聚类是无监督学习中最常用的算法,常用的聚类算法总结。
1、K-means(K均值)聚类:
对于输入样本D={ X1,X2,X3,……,Xn },K-means聚类算法如下:
(1)从D中随机选择K个class center,U1,U2,……,Uk;
(2)对于每个样本Xi,将其标记为距离类别中心最近的类别,即: Yi=argmin ||Xi−Uj||,1≤j≤K,即数据点距离哪个中心点最近就划分到哪一类中;
(3)将每个类别中心更新为隶属该类别的所有样本的均值;
(4)重复(2)和(3)两步,直到直到每一类中心在每次迭代后变化不大为止。也可以多次随机初始化中心点,然后选择运行结果最好的一个。
优点:速度快,适合发现球形聚类,可发现离群点
缺点:
1)对初始聚类中心敏感,缓解方案是多初始化几遍,选取损失函数小的。
2)必须提前指定K值(指定的不好可能得到局部最优解),缓解方法,多选取几个K值,grid search选取几个指标评价效果情况
3)属于硬聚类,每个样本点只能属于一类
4)对异常值免疫能力差,可以通过一些调整(不取均值点,取均值最近的样本点)
5)对团状数据点区分度好,对于带状不好(谱聚类或特征映射)。
尽管它有这么多缺点,但是它仍然应用广泛,因为它速度快,并且可以并行化处理。
2、Fuzzy C-means(模糊C均值)聚类:
给定数据集D={X1,X2,……,Xn},模糊均值聚类算法是最小化下面的目标函数:
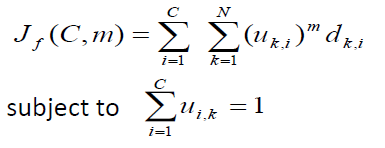
C:类别的种类;
N:样本点个数;
:第k个样本点隶属于第i个类别的隶属函数;
:两个向量的欧式距离;
m:为加权指数,也称平滑因子,控制模式在模糊类间的分享程度;
欧氏距离被定义为:
,vi为每个聚类的中心
聚类中心vi被定义为:
隶属函数
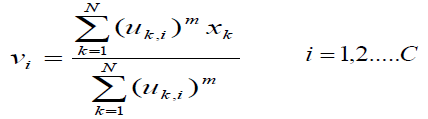
FCM算法步骤:
(1)选择类别的数目C,选择合适的m,初始化由隶属度函数确定的矩阵U0(随机值初始化);
(2)计算聚类的中心支vi;
(3)计算新的隶属度矩阵U1
(4)比较Uj和U(j+1),如果两者的变化小于某个阈值,则停止算法,否则转向(2)。
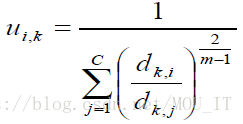
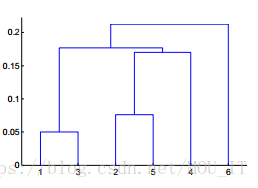
3、层次聚类
也称为凝聚的聚类算法,最后可以生成一个聚类的图,但Python中不容易生成这种图,一般直接在界面软件中生成。其实更像是一种策略算法,画出来有点类似于树模型的感觉。
有自顶而下和自底向上两种,只是相反的过程而已,下面讲自顶而下的思路。
(1)计算所有个体和个体之间的距离,找到离得最近的两个样本聚成一类。
(2)将上面的小群体看做一个新的个体,再与剩下的个体,计算所有个体与个体之间距离,找离得最近的两个个体聚成一类,依次类推。
(3)直到最终聚成一类。
群体间的距离怎么计算:
1)最小值:两个群体之间最近的两个样本点的距离作为群体间的距离
2)最大值:两个群体间最远的两个样本点的距离作为群体间的距离
3)组平均值:一个群体内每一个点和另一个群体内每一个点的具体的累加,然后再除以两个群体点的个数的乘积。
4)形心(重心)距离:两个群体之间的形心之间的距离作为群体间的距离
5)基于目标函数的方法:比如ward方法
优点:不需要确定K值,可根据你的主观划分,决定分成几类。
缺点:虽然解决了层次聚类中K-means的问题,但计算量特别大。与K-means相比两者的区别,除了计算速度,还有K-means只产出一个聚类结果和层次聚类可根据你的聚类程度不同有不同的结果。层次聚类中还有一种是brich算法,brich算法第一步是通过扫描数据,建立CF树(CF树中包含簇类中点的个数n,n个点的线性组合LS=,数据点的平方和SS;而簇里面最开始只有一个数据点,然后不断往里面加,直到超过阈值);第二步是采用某个算法对CF树的叶节点进行聚类。优点就是一次扫描就行进行比较好的聚类。缺点是也要求是球形聚类,因为CF树存储的都是半径类的数据,都是球形才适合。
参考:https://www.cnblogs.com/fionacai/p/5873975.html
https://blog.csdn.net/daisy9212/article/details/48863399