目录

前言
本项目专注于解决出国自驾游特定场景下的交通标志识别问题。借助Kaggle上的丰富交通标志数据集,我们采用了VGG和GoogLeNet等卷积神经网络模型进行训练。通过对网络架构和参数的巧妙调整,致力于提升模型在不同类型交通标志识别方面的准确率。
首先,我们选择了Kaggle上的高质量交通标志数据集,以确保训练数据的多样性和丰富性。接着,采用VGG和GoogLeNet等先进的卷积神经网络模型,这些模型在图像分类任务上表现卓越。
通过巧妙的网络架构和参数调整,本项目致力于提高模型的准确率。我们深入研究了不同交通标志的特征,使网络更有针对性地学习这些特征,从而增强模型在复杂场景下的泛化能力。
最终,本项目旨在为出国自驾游的用户提供一个高效而准确的交通标志识别系统,以提升驾驶安全性和用户体验。这一创新性的解决方案有望在自动驾驶和智能导航等领域产生深远的影响。
总体设计
本部分包括系统整体结构图和系统流程图。
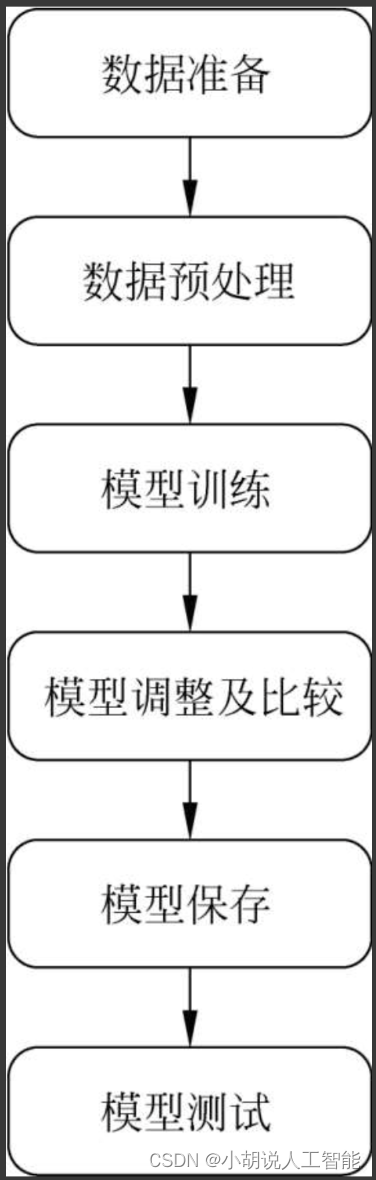
系统整体结构图
系统整体结构如图所示。
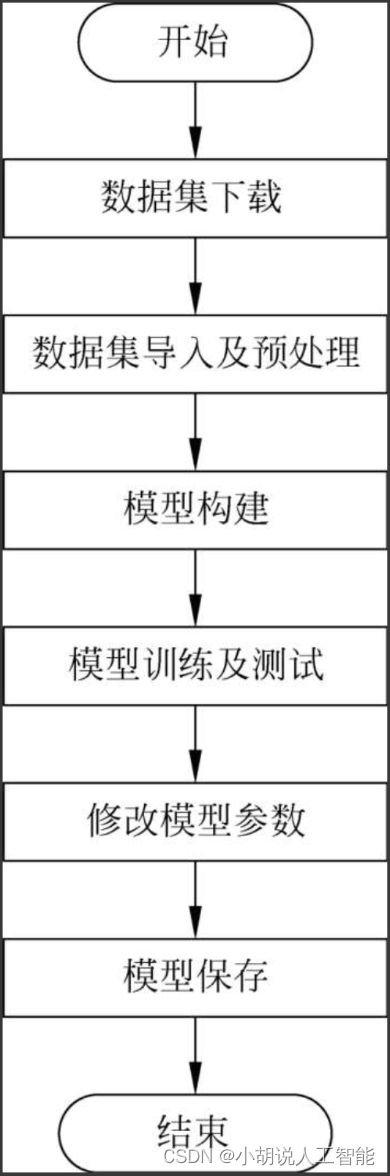
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、Anaconda环境。
详见博客。
模块实现
本项目包括3个模块:数据预处理、模型构建、模型训练及保存。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本项目使用德国交通标志识别基准数据集(GTSRB),此数据集包含50000张在各种环境下拍摄的交通标志图像,下载地址为:https://www.kaggle.com/datasets/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign。数据集下载完成后,导入数据并进行预处理。
详见博客。
2. 模型构建
本部分包括VGG模型和GoogLeNet模型简化版。
1)VGG模型简化版
通过测试各种简化版模型,发现多减少网络的深度(卷积层、池化层、全连接层的层数),少减少网络的宽度(卷积层输出通道数),效果更好。由于本项目的图像尺寸较小,此版模型的卷积层输出通道数只减少为VGG-11的一半。输入图像经过3个卷积层、2个最大池化层、1个全连接层和1个Softmax层。卷积层的步幅为1,通过填充使输出的宽和高与输入相同,前2个卷积层调整为5×5,最后一个卷积层保持3×3不变,3个卷积层的输出通道数依次为32、64和64。2个最大池化层分别位于第2和第3个卷积层后,池化窗口均为2×2,步幅为2,无填充,使输出的宽和高减半,每个最大池化层后接一个参数为0.25的Dropout层防止过拟合。最后是一个输出通道数为256的全连接层和1个Softmax层,全连接层后接1个参数为0.5的Dropout层防止过拟合。
相关代码如下:
#导入需要的包
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
class VGGN:
def build(width, height, depth, classes):
#使用Keras框架的Sequential模式编写代码
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
#卷积核大小为5*5,步幅为1,输出通道数32,填充使得输出的宽和高与输入相同
model.add(Conv2D(32, (5, 5), padding="same",input_shape=inputShape))
#Relu激活函数+批量归一化
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
#卷积核大小为5*5,步幅为1,输出通道数64,填充使得输出的宽和高与输入相同
model.add(Conv2D(64, (5, 5), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
#池化窗口为2*2,步幅为2,不填充,输出的宽和高减半(变为16*16)
model.add(MaxPooling2D(pool_size=(2, 2)))
#最大池化层后接一个参数为0.25的Dropout层防止过拟合
model.add(Dropout(0.25))
#卷积核大小为3*3,步幅为1,输出通道数64,填充使得输出的宽和高与输入相同
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
#池化窗口为2*2的最大池化层,步幅为2,不填充,输出的宽和高减半(变为8*8)
model.add(MaxPooling2D(pool_size=(2, 2)))
#最大池化层后接一个参数为0.25的Dropout层防止过拟合
model.add(Dropout(0.25))
model.add(Flatten())
#输出通道数为256的全连接层
model.add(Dense(256))
model.add(Activation("relu"))
model.add(BatchNormalization())
#全连接层后接一个参数为0.5的Dropout层防止过拟合
model.add(Dropout(0.5))
#最后是一个softmax层输出各类别的概率
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
2)GoogLeNet简化版——MiniGoogLeNet
MiniGoogLeNet由Inception模块、Downsample模块和卷积模块组成,卷积模块包括卷积层、激活函数和批量归一化;Inception模块由两个卷积核大小分别为1×1和3×3的卷积模块并联组成,这两个卷积模块都通过填充使输入输出的高和宽相同,便于通道合并;Downsample模块由一个卷积核大小为3×3的卷积模块和一个池化窗口为3×3的最大池化层并联组成,卷积模块和最大池化层不填充,步幅均为2,使得输入经过后宽和高减半。MiniGoogLeNet的输入图片经过一个卷积模块后输出通道数不同的Inception模块,最后是一个全局平均池化层和一个Softmax层,全局平均池化层将每个通道的高和宽变为1,有效地减少了过拟合。
相关代码如下:
#导入需要的包
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import concatenate
from tensorflow.keras import backend as K
class MiniGoogLeNet:
#定义卷积模块,x表示输入数据,K表示输出通道的数量,KX、KY表示卷积核的大小
def conv_module(x,K,KX,KY,stride,chanDim,padding="same"):
#卷积+激活函数+批量归一化,默认填充使得输出的宽和高不变
x = Conv2D(K, (KX, KY), strides=stride, padding=padding)(x)
x = Activation("relu")(x)
x = BatchNormalization(axis=chanDim)(x)
return x
#定义Inception模块,x表示输入数据,numK1_1,numK3_3表示两个卷积模块输出通道数量
def inception_module(x,numK1_1,numK3_3,chanDim):
#并联的两个卷积模块,卷积核大小分别为1*1和3*3
conv1_1=MiniGoogLeNet.conv_module(x,numK1_1,1,1,(1,1),chanDim)
conv3_3=MiniGoogLeNet.conv_module(x,numK3_3,3,3,(1,1),chanDim)
x=concatenate([conv1_1,conv3_3],axis=chanDim)
return x
#定义Downsample模块,x表示输入数据,K表示卷积模块的输出通道数
def downsample_module(x,K,chanDim):
#并联的卷积模块和最大池化层,均使用3*3窗口,步幅2,不填充,输出的宽和高减半
conv3_3=MiniGoogLeNet.conv_module(x,K,3,3,(2,2),chanDim,padding='valid')
pool=MaxPooling2D((3,3),strides=(2,2))(x)
x=concatenate([conv3_3,pool],axis=chanDim)
return x
#定义模型
def build(width, height, depth, classes):
inputShape = (height, width, depth)
chanDim = -1
#如果通道在前,将chanDim设为1
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
#使用Keras的Model模式编写代码
inputs = Input(shape=inputShape)
#输入图片先经过一个卷积核大小3*3,输出通道数96的卷积模块
x = MiniGoogLeNet.conv_module(inputs, 96, 3, 3, (1, 1),chanDim)
#2个Inception模块(输出通道数32+32、32+48)+1个Downsample模块
x = MiniGoogLeNet.inception_module(x, 32, 32, chanDim)
x = MiniGoogLeNet.inception_module(x, 32, 48, chanDim)
x = MiniGoogLeNet.downsample_module(x, 80, chanDim)
#4个Inception模块(输出通道数112+48、96+64、80+80、48+96)+1Downsample模块
x = MiniGoogLeNet.inception_module(x, 112, 48, chanDim)
x = MiniGoogLeNet.inception_module(x, 96, 64, chanDim)
x = MiniGoogLeNet.inception_module(x, 80, 80, chanDim)
x = MiniGoogLeNet.inception_module(x, 48, 96, chanDim)
x = MiniGoogLeNet.downsample_module(x, 96, chanDim)
#2个Inception模块+1个Downsample模块+1个全局平均池化层+1个Dropout层
x = MiniGoogLeNet.inception_module(x, 176, 160, chanDim)
x = MiniGoogLeNet.inception_module(x, 176, 160, chanDim)
#输出7*7*(160+176)经过平均池化之后变成了1*1*376
x = AveragePooling2D((7, 7))(x)
x = Dropout(0.5)(x)
#特征扁平化
x = Flatten()(x)
#softmax层输出各类别的概率
x = Dense(classes)(x)
x = Activation("softmax")(x)
#创建模型
model = Model(inputs, x, name="googlenet")
return model
3. 模型训练及保存
通过随机旋转等方法进行数据增强,选用Adam算法作为优化算法,随着迭代的次数增加降低学习速率,经过尝试,速率设为0.001时效果最好。调用之前的模型,以交叉熵为损失函数,使用Keras的fit_generator()方法训练模型,最后评估并保存到磁盘。
相关代码如下:
#设置初始学习速率、批量大小和迭代次数
INIT_LR = 1e-3
BS = 64
NUM_EPOCHS = 10
#使用随机旋转、缩放,水平/垂直移位、透视变换、剪切等方法进行数据增强(不用水平或垂直翻转
aug = ImageDataGenerator(
rotation_range=10,
zoom_range=0.15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.15,
horizontal_flip=False,
vertical_flip=False,
fill_mode="nearest")
print("[INFO] compiling model...")
#选用Adam作为优化算法,初始学习速率0.001,随着迭代次数增加降低学习速率
opt = Adam(lr=INIT_LR, decay=INIT_LR / (NUM_EPOCHS * 0.5))
#调用MiniGoogLeNet,使用VGG网络时把MiniGoogLeNet更改为VGGN
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=numLabels)
#编译模型,使用交叉熵作为损失函数
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
#使用Keras的fit_generator方法训练模型
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] ,
epochs=NUM_EPOCHS,
verbose=1)
#评估模型,打印分类报告
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=BS)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
#将模型存入磁盘
print("[INFO]serializing network to'{}'...".format('output/testmodel.pb'))
model.save('output/testmodel.pb')
#绘制loss和accuracy随迭代次数变化的曲线
N = np.arange(0, NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["acc"], label="train_acc")
plt.plot(N, H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig('output/test.png')
相关其它博客
基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(一)
基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(三)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。