很久前的草稿了,总结发出来吧,是为了后续的学习比较系统。方法比较简单就不过多写了,从网上东拼西凑出来的。
1.介绍
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。
2.案例
如下图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。
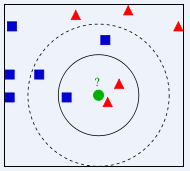
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?假设为K个。从上图中,你能看到:
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,判定绿色的这个待分类点属于蓝色的正方形一类。
如果我们给上图中的每个正方形、三角形和圆打上坐标(以中心为坐标),就可以计算出绿圆到每个样本的距离:
,即欧式几何距离。
3.算法描述:
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;(不用排完,排出最小的K个点就行了)
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类
4.K的取值
K的取法:
常用的方法是从k=1开始,使用检验集估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻。选取产生最小误差率的K。
一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
误差计算:
一般数据集分为样本数据和测试数据,误差可以通过预测测试数据得到的结果与真实结果来计算。
注:K值不能取偶数,因为可能存在最近不同类型样本数量相等的情况。
