KNN(K近邻)算法
前言
因为自己准备数据集耗时耗力还不一定真实,所以小编在此采用scikit-learn数据集
什么是KNN?
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
小编的理解是:根据你的“邻居”判断你的类别
k近邻(KNN)算法是一种简单,易于实现的有监督的机器学习算法,可用于解决分类和回归问题。
举例
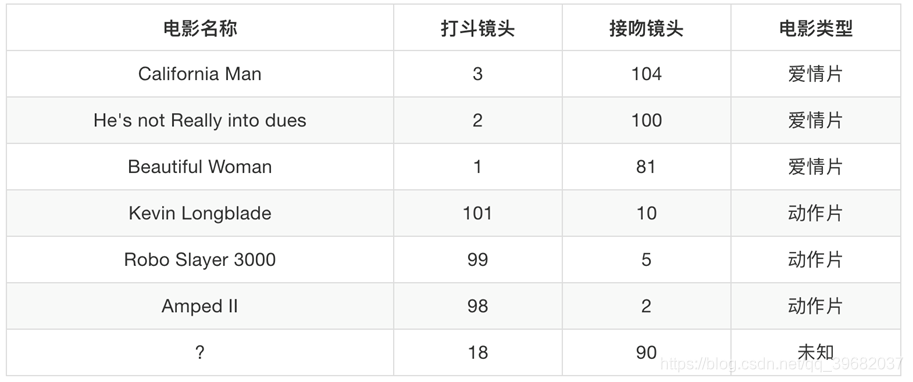
如上图所示,我们将打斗镜头、接吻镜头当作你的特征值,那么电影类型就是你的目标值。那么对于电影名称为“?”,我们怎么判断电影类型?
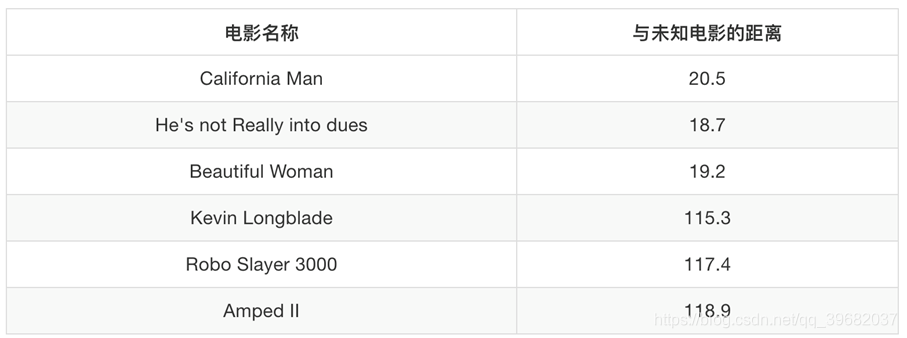
如果在表中在添加如下一列“与目标电影的距离”,我们可以发现电影名称“?”与“He‘s not Really into dues”的距离最近,那么我们就能以此为依据判断“?”的电影类型了。
这个距离怎么计算呢?
两个样本的距离可以通过如下公式计算,又叫欧式距离。
比如说,a(a1,a2,a3),b(b1,b2,b3)
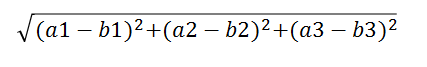
那么对于上述示例而言,以“California Man”举例,其距离为:
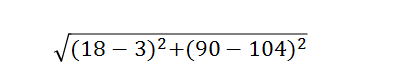
细心的读者一定可以发现,如果根号下两个平方数值差距特别大,(例:根号((100-3)^2 +(14-13)^2),我们会发现这个距离是被(100-3)这部分数值所主导
如何避免这个问题?
KNN算法需要进行标准化!!!
当然,KNN算法中K的取值也会影响最终分类的结果
假设k=1,则取距离最近的1个电影类型来判断“?”的类型
假设k=2,则取距离最近的2个电影类型来判断“?”的类型
假设k=3,则取距离最近的3个电影类型来判断“?”的类型
…
但是这个k不是越大越好
知识储备
sklearn k-近邻算法API:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。(不同实现方式影响效率)
代码演示
这是一个简单的KNN算法流程
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def knn_alg():
'''
classfied iris
:return:None
'''
# 加载数据集
iris_data = load_iris()
#将数据划分为训练集和测试集
#test_size是划分的比例
x_train,x_test,y_train,y_test = train_test_split(iris_data["data"],iris_data["target"],test_size=0.25)
#对特征工程进行标准化
std = StandardScaler()
#对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#进行KNN算法流程
knn =KNeighborsClassifier()
#构造这个模型
knn.fit(x_train,y_train)
#得出预测结果
y_predict = knn.predict(x_test)
print("预测结果", y_predict)
#得出准确率
score = knn.score(x_test,y_test)
print("准确率",score)
return None
if __name__ == "__main__":
knn_alg();
前面小编说过K的取值也会影响KNN算法,所以我们可以对以上流程再做一部分改进
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def knn_alg():
'''
classfied iris
:return:None
'''
# 加载数据集
iris_data = load_iris()
#将数据划分为训练集和测试集
#test_size是划分的比例
x_train,x_test,y_train,y_test = train_test_split(iris_data["data"],iris_data["target"],test_size=0.25)
#对特征工程进行标准化
std = StandardScaler()
#对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#进行KNN算法流程
knn =KNeighborsClassifier()
# #构造这个模型
# knn.fit(x_train,y_train)
#
# #得出预测结果
# y_predict = knn.predict(x_test)
# print("预测结果", y_predict)
#
# #得出准确率
# score = knn.score(x_test,y_test)
# print("准确率",score)
# 构造一些参数的值进行搜索
param = {"n_neighbors": [3, 5, 10]}
# 进行网格搜索
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# 预测准确率
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)
return None
if __name__ == "__main__":
knn_alg();

