的内容直接拷贝过去就行了。还是建议大家阅读一下这个教程,写的很详细,我这里也仅仅是将其翻译一遍。

3.修改系统文件
在命令行中输入下图中的指令,还是同上,以邮箱的内容为准,不要拷贝我的:


4.登陆DevCloud
在命令行中输入下面指令(该指令就是登陆到DevCloud的指令,以后登陆都用这个指令):
ssh colfax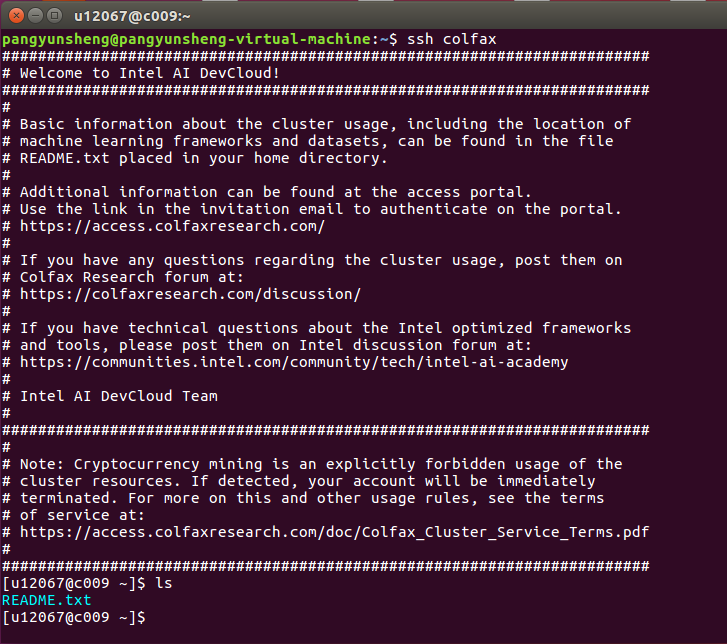
说明我们已经成功登陆到了DevCloud!!
三、上传文件,提交任务,开始训练
现在我们已经登陆到了DevCloud,在这里我们可以简单地看做我们登陆到了另一台linux主机,然而这台主机的计算能力要远远大于我们的笔记本电脑。现在虽然登陆到了这台主机,但是主机内是空的,没有任何文件,我们需要把我们本地已经创建好的,需要训练用的文件上传到DevCloud。
1.准备训练所需文件
在这里,我们需要准备5个用于训练所必须的文件,分别是训练集和验证集的lmdb文件和均值文件,我把它们放在了lmdb目录下:
还有网络结构文件和训练参数配置文件,我把它放在了model目录下:
上面的这些文件都是我们之前的文章中介绍过的,怎么生成都讲的很详细,如果还有不清楚的,可以到本篇文章开头的系列文章索引链接处查看以前的文章。
2.将文件上传到DevCloud
首先我在DevCloud下创建了一个文件夹,名为faceR:

接着再打开一个命令行,在本地linux下输入下面的文件传输指令:

其中,faceR/model是我的model目录在本地的路径,读者需要更换成自己的model路径,其次后面的u12067是我的用户ID,读者也需要更换自己的用户ID。
指令输入完后等一会儿可以看到:
说明文件上传成功,这时候可以在DevCloud下查看是否已经有了这个文件夹:

把lmdb目录按照上面同样的方法上传过去,这里就不再演示了。
3.创建脚本文件
在DevCloud的faceR目录下创建一个脚本文件:
vim lanuch_training
注意读者需要根据自己的路径做适当修改。
4.修改网络结构和参数配置文件的部分路径。
在train_val.prototxt文件中,需要修改下图中红框内的文件路径:
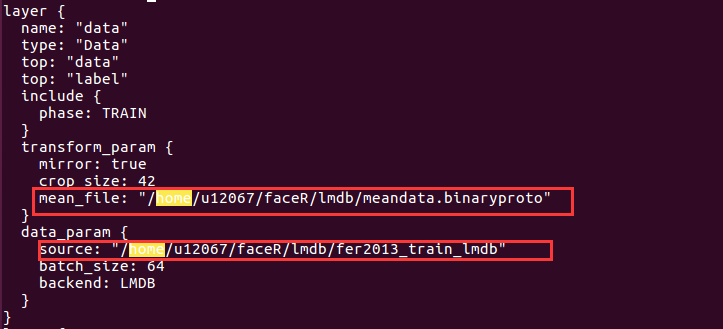
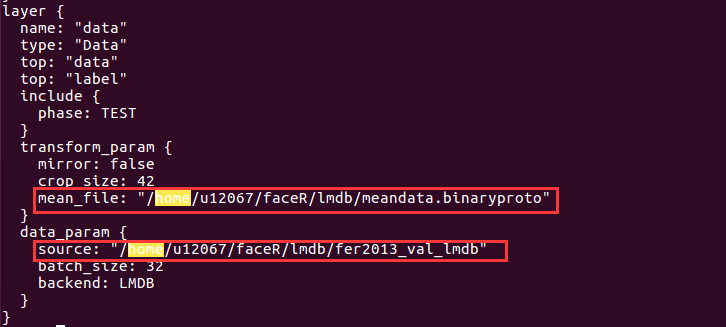
在facialnet_solver.prototxt文件中需要修改:
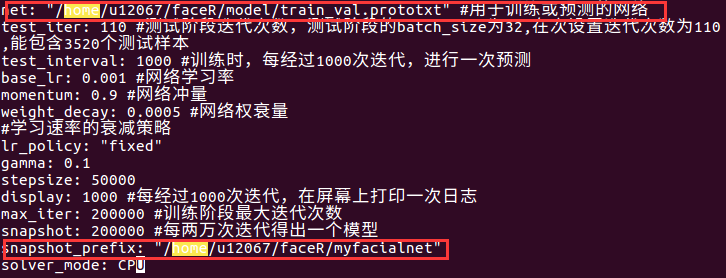
把上图红色框出的路径都修改成自己的路径,需要注意的是最后一个路径中的myfacialnet不是目录,而是生成的快照名字,可以取任意名字。
5.提交任务,开始训练
输入下面指令,提交任务:
qsub lanuch_training
到这里我们的任务就已经提交成功了,DevCloud现在就在帮我们训练,本项目需要训练20多分钟,如果在笔记本上用CPU训练,要一周多。
四、查看任务
1.查看任务
在训练过程中,可以使用qstat指令查看任务:
说明训练还没有完成。
如果输入qstat指令后,如下图这样:


说明训练已经完成,我们可以查看训练日志以及训练出的模型。
2.查看日志和模型
训练完成后,在faceR目录下,发现多了4个文件:

其中lanuch_training.e47394为训练日志,myfacialnet_iter_200000.caffemodel为最终的模型。
查看日志后发现本次实验的准确率在61%-62%之间,说明发生了过拟合,正常情况下该数据集下的准确率可以达到65%-70%之间,说明我们的网络模型还不够好,需要调参或是扩大数据集,这是更深一步的工作,在这里我不介绍如何调参等,因为本篇的目的是让大家了解caffe开发深度学习模型的大概流程。
到这里,我们本次实验的重头戏就已经结束了,训练出了模型就可以进行下一步测试了,下一篇将会介绍。