常见的无监督学习类型:聚类任务 密度估计 异常检测
聚类算法试图将样本分成k个不想交的子集,每个子集称为一个簇,对应一些潜在的概念。
样本集x={x1, x2....xm} 每个样本Xi={xi1,xi2...xin}对应n个特征
划分为K个不同的类别C={C1,C2....Ck} ,其中样本xi的簇标记为i,则
={
1,
2,
m}可以表示聚类的结果。
1.性能指标:衡量聚类效果
数据集D={x1,x2..xm} 类别C={C1,C2..Ck} 簇标记向量 参考模型类别C*={C1*, C2*,....Cs*} 簇标记向量
*
定义:

Jaccard系数:
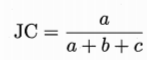
FM系数:

Rand系数:
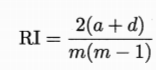
簇划分C={C1,C2..Ck} 定义样本距离dist(xi,xj)
样本中心:![]()
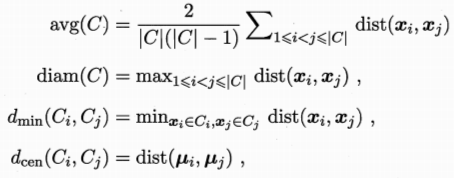
以上依次代表簇C中样本间平均距离 样本间最大距离 两个簇的最小距离 两个簇的中心距离
DB指数:

Dunn指数:
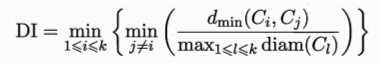
2.距离计算
样本xi={xi1,xi2...xin} 样本xj={xj1,xj2..xjn}
闵可夫斯基距离:

p=2欧式距离:
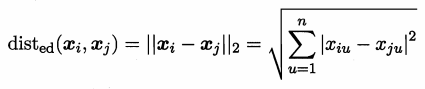
p=1曼哈顿距离:

离散属性等无序属性不能直接计算距离,可采用VDM方式来计算:
mua表示属性u上取值为a的样本数 muai表示在第i个簇中取值为a的样本数 k为总簇数
在属性u上离散值a,b的距离:

当n个属性有nc个有序,后面无序时有:

当不同属性值权重不同时:
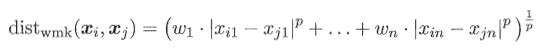
原型聚类
原型:样本空间中具有代表的点
原型聚类:基于原型的聚类算法 K-means均值算法 学习向量量化 高斯混合聚类 密度聚类 层次聚类
1.K-means均值算法
样本集D={(x1,y1),(x2,y2)...(xm,ym)} 簇Ci的均值向量ui
![]()
最小化平方误差:
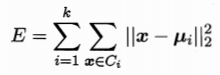
刻画了簇内样本围绕均值向量的紧密程度

给定样本集,从中随机挑选k个样本作为初始均值向量,然后计算各个样本到各个均值向量的距离,对于每个样本,划分到距离均值最近的类中去。划分完毕后,重新计算k个类的均值向量,再次执行划分过程。终止条件:最大迭代系数 最小调整幅度 或者均值向量不再更新。
2.学习向量量化LVQ
数据集D={(x1,y1),(x2,y2)...(xm,ym)} xj=(xj1,xj2...xjn) 类别标记yj={Y} LVQ学得一组原型向量{p1, p2..pq}分别代表q个簇。

初始化q个原型向量,分别预设类别标记{t1, t2...tq} 随机选择一个样本计算该样本到各个原型向量的距离,求出最近的原型向量。比较最近原型向量与样本的类别标记
假设更新完之后的原型向量为p`,其与xj的距离为:

即当0<<1时,新原型向量与样本的距离会减小。
若相同,则原型向量更为:
![]()
若不同,则原型向量更新为:
![]()
继续选择新样本,进行迭代计算
终止条件:最大迭代次数 原型向量不在更新或者更新很小
获得原型向量之后,样本xi可以划分到距离样本最近的原型向量代表的簇中

3.高斯混合聚类
多元高斯分布:
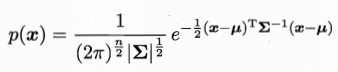
x为n维样本 u为均值向量 方差矩阵
高斯混合分布:

假设样本的生成过程由高斯分布给出:随机变量zj={1,2....k} 表示生成样本xj的高斯混合成分 zj的先验概率对应于ai
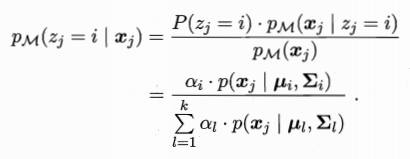
样本xj由第i个高斯混合成分组成的概率pm(zj = i | xj) 记为yji
高斯混合聚类把样本集分为k个簇 C={C1,C2...Ck} 每个簇的标记
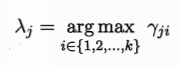
最大化对数似然:

高斯混合模型的EM算法:
E:根据模型参数计算每个样本属于每个高斯成分的后验概率yji
M:根据后验概率来更新模型参数,使最大化对数似然
最大化对数似然,及最大化ui以及i
对于ui求导:
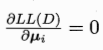

![]()

对于i求导:
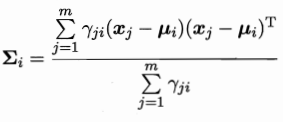
考虑约束:

拉格朗日乘子法:
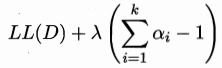
对于ai求导等于0:
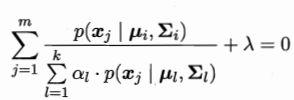
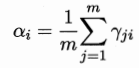
算法流程:

4.密度聚类
给定数据集D={(x1,y1),(x2,y2)...(xm,ym)} 定义:
邻域:
![]()
核心对象:
![]()
密度直达:xi是核心对象 xj位于xi的邻域内,则称xj与xi密度直达
密度可达:对于xi与xj 存在序列p1,p2,,pn p1=xi,pn=xj pi+1由pi密度直达,则xi与xj密度可达
密度相连:存在xk,使得xi,xj均与xk密度相连,则称xi与xj密度相连
簇:由密度可达关系导出的最大密度相连样本集合

5.层次聚类
AGNES自低向上层次聚类:初始每一个样本看成一个簇,然后合并距离最近的两个簇,直到簇总数满足预定条件。
簇距离计算: