【深度学习入门】Paddle实现人脸检测和表情识别(基于YOLO和ResNet18)
博主主页:https://blog.csdn.net/weixin_44936889
未经博主允许,本文禁止转载!
一、先看效果:
本项目在 AI Studio 上进行,项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/443545
训练及测试结果:


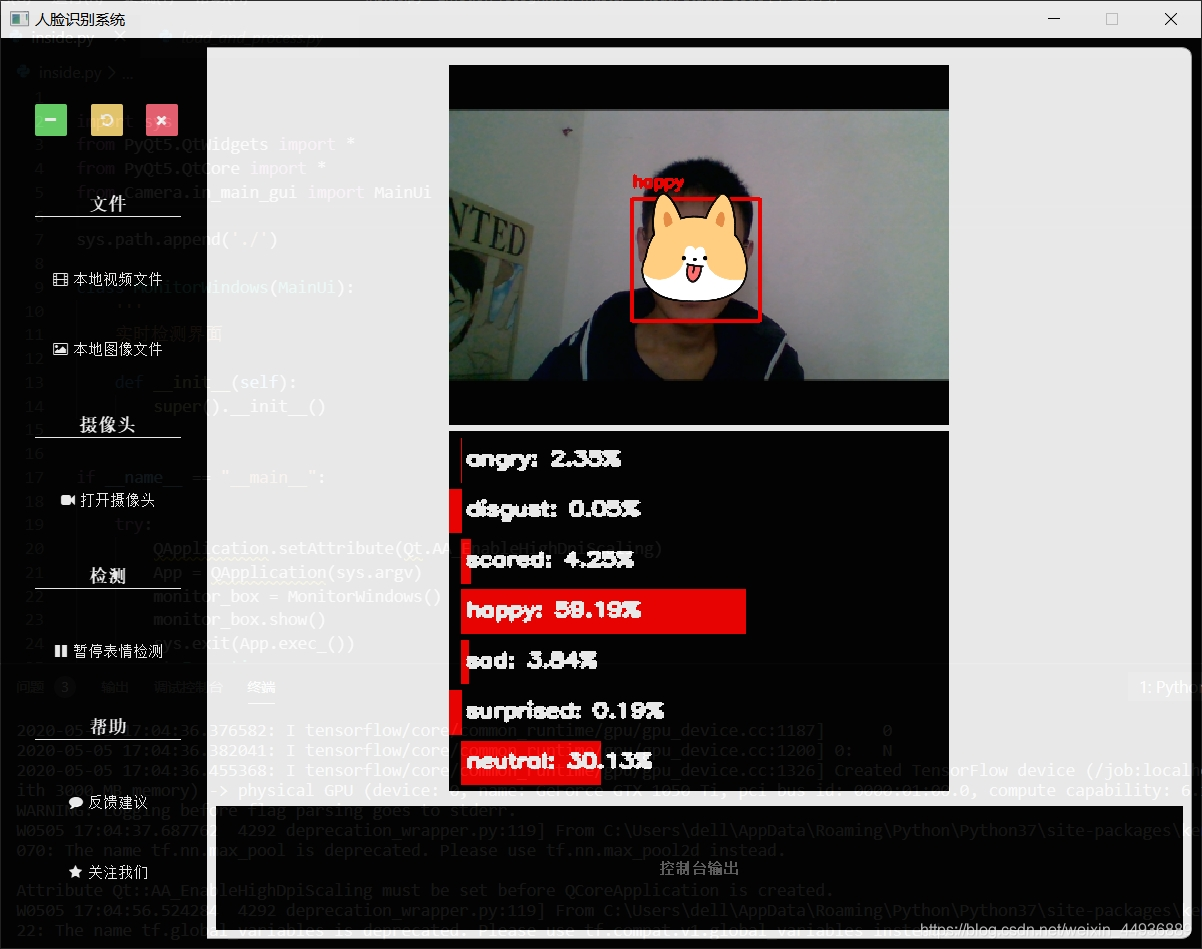
UI 界面及其可视化:
二、AI Studio 简介:
地址:https://aistudio.baidu.com/aistudio/index
平台简介:
为了给广大开发者提供更加完善自由的编程环境,帮助入门小白进行项目学习和体验,帮助开发者更快捷简便的完成深度学习项目,并持续提供更多的增值服务,百度设计研发了百度AI Studio一站式开发平台。此平台集合了AI教程、代码环境、算法算力和数据集,并为开发者提供了免费的在线云计算编程环境,并且无需再进行环境配置和依赖包等繁琐步骤,随时随地可以上线AI Studio开展深度学习项目。
创建项目:
开发者可以自由创建项目,并选择 AI Studio 平台提供的 GPU 和训练集:
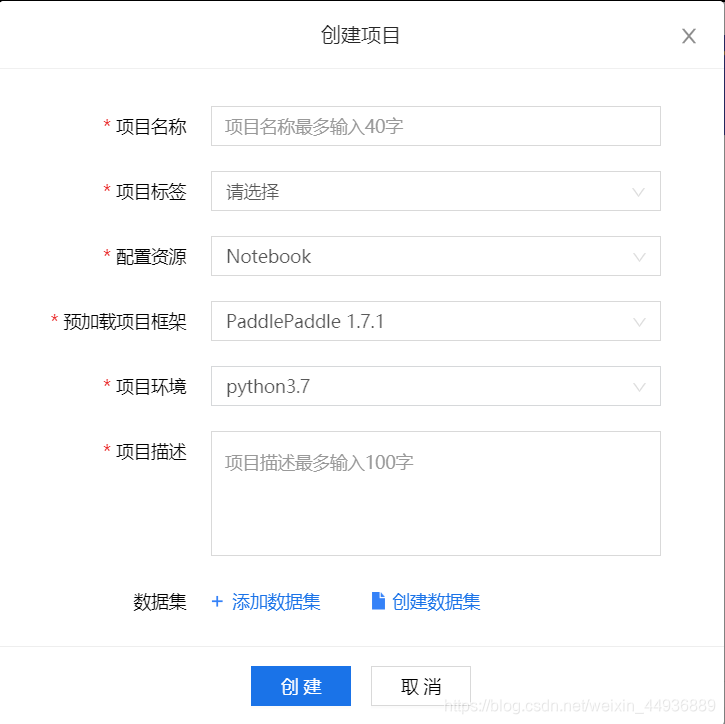
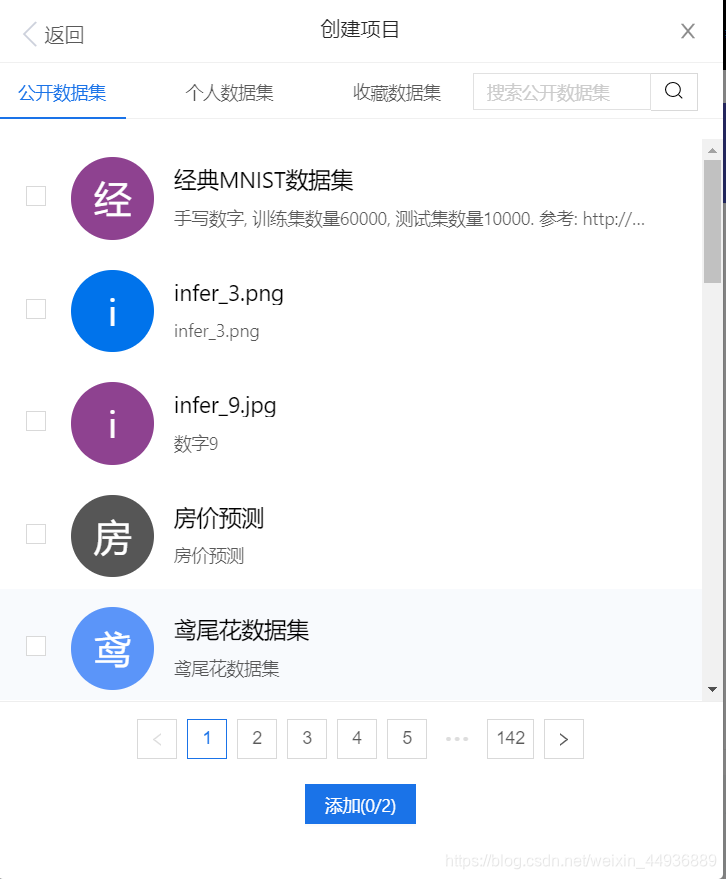
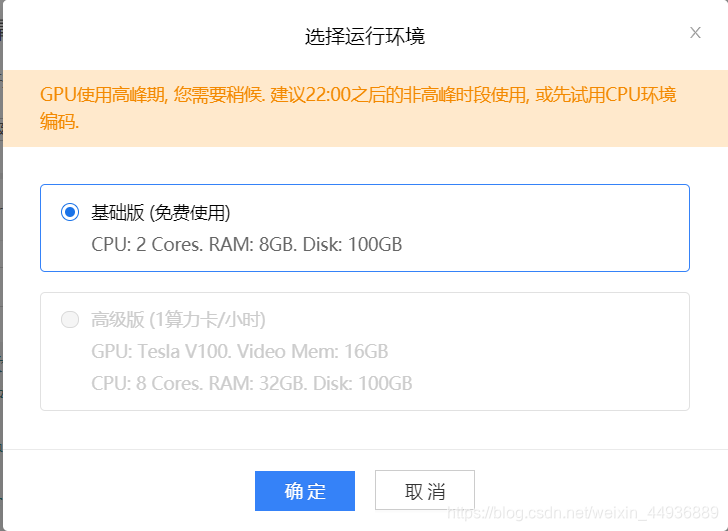
三、创建AI Studio项目:
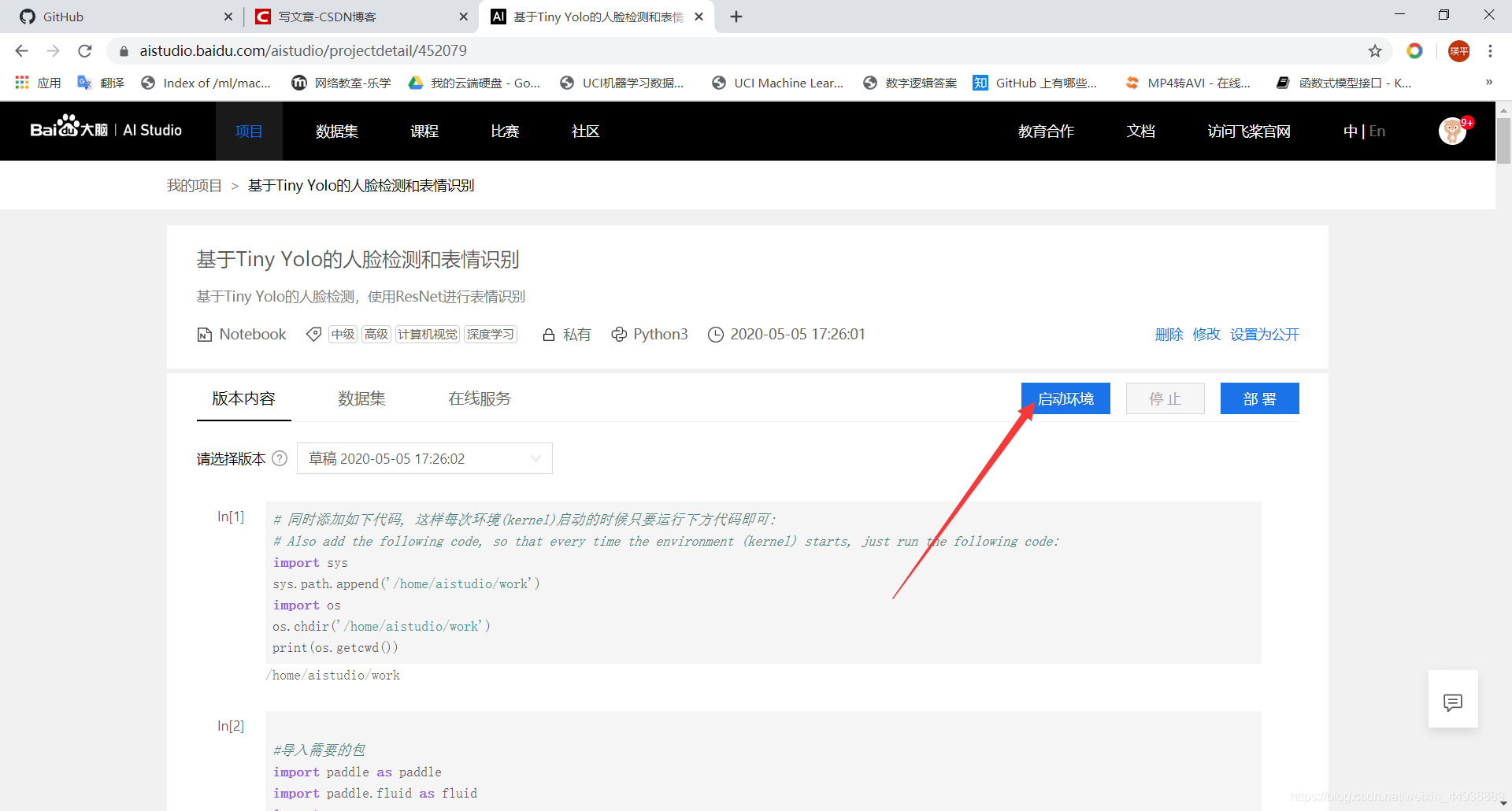
创建并启动环境:
进入项目地址并 Fork:
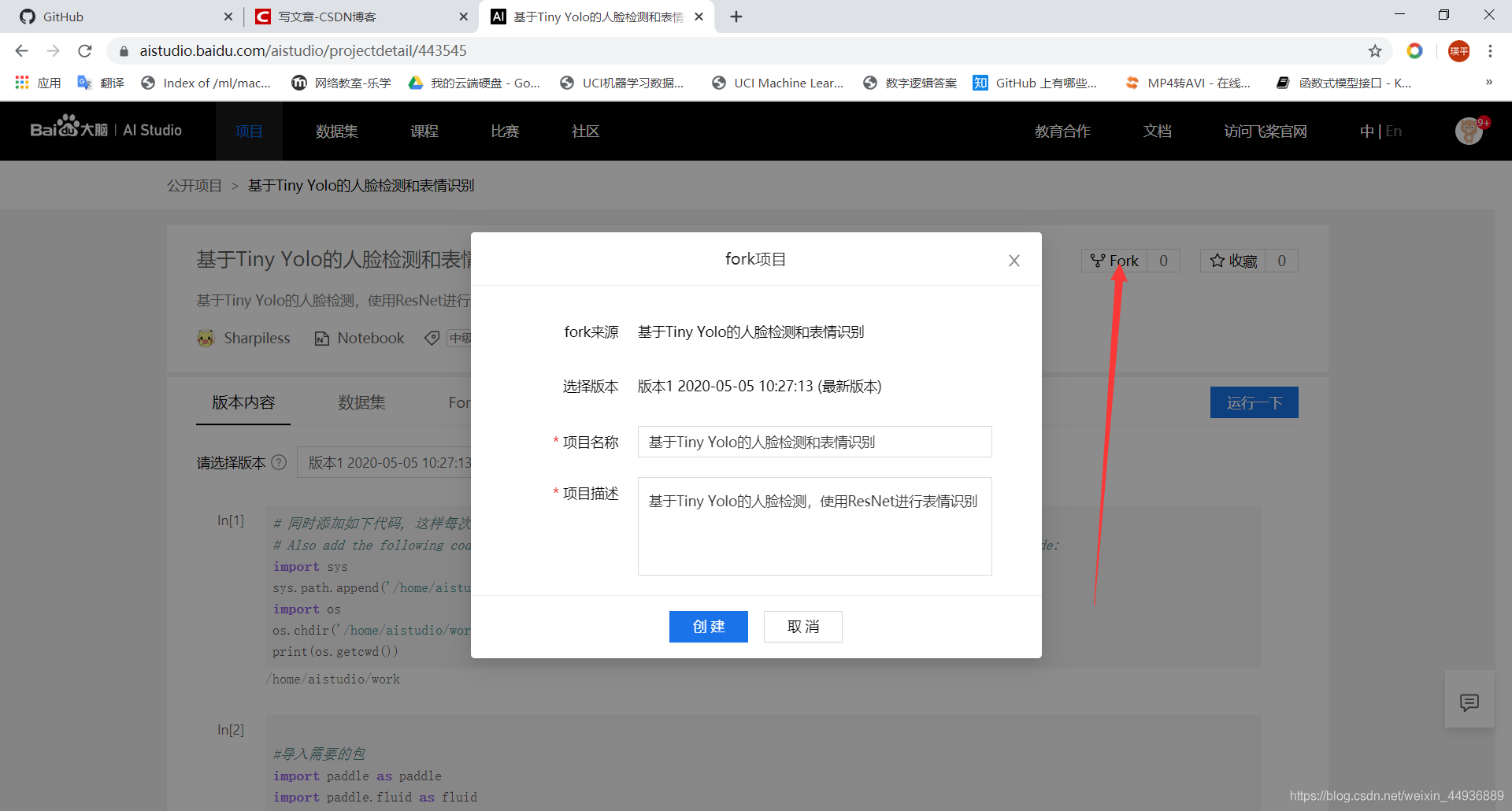
运行项目:
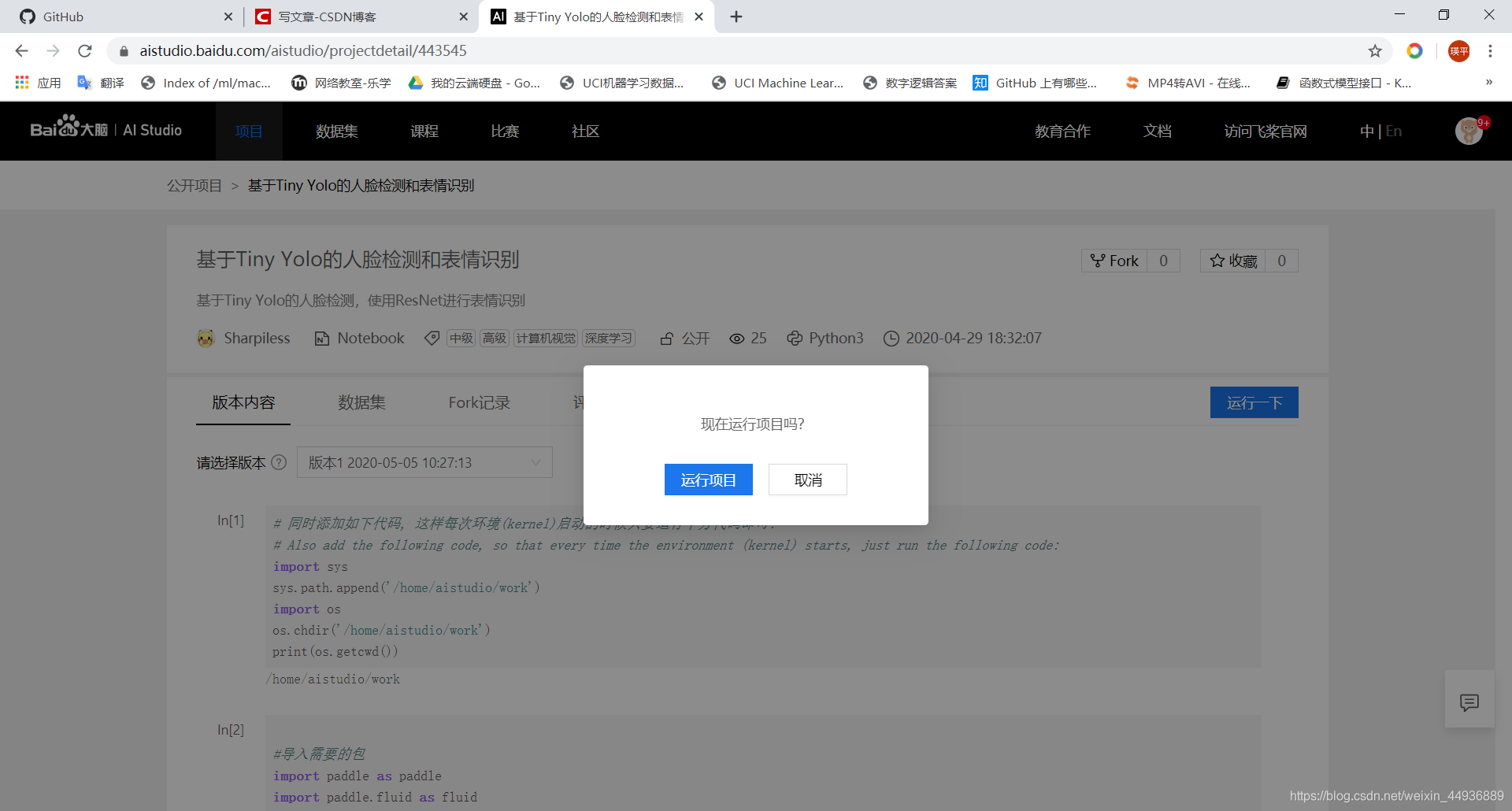
启动并进入环境:
下载数据:
数据集地址:
链接:https://pan.baidu.com/s/1H7x2HSL_WV6oB-16enffmw
提取码:cllz
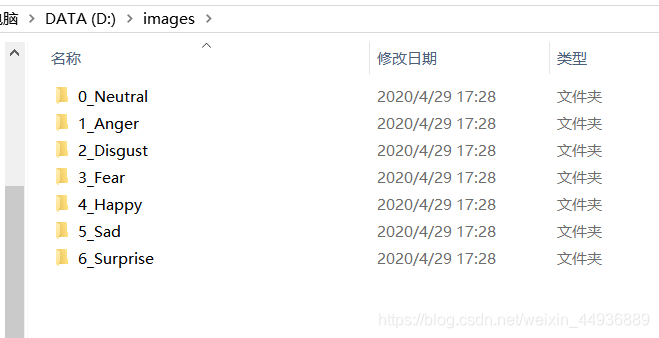
下载后查看一下,包含7个不同情绪:

将压缩包上传到项目:
添加该命令并运行进行解压:
!unzip images.zip

下载预训练模型:
下载后同样上传到项目:

同样解压:
解压完删除命令行命令:

四、代码讲解:
该项目使用 TinYOLO 进行人脸检测,使用 ResNet 进行表情识别;
这一步设置并查看工作路径:
import sys
sys.path.append('/home/aistudio/work')
import os
os.chdir('/home/aistudio/work')
print(os.getcwd())
导入需要的 Python 库:
#导入需要的包
import paddle as paddle
import paddle.fluid as fluid
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import os
import cv2
定义一个数据迭代器并加载数据:
def reader_createor(im_list, label_list):
def reader():
for pt, lbl in zip(im_list, label_list):
im = cv2.imread(pt, 0)
im = cv2.resize(im, (128, 128))
if np.random.random() > 0.5:
im = cv2.flip(im, 1)
yield im, lbl
return reader
base_pt = './images'
datas = []
labels = []
label_list = []
for i, cls in enumerate(os.listdir(base_pt)):
pt = os.path.join(base_pt, cls)
label_list.append(cls)
for im_pt in os.listdir(pt):
datas.append(os.path.join(pt, im_pt))
labels.append(i)
np.random.seed(10)
np.random.shuffle(datas)
np.random.seed(10)
np.random.shuffle(labels)
print(len(datas))
print(datas[0], labels[0])
print(datas[600], labels[600])
定义网络结构,使用一个具有 4 个残差结构的 ResNet,使用 elu 激活:
class DistResNet():
def __init__(self, is_train=True):
self.is_train = is_train
self.weight_decay = 1e-4
def net(self, input, class_dim=10):
depth = [3, 3, 3, 3, 3]
num_filters = [16, 16, 32, 32, 64]
conv = self.conv_bn_layer(
input=input, num_filters=16, filter_size=3, act='elu')
conv = fluid.layers.pool2d(
input=conv,
pool_size=3,
pool_stride=2,
pool_padding=1,
pool_type='max')
for block in range(len(depth)):
for i in range(depth[block]):
conv = self.bottleneck_block(
input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1)
conv = fluid.layers.batch_norm(input=conv, act='elu')
print(conv.shape)
pool = fluid.layers.pool2d(
input=conv, pool_size=4, pool_type='avg', global_pooling=True)
stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
out = fluid.layers.fc(input=pool,
size=class_dim,
act="softmax",
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv,
stdv),
regularizer=fluid.regularizer.L2Decay(self.weight_decay)),
bias_attr=fluid.ParamAttr(
regularizer=fluid.regularizer.L2Decay(self.weight_decay))
)
return out
def conv_bn_layer(self,
input,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
bn_init_value=1.0):
conv = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
bias_attr=False,
param_attr=fluid.ParamAttr(regularizer=fluid.regularizer.L2Decay(self.weight_decay)))
return fluid.layers.batch_norm(
input=conv, act=act, is_test=not self.is_train,
param_attr=fluid.ParamAttr(
initializer=fluid.initializer.Constant(bn_init_value),
regularizer=None))
def shortcut(self, input, ch_out, stride):
ch_in = input.shape[1]
if ch_in != ch_out or stride != 1:
return self.conv_bn_layer(input, ch_out, 1, stride)
else:
return input
def bottleneck_block(self, input, num_filters, stride):
conv0 = self.conv_bn_layer(
input=input, num_filters=num_filters, filter_size=1, act='elu')
conv1 = self.conv_bn_layer(
input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='elu')
conv2 = self.conv_bn_layer(
input=conv1, num_filters=num_filters * 4, filter_size=1, act=None, bn_init_value=0.0)
short = self.shortcut(input, num_filters * 4, stride)
return fluid.layers.elementwise_add(x=short, y=conv2, act='elu')
定义输入输出的占位符:
#定义输入数据
data_shape = [1, 128, 128]
images = fluid.layers.data(name='images', shape=data_shape, dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
定义模型:
# 获取分类器,用cnn进行分类
import math
model = DistResNet()
predict = model.net(images)
print(predict.shape, label.shape)
定义损失函数:
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵
avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值
acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率
定义优化方法:
optimizer =fluid.optimizer.Adam(learning_rate=2e-4)
optimizer.minimize(avg_cost)
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder( feed_list=[images, label],place=place)
定义绘制loss和accuracy变化曲线的函数:
iter=0
iters=[]
train_costs=[]
train_accs=[]
def draw_train_process(iters, train_costs, train_accs):
title="training costs/training accs"
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost/acc", fontsize=14)
plt.plot(iters, train_costs, color='red', label='training costs')
plt.plot(iters, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
定义迭代次数及模型保存路径:
EPOCH_NUM = 20
model_save_dir = "/home/aistudio/data/emotion.inference.model"
训练ing:
for pass_id in range(EPOCH_NUM):
# 开始训练
train_cost = 0
for batch_id, data in enumerate(train_reader()):
train_cost,train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
if batch_id % 100 == 0:
# print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
# (pass_id, batch_id, train_cost[0], train_acc[0]))
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, np.mean(train_cost), np.mean(train_acc)))
iter=iter+BATCH_SIZE
iters.append(iter)
train_costs.append(np.mean(train_cost))
train_accs.append(np.mean(train_acc))
# 开始测试
test_costs = [] #测试的损失值
test_accs = [] #测试的准确率
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=fluid.default_main_program(), #运行测试程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, acc]) #fetch均方误差、准确率
test_costs.append(test_cost[0]) #记录每个batch的误差
test_accs.append(test_acc[0]) #记录每个batch的准确率
test_cost = (sum(test_costs) / len(test_costs)) #计算误差平均值(误差和/误差的个数)
test_acc = (sum(test_accs) / len(test_accs)) #计算准确率平均值( 准确率的和/准确率的个数)
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
['images'],
[predict],
exe)
print('训练模型保存完成!')
draw_train_process(iters, train_costs,train_accs)


定义测试域:
infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
导入人脸检测模型:
from yolo3tiny.detection import Detector, draw_bbox, recover_img
# 这句后面的可以删掉
定义图片读取函数:
def load_image(im):
# 打开图片
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
im = cv2.resize(im, (128, 128))
# 建立图片矩阵 类型为float32
im = np.array(im).astype(np.float32)
im = np.expand_dims(im, axis=0)
im = np.expand_dims(im, axis=0)
# 保持和之前输入image维度一致
print('im_shape的维度:', im.shape)
return im
读取测试数据并进行人脸检测:
im = cv2.imread('a.png')
im = scale_img(im, 416*2)
bboxes_pre = det.detect(
im, confidence_threshold=0.99, nms_threshold=0.3)[0]
result, rois = draw_bbox(im, bboxes_pre*2)
print()
plt.imshow(result[:, :, [2,1,0]])
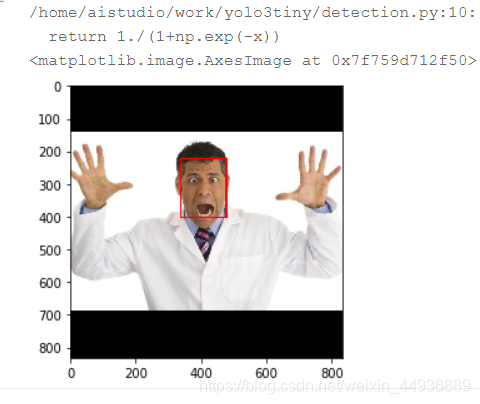
进行表情识别:
with fluid.scope_guard(inference_scope):
#从指定目录中加载 推理model(inference model)
[inference_program, # 预测用的program
feed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
infer_exe) #infer_exe: 运行 inference model的 executor
img = load_image(rois[0])
results = infer_exe.run(inference_program, #运行预测程序
feed={feed_target_names[0]: img}, #喂入要预测的img
fetch_list=fetch_targets) #得到推测结果
plt.imshow(rois[0][:, :, [2,1,0]])
plt.title("infer results: %s" % label_list[np.argmax(results[0])])
plt.show()

五、算法详解:
YOLO 算法详解:
这个我之前写过:
【论文阅读笔记】YOLO v1——You Only Look Once: Unified, Real-Time Object Detection:
https://blog.csdn.net/weixin_44936889/article/details/104384273
【论文阅读笔记】YOLO9000: Better, Faster, Stronger:
https://blog.csdn.net/weixin_44936889/article/details/104387529
【论文阅读笔记】YOLOv3: An Incremental Improvement:
https://blog.csdn.net/weixin_44936889/article/details/104390227
ResNet 算法详解:
这个之前也写过:
残差神经网络ResNet系列网络结构详解:从ResNet到DenseNet:https://blog.csdn.net/weixin_44936889/article/details/103774753
欢迎关注我的主页~
https://blog.csdn.net/weixin_44936889
联系我们:
权重文件需要的请私戳作者~
联系我时请备注所需模型权重,我会拉你进交流群~
该群会定时分享各种源码和模型,之前分享过的请从群文件中下载~