回顾
前面,我们介绍了 -近邻算法,其工作机制就是给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
近邻法会涉及到三个问题(三要素):距离度量、 值的选择、分类决策规则,下面我们分别介绍。
距离度量
特征空间的两个实例点的距离度量是两个实例点相似程度的反映。距离小,那么相似度大;距离大,那么相似度小。 -近邻模型的特征空间一般是 维实数向量空间 。使用的距离是欧式距离,但也可以是其他距离,如更一般的 距离( distance)或 距离。
问题定义:设特征空间 是 维实数向量空间 ,
这里 ;
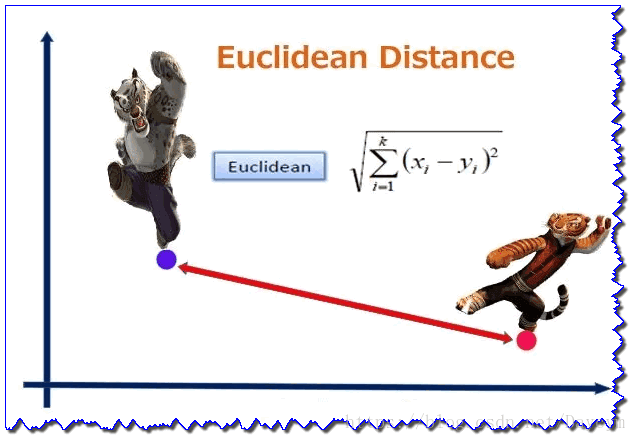
1、欧几里得距离(欧式距离 Eucledian Distance)
欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。
当 时,就是欧式距离,即:
代码:
from math import *
# python3
# 欧式距离
def eculidean_dis(x, y):
return sqrt(sum(pow(a - b, 2) for a, b in zip(x, y)))
x = [1, 3, 2, 4]
y = [2, 5, 3, 1]
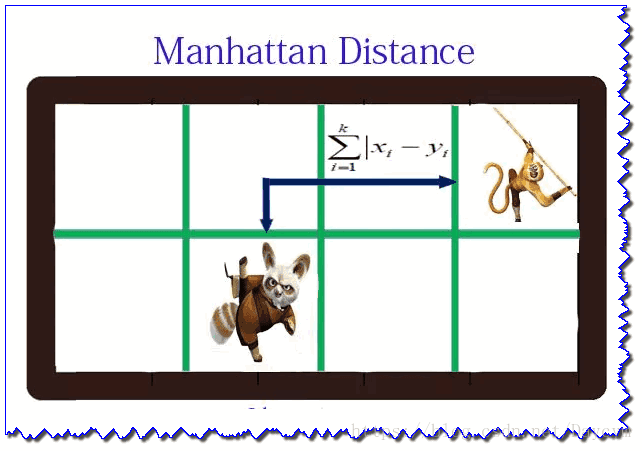
print(eculidean_dis(x, y)) # 结果为3.8729833462074172、曼哈顿距离(Manhattan Distance)
当 时,称为曼哈顿距离,即:
代码:
# 曼哈顿距离
def manhattan_dis(x, y):
return sum(abs(a - b) for a, b in zip(x, y))
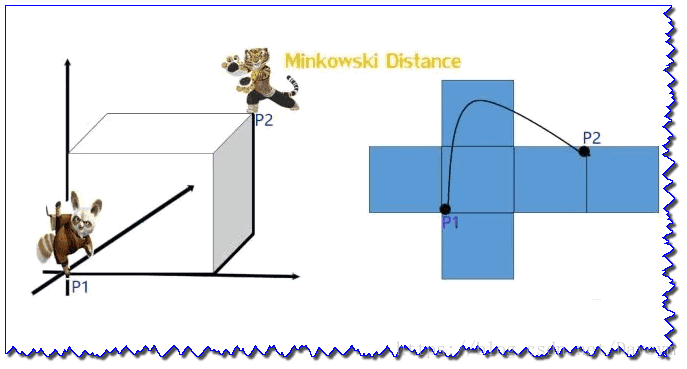
print(manhattan_dis(x, y)) # 结果为73、明可夫斯基距离(Minkowski distance)
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述:
从公式我们可以看出,
- 当p=1,“明可夫斯基距离”变成“曼哈顿距离”
- 当p=2,“明可夫斯基距离”变成“欧几里得距离”
- 当p=∞,“明可夫斯基距离”变成“切比雪夫距离”
代码:
# 明可夫斯基距离
def minkowski_dis(x, y, p):
sumval = sum(pow(abs(a - b), p) for a, b in zip(x, y))
mi = 1 / float(p)
return round(sumval ** mi, 3)
print(minkowski_dis(x, y, 3)) # 结果为3.332值的选择
值的选择会对 近邻法的结果产生重大影响。
如果 值选择较小,就相当于用较小的领域中的训练实例进行预测,“学习”的近似误差会减小,只有与输入实例较近的训练实例才会对预测起作用,但确定是估计误差回增大。预测结果会对近邻的实例点非常敏感,如果近邻的实例点恰巧是噪声,预测就会出错。
相反如果 值选择较大,就相当于用较大的领域中的训练实例进行预测,近似误差会增大,但估计误差会减小。
特例,如果 ,那么无论输入什么实例,都会简单的预测为训练实例中做多的类,这是的模型就没有意义了,丢失了训练实例中的大量有用信息。
在应用中,我们一般取一个较小的 值,通常采用交叉验证法来选取最优的 值。
分类决策规则
近邻法中的分类决策规则往往是多数表决,即由输入实例的 个近邻的训练实例中的多数类决定输入实例的类别。
补充拓展
余弦相似度(Cosine Similarity)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
# 余弦相似度
def cosine_dis(x, y):
num = sum(map(float, x * y))
denom = np.linalg.norm(x) * np.linalg.norm(y)
return round(num / float(denom), 3)
x = np.array([3, 4, 1, 5])
y = np.array([3, 4, 1, 5])
print(cosine_dis(x, y)) # 结果为1,这边是相同的两个向量注:
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近;越趋近于-1,他们的方向越相反;接近于0,表示两个向量近乎于正交。