更新(2019-4-12)
上传了模型权重和模型结构,因GItHub不支持25MB以上的文件,因此上传在此处,如果急用可以在此下载,也是作为对我工作的一些支持
地址:https://download.csdn.net/download/shillyshally/11110754
如果不急用可以在下方留下邮箱,我在看博客的时候会回复,但会有一段时间的延迟
更新(2019-1-1)
增加了resnet模型,可在cnn.py中切换
正好在学习tensorflow,使用tensorflow重构了一下之前自己做的那个表情识别系统,直接使用fer2013.csv转tfrecord训练,不需再逐张转为图片,训练更快,代码更精简,支持中断训练之后载入模型继续训练等等
已在github上开源
提供给需要这个表情识别系统的tensorflow版本的人
原Keras版本地址:https://blog.csdn.net/shillyshally/article/details/80912854
Keras版本Github地址:https://github.com/shillyshallysxy/emotion_classifier
提供给需要原Keras版本的人
使用TensorFlow搭建并训练了卷积神经网络模型,用于人脸表情识别,训练集和测试集均采用kaggle的fer2013数据集。
达到如下效果:




整个表情识别系统分为两个过程:卷积神经网络模型的训练 与 面部表情的识别。
1.卷积神经网络模型的训练
1.1获取数据集
使用公开的数据集一方面可以节约收集数据的时间,另一方面可以更公平地评价模型以及人脸表情分类器的性能,因此,使用了kaggle面部表情识别竞赛所使用的fer2013人脸表情数据库。图片统一以csv的格式存储。首先用python将csv文件转为单通道灰度图片并根据标签将其分类在不同的文件夹中。
fer2013数据集链接: https://pan.baidu.com/s/1M6XS8ovXbn8-UfQwcUnvVQ 密码: jueq
1.2预处理数据集
将数据集转化为tfrecord格式
图片直接全部载入内存,每次训练全部载入的过程缓慢,耗时长,而且必然会造成内存巨大的开销,16G的内存全部被占用之后还不够,因此考虑构建一个队列,每次从外部磁盘读取部分数据,shuffle打乱后存放到内存中的队列中,此时内存只需要维护队列大小的空间,并且一次只需要载入部分数据,载入速度快了数十倍,同时训练过程中从内存中读取数据,训练过程的速度未收到影响。
with open(csv_path, 'r') as f:
csvr = csv.reader(f)
header = next(csvr)
rows = [row for row in csvr]
trn = [row[:-1] for row in rows if row[-1] == 'Training']
val = [row[:-1] for row in rows if row[-1] == 'PublicTest']
tst = [row[:-1] for row in rows if row[-1] == 'PrivateTest']
def write_binary(record_name_, labels_images_, height_=default_height, width_=default_width):
writer_ = tf.python_io.TFRecordWriter(record_name_)
for label_image_ in tqdm(labels_images_):
label_ = int(label_image_[0])
image_ = np.asarray([int(p) for p in label_image_[-1].split()])
example = tf.train.Example(
features=tf.train.Features(
feature={
"image/label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label_])),
"image/height": tf.train.Feature(int64_list=tf.train.Int64List(value=[height_])),
"image/width": tf.train.Feature(int64_list=tf.train.Int64List(value=[width_])),
"image/raw": tf.train.Feature(int64_list=tf.train.Int64List(value=image_))
}
)
)
writer_.write(example.SerializeToString())
writer_.close()
write_binary(record_path_train, trn)
write_binary(record_path_test, tst)
write_binary(record_path_eval, val)1.3搭建卷积神经网络模型
接下来就是建立卷积神经网络模型
博主在google的论文Going deeper with convolutions中获得灵感,在输入层之后加入了1*1的卷积层使输入增加了非线性的表示、加深了网络、提升了模型的表达能力,同时基本不增加计算量。之后根据VGG网络的想法,尝试将5*5网络拆分为两层3*3但最后效果并不理想,在多次尝试了多种不同的模型并不断调整之后
最终网络模型结构如下:
| 种类 |
核 |
步长 |
填充 |
输出 |
丢弃 |
| 输入 |
48*48*1 |
||||
| 卷积层1 |
1*1 |
1 |
48*48*32 |
||
| 卷积层2 |
5*5 |
1 |
2 |
48*48*32 |
|
| 池化层1 |
3*3 |
2 |
23*23*32 |
||
| 卷积层3 |
3*3 |
1 |
1 |
23*23*32 |
|
| 池化层2 |
3*3 |
2 |
11*11*32 |
||
| 卷积层4 |
5*5 |
1 |
2 |
11*11*64 |
|
| 池化层3 |
3*3 |
2 |
5*5*64 |
||
| 全连接层1 |
1*1*2048 |
50% |
|||
| 全连接层2 |
1*1*1024 |
50% |
|||
| 输出 |
1*1*7 |
模型的代码:
结构清晰,就不多解释了
import tensorflow as tf
from tensorflow.contrib.layers.python.layers import initializers
class CNN_Model():
def __init__(self, num_tags_=7, lr_=0.001, channel_=1, hidden_dim_=1024, full_shape_=2304, optimizer_='Adam'):
self.num_tags = num_tags_
self.lr = lr_
self.full_shape = full_shape_
self.channel = channel_
self.hidden_dim = hidden_dim_
self.conv_feature = [32, 32, 32, 64]
self.conv_size = [1, 5, 3, 5]
self.maxpool_size = [0, 3, 3, 3]
self.maxpool_stride = [0, 2, 2, 2]
# self.initializer = tf.truncated_normal_initializer(stddev=0.05)
self.initializer = initializers.xavier_initializer()
self.dropout = tf.placeholder(dtype=tf.float32, name='dropout')
self.x_input = tf.placeholder(dtype=tf.float32, shape=[None, None, None, self.channel], name='x_input')
self.y_target = tf.placeholder(dtype=tf.int32, shape=[None], name='y_target')
self.batch_size = tf.shape(self.x_input)[0]
self.logits = self.project_layer(self.cnn_layer())
with tf.variable_scope("loss"):
self.loss = self.loss_layer(self.logits)
self.train_step = self.optimizer(self.loss, optimizer_)
def cnn_layer(self):
with tf.variable_scope("conv1"):
conv1_weight = tf.get_variable('conv1_weight', [self.conv_size[0], self.conv_size[0],
self.channel, self.conv_feature[0]],
dtype=tf.float32, initializer=self.initializer)
conv1_bias = tf.get_variable('conv1_bias', [self.conv_feature[0]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(self.x_input, conv1_weight, [1, 1, 1, 1], padding='SAME')
conv1_add_bias = tf.nn.bias_add(conv1, conv1_bias)
conv1_relu = tf.nn.relu(conv1_add_bias)
norm1 = tf.nn.lrn(conv1_relu, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm1')
with tf.variable_scope("conv2"):
conv2_weight = tf.get_variable('conv2_weight', [self.conv_size[1], self.conv_size[1],
self.conv_feature[0], self.conv_feature[1]],
dtype=tf.float32, initializer=self.initializer)
conv2_bias = tf.get_variable('conv2_bias', [self.conv_feature[1]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(norm1, conv2_weight, [1, 1, 1, 1], padding='SAME')
conv2_add_bias = tf.nn.bias_add(conv2, conv2_bias)
conv2_relu = tf.nn.relu(conv2_add_bias)
pool2 = tf.nn.max_pool(conv2_relu, ksize=[1, self.maxpool_size[1], self.maxpool_size[1], 1],
strides=[1, self.maxpool_stride[1], self.maxpool_stride[1], 1],
padding='SAME', name='pool_layer2')
norm2 = tf.nn.lrn(pool2, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm2')
with tf.variable_scope("conv3"):
conv3_weight = tf.get_variable('conv3_weight', [self.conv_size[2], self.conv_size[2],
self.conv_feature[1], self.conv_feature[2]],
dtype=tf.float32, initializer=self.initializer)
conv3_bias = tf.get_variable('conv3_bias', [self.conv_feature[2]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(norm2, conv3_weight, [1, 1, 1, 1], padding='SAME')
conv3_add_bias = tf.nn.bias_add(conv3, conv3_bias)
conv3_relu = tf.nn.relu(conv3_add_bias)
pool3 = tf.nn.max_pool(conv3_relu, ksize=[1, self.maxpool_size[2], self.maxpool_size[2], 1],
strides=[1, self.maxpool_stride[2], self.maxpool_stride[2], 1],
padding='SAME', name='pool_layer3')
norm3 = tf.nn.lrn(pool3, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm3')
with tf.variable_scope("conv4"):
conv4_weight = tf.get_variable('conv4_weight', [self.conv_size[3], self.conv_size[3],
self.conv_feature[2], self.conv_feature[3]],
dtype=tf.float32, initializer=self.initializer)
conv4_bias = tf.get_variable('conv4_bias', [self.conv_feature[3]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(norm3, conv4_weight, [1, 1, 1, 1], padding='SAME')
conv4_add_bias = tf.nn.bias_add(conv4, conv4_bias)
conv4_relu = tf.nn.relu(conv4_add_bias)
pool4 = tf.nn.max_pool(conv4_relu, ksize=[1, self.maxpool_size[3], self.maxpool_size[3], 1],
strides=[1, self.maxpool_stride[3], self.maxpool_stride[3], 1],
padding='SAME', name='pool_layer4')
norm4 = tf.nn.lrn(pool4, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm4')
return norm4
def cnn_layer_single(self):
with tf.variable_scope("conv1"):
conv1_weight = tf.get_variable('conv1_weight', [self.conv_size[0], self.conv_size[0],
self.channel, self.conv_feature[0]],
dtype=tf.float32, initializer=self.initializer)
conv1_bias = tf.get_variable('conv1_bias', [self.conv_feature[0]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(self.x_input, conv1_weight, [1, 1, 1, 1], padding='SAME')
conv1_add_bias = tf.nn.bias_add(conv1, conv1_bias)
conv1_relu = tf.nn.relu(conv1_add_bias)
with tf.variable_scope("conv2"):
conv2_weight = tf.get_variable('conv2_weight', [self.conv_size[1], self.conv_size[1],
self.conv_feature[0], self.conv_feature[1]],
dtype=tf.float32, initializer=self.initializer)
conv2_bias = tf.get_variable('conv2_bias', [self.conv_feature[1]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(conv1_relu, conv2_weight, [1, 1, 1, 1], padding='SAME')
conv2_add_bias = tf.nn.bias_add(conv2, conv2_bias)
conv2_relu = tf.nn.relu(conv2_add_bias)
pool2 = tf.nn.max_pool(conv2_relu, ksize=[1, self.maxpool_size[1], self.maxpool_size[1], 1],
strides=[1, self.maxpool_stride[1], self.maxpool_stride[1], 1],
padding='SAME', name='pool_layer2')
with tf.variable_scope("conv3"):
conv3_weight = tf.get_variable('conv3_weight', [self.conv_size[2], self.conv_size[2],
self.conv_feature[1], self.conv_feature[2]],
dtype=tf.float32, initializer=self.initializer)
conv3_bias = tf.get_variable('conv3_bias', [self.conv_feature[2]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(pool2, conv3_weight, [1, 1, 1, 1], padding='SAME')
conv3_add_bias = tf.nn.bias_add(conv3, conv3_bias)
conv3_relu = tf.nn.relu(conv3_add_bias)
pool3 = tf.nn.max_pool(conv3_relu, ksize=[1, self.maxpool_size[2], self.maxpool_size[2], 1],
strides=[1, self.maxpool_stride[2], self.maxpool_stride[2], 1],
padding='SAME', name='pool_layer3')
with tf.variable_scope("conv4"):
conv4_weight = tf.get_variable('conv4_weight', [self.conv_size[3], self.conv_size[3],
self.conv_feature[2], self.conv_feature[3]],
dtype=tf.float32, initializer=self.initializer)
conv4_bias = tf.get_variable('conv4_bias', [self.conv_feature[3]], dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(pool3, conv4_weight, [1, 1, 1, 1], padding='SAME')
conv4_add_bias = tf.nn.bias_add(conv4, conv4_bias)
conv4_relu = tf.nn.relu(conv4_add_bias)
pool4 = tf.nn.max_pool(conv4_relu, ksize=[1, self.maxpool_size[3], self.maxpool_size[3], 1],
strides=[1, self.maxpool_stride[3], self.maxpool_stride[3], 1],
padding='SAME', name='pool_layer4')
return pool4
def project_layer(self, x_in_):
with tf.variable_scope("project"):
with tf.variable_scope("hidden"):
x_in_ = tf.reshape(x_in_, [self.batch_size, -1])
w_tanh1 = tf.get_variable("w_tanh1", [self.full_shape, self.hidden_dim*2], initializer=self.initializer,
regularizer=tf.contrib.layers.l2_regularizer(0.001))
b_tanh1 = tf.get_variable("b_tanh1", [self.hidden_dim*2], initializer=tf.zeros_initializer())
w_tanh2 = tf.get_variable("w_tanh2", [self.hidden_dim*2, self.hidden_dim], initializer=self.initializer,
regularizer=tf.contrib.layers.l2_regularizer(0.001))
b_tanh2 = tf.get_variable("b_tanh2", [self.hidden_dim], initializer=tf.zeros_initializer())
output1 = tf.nn.dropout(tf.nn.relu(tf.add(tf.matmul(x_in_, w_tanh1),
b_tanh1)), keep_prob=self.dropout)
output2 = tf.nn.dropout(tf.nn.relu(tf.add(tf.matmul(output1, w_tanh2),
b_tanh2)), keep_prob=self.dropout)
with tf.variable_scope("output"):
w_out = tf.get_variable("w_out", [self.hidden_dim, self.num_tags], initializer=self.initializer,
regularizer=tf.contrib.layers.l2_regularizer(0.001))
b_out = tf.get_variable("b_out", [self.num_tags], initializer=tf.zeros_initializer())
pred_ = tf.add(tf.matmul(output2, w_out), b_out, name='logits')
return pred_
def loss_layer(self, project_logits):
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=project_logits, labels=self.y_target), name='softmax_loss')
return loss
def optimizer(self, loss_, method=''):
if method == 'Momentum':
step = tf.Variable(0, trainable=False)
model_learning_rate = tf.train.exponential_decay(0.01, step,
100, 0.99, staircase=True)
my_optimizer = tf.train.MomentumOptimizer(model_learning_rate, momentum=0.9)
train_step_ = my_optimizer.minimize(loss_, global_step=step, name='train_step')
print('Using ', method)
elif method == 'SGD':
step = tf.Variable(0, trainable=False)
model_learning_rate = tf.train.exponential_decay(0.1, step,
200., 0.96, staircase=True)
my_optimizer = tf.train.GradientDescentOptimizer(model_learning_rate)
train_step_ = my_optimizer.minimize(loss_, name='train_step')
print('Using ', method)
elif method == 'Adam':
train_step_ = tf.train.AdamOptimizer(self.lr).minimize(loss_, name='train_step')
print('Using ', method)
else:
train_step_ = tf.train.MomentumOptimizer(0.005, momentum=0.9).minimize(loss_, name='train_step')
print('Using Default')
return train_step_
1.4训练模型
通过水平翻转,调节亮度饱和度,随机裁切来进行数据增强,结构清晰代码简单,就不多解释了
# 数据增强
def pre_process_img(image):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_brightness(image, max_delta=32./255)
image = tf.image.random_contrast(image, lower=0.8, upper=1.2)
image = tf.random_crop(image, [default_height-np.random.randint(0, 4), default_width-np.random.randint(0, 4), 1])
image = tf.image.resize_images(image, [default_height, default_width])
return image
def __parse_function_image(serial_exmp_):
features_ = tf.parse_single_example(serial_exmp_, features={"image/label": tf.FixedLenFeature([], tf.int64),
"image/height": tf.FixedLenFeature([], tf.int64),
"image/width": tf.FixedLenFeature([], tf.int64),
"image/raw": tf.FixedLenFeature([], tf.string)})
label_ = tf.cast(features_["image/label"], tf.int32)
height_ = tf.cast(features_["image/height"], tf.int32)
width_ = tf.cast(features_["image/width"], tf.int32)
image_ = tf.image.decode_jpeg(features_["image/raw"])
image_ = tf.reshape(image_, [height_, width_, channel])
image_ = tf.image.convert_image_dtype(image_, dtype=tf.float32)
image_ = tf.image.resize_images(image_, [default_height, default_width])
# image_ = pre_process_img(image_)
return image_, label_
def __parse_function_csv(serial_exmp_):
features_ = tf.parse_single_example(serial_exmp_,
features={"image/label": tf.FixedLenFeature([], tf.int64),
"image/height": tf.FixedLenFeature([], tf.int64),
"image/width": tf.FixedLenFeature([], tf.int64),
"image/raw": tf.FixedLenFeature([default_width*default_height*channel]
, tf.int64)})
label_ = tf.cast(features_["image/label"], tf.int32)
height_ = tf.cast(features_["image/height"], tf.int32)
width_ = tf.cast(features_["image/width"], tf.int32)
image_ = tf.cast(features_["image/raw"], tf.int32)
image_ = tf.reshape(image_, [height_, width_, channel])
image_ = tf.multiply(tf.cast(image_, tf.float32), 1. / 255)
image_ = pre_process_img(image_)
return image_, label_
def get_dataset(record_name_):
record_path_ = os.path.join(data_folder_name, data_path_name, record_name_)
data_set_ = tf.data.TFRecordDataset(record_path_)
return data_set_.map(__parse_function_csv)
def evaluate(logits_, y_):
return np.mean(np.equal(np.argmax(logits_, axis=1), y_))
def main(argv):
with tf.Session() as sess:
summary_writer = tf.summary.FileWriter(tensorboard_path, sess.graph)
data_set_train = get_dataset(record_name_train)
data_set_train = data_set_train.shuffle(shuffle_pool_size).batch(batch_size).repeat()
data_set_train_iter = data_set_train.make_one_shot_iterator()
train_handle = sess.run(data_set_train_iter.string_handle())
data_set_test = get_dataset(record_name_test)
data_set_test = data_set_test.shuffle(shuffle_pool_size).batch(test_batch_size).repeat()
data_set_test_iter = data_set_test.make_one_shot_iterator()
test_handle = sess.run(data_set_test_iter.string_handle())
handle = tf.placeholder(tf.string, shape=[], name='handle')
iterator = tf.data.Iterator.from_string_handle(handle, data_set_train.output_types, data_set_train.output_shapes)
x_input_bacth, y_target_batch = iterator.get_next()
cnn_model = cnn.CNN_Model()
x_input = cnn_model.x_input
y_target = cnn_model.y_target
logits = tf.nn.softmax(cnn_model.logits)
loss = cnn_model.loss
train_step = cnn_model.train_step
dropout = cnn_model.dropout
sess.run(tf.global_variables_initializer())
if retrain:
print('retraining')
ckpt_name = 'cnn_emotion_classifier.ckpt'
ckpt_path = os.path.join(data_folder_name, data_path_name, ckpt_name)
saver = tf.train.Saver()
saver.restore(sess, ckpt_path)
with tf.name_scope('Loss_and_Accuracy'):
tf.summary.scalar('Loss', loss)
summary_op = tf.summary.merge_all()
print('start training')
saver = tf.train.Saver(max_to_keep=1)
max_accuracy = 0
temp_train_loss = []
temp_test_loss = []
temp_train_acc = []
temp_test_acc = []
for i in range(generations):
x_batch, y_batch = sess.run([x_input_bacth, y_target_batch], feed_dict={handle: train_handle})
train_feed_dict = {x_input: x_batch, y_target: y_batch,
dropout: 0.5}
sess.run(train_step, train_feed_dict)
if (i + 1) % 100 == 0:
train_loss, train_logits = sess.run([loss, logits], train_feed_dict)
train_accuracy = evaluate(train_logits, y_batch)
print('Generation # {}. Train Loss : {:.3f} . '
'Train Acc : {:.3f}'.format(i, train_loss, train_accuracy))
temp_train_loss.append(train_loss)
temp_train_acc.append(train_accuracy)
summary_writer.add_summary(sess.run(summary_op, train_feed_dict), i)
if (i + 1) % 400 == 0:
test_x_batch, test_y_batch = sess.run([x_input_bacth, y_target_batch], feed_dict={handle: test_handle})
test_feed_dict = {x_input: test_x_batch, y_target: test_y_batch,
dropout: 1.0}
test_loss, test_logits = sess.run([loss, logits], test_feed_dict)
test_accuracy = evaluate(test_logits, test_y_batch)
print('Generation # {}. Test Loss : {:.3f} . '
'Test Acc : {:.3f}'.format(i, test_loss, test_accuracy))
temp_test_loss.append(test_loss)
temp_test_acc.append(test_accuracy)
if test_accuracy >= max_accuracy and save_flag and i > generations // 2:
max_accuracy = test_accuracy
saver.save(sess, os.path.join(data_folder_name, data_path_name, save_ckpt_name))
print('Generation # {}. --model saved--'.format(i))
print('Last accuracy : ', max_accuracy)
with open(model_log_path, 'w') as f:
f.write('train_loss: ' + str(temp_train_loss))
f.write('\n\ntest_loss: ' + str(temp_test_loss))
f.write('\n\ntrain_acc: ' + str(temp_train_acc))
f.write('\n\ntest_acc: ' + str(temp_test_acc))
print(' --log saved--')
if __name__ == '__main__':
tf.app.run()
2.人脸表情识别模块
2.1加载模型
# config=tf.ConfigProto(log_device_placement=True)
sess = tf.Session()
saver = tf.train.import_meta_graph(ckpt_path+'.meta')
saver.restore(sess, ckpt_path)
graph = tf.get_default_graph()
name = [n.name for n in graph.as_graph_def().node]
print(name)
x_input = graph.get_tensor_by_name('x_input:0')
dropout = graph.get_tensor_by_name('dropout:0')
logits = graph.get_tensor_by_name('project/output/logits:0')2.2表情识别
兼带生成测试集以及验证集混淆矩阵的代码,将confusion_matrix值设置为True即生成混淆矩阵False为识别文件夹中的所有图片
img_size = 48
confusion_matrix = False
emotion_labels = ['angry', 'disgust:', 'fear', 'happy', 'sad', 'surprise', 'neutral']
num_class = len(emotion_labels)
def prodece_confusion_matrix(images_, total_num_):
results = np.array([0]*num_class)
total = []
for imgs_ in images_:
for img_ in imgs_:
results[np.argmax(predict_emotion(img_))] += 1
print(results, np.around(results/len(imgs_), decimals=3))
total.append(results)
results = np.array([0]*num_class)
sum = 0
for i_ in range(num_class):
sum += total[i_][i_]
print('acc: {:.3f} %'.format(sum*100./total_num_))
print('Using ', ckpt_name)
def predict_emotion(face_img_, img_size_=48):
face_img_ = face_img_ * (1. / 255)
resized_img_ = cv2.resize(face_img_, (img_size_, img_size_)) # ,interpolation=cv2.INTER_LINEAR
rsz_img = []
rsz_img.append(resized_img_[:, :])
rsz_img.append(resized_img_[2:45, :])
rsz_img.append(cv2.flip(rsz_img[0], 1))
for i_, rsz_image in enumerate(rsz_img):
rsz_img[i_] = cv2.resize(rsz_image, (img_size_, img_size_)).reshape(img_size_, img_size_, 1)
rsz_img = np.array(rsz_img)
feed_dict_ = {x_input: rsz_img, dropout: 1.0}
pred_logits_ = sess.run([tf.reduce_sum(tf.nn.softmax(logits), axis=0)], feed_dict_)
return np.squeeze(pred_logits_)
def face_detect(image_path, casc_path_=casc_path):
if os.path.isfile(casc_path_):
face_casccade_ = cv2.CascadeClassifier(casc_path_)
img_ = cv2.imread(image_path)
img_gray_ = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY)
# face detection
faces = face_casccade_.detectMultiScale(
img_gray_,
scaleFactor=1.1,
minNeighbors=1,
minSize=(30, 30),
)
return faces, img_gray_, img_
else:
print("There is no {} in {}".format(casc_name, casc_path_))
if __name__ == '__main__':
if not confusion_matrix:
images_path = []
files = os.listdir(pic_path)
for file in files:
if file.lower().endswith('jpg') or file.endswith('png'):
images_path.append(os.path.join(pic_path, file))
for image in images_path:
faces, img_gray, img = face_detect(image)
spb = img.shape
sp = img_gray.shape
height = sp[0]
width = sp[1]
size = 600
emotion_pre_dict = {}
face_exists = 0
for (x, y, w, h) in faces:
face_exists = 1
face_img_gray = img_gray[y:y + h, x:x + w]
results_sum = predict_emotion(face_img_gray) # face_img_gray
for i, emotion_pre in enumerate(results_sum):
emotion_pre_dict[emotion_labels[i]] = emotion_pre
# 输出所有情绪的概率
print(emotion_pre_dict)
label = np.argmax(results_sum)
emo = emotion_labels[int(label)]
print('Emotion : ', emo)
# 输出最大概率的情绪
# 使框的大小适应各种像素的照片
t_size = 2
ww = int(spb[0] * t_size / 300)
www = int((w + 10) * t_size / 100)
www_s = int((w + 20) * t_size / 100) * 2 / 5
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), ww)
cv2.putText(img, emo, (x + 2, y + h - 2), cv2.FONT_HERSHEY_SIMPLEX,
www_s, (255, 0, 255), thickness=www, lineType=1)
# img_gray full face face_img_gray part of face
if face_exists:
cv2.namedWindow('Emotion_classifier', 0)
cent = int((height * 1.0 / width) * size)
cv2.resizeWindow('Emotion_classifier', size, cent)
cv2.imshow('Emotion_classifier', img)
k = cv2.waitKey(0)
cv2.destroyAllWindows()
# if k & 0xFF == ord('q'):
# break
if confusion_matrix:
with open(csv_path, 'r') as f:
csvr = csv.reader(f)
header = next(csvr)
rows = [row for row in csvr]
val = [row[:-1] for row in rows if row[-1] == 'PublicTest']
# tst = [row[:-1] for row in rows if row[-1] == 'PrivateTest']
confusion_images_total = []
confusion_images = {0: [], 1: [], 2: [], 3: [], 4: [], 5: [], 6: []}
test_set = val
total_num = len(test_set)
for label_image_ in test_set:
label_ = int(label_image_[0])
image_ = np.reshape(np.asarray([int(p) for p in label_image_[-1].split()]), [img_size, img_size, 1])
confusion_images[label_].append(image_)
prodece_confusion_matrix(confusion_images.values(), total_num)
3.效果展示
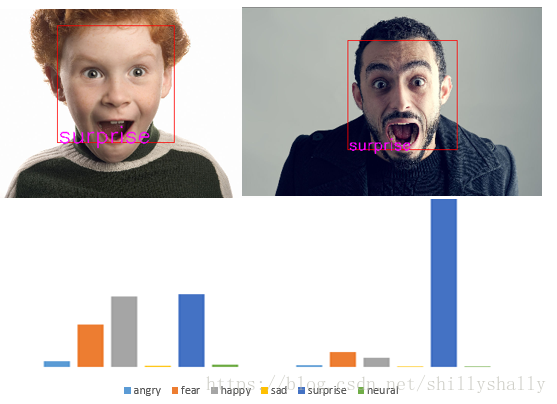
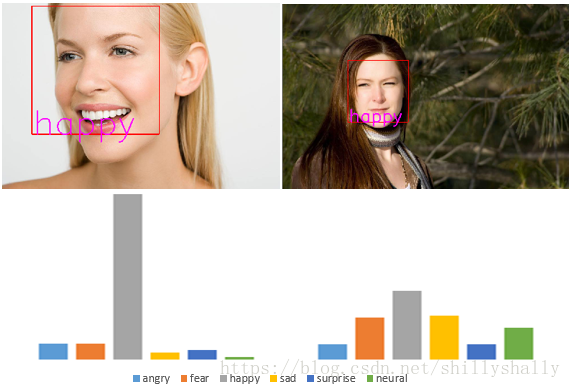

最后附上实验环境
系统:win10
语言:python3.6
显卡:GTX1080ti
参考文献
- Jeon J, Park J C, Jo Y J, et al. A Real-time Facial Expression Recognizer using Deep Neural Network[J].ACM 2016:1-4.
- He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:770-778.
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
- Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks[C]// European Conference on Computer Vision. Springer, Cham, 2014:818-833.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Going Deeper with Convolutions[C]. 2014
- Samaa M, Shohieb. SignsWorld Facial Expression Recognition System (FERS)[J]. Intelligent Automation & Soft Computing,2015
- Srivastava, Nitish. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15.1: 1929-1958.
- Jia, Yangqing, Shelhamer, et al. Caffe: Convolutional Architecture for Fast Feature Embedding[J]. 2014:675-678.