# 环境 win10 + py3
一 . k-紧邻算法概述
分类:KNN算法属于监督学习的一种
算法:k-近邻算法采用测量不同特征值之间的距离进行分类
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算的时间和空间复杂度较高
适用数据范围:数值型和标称型
二.k-紧邻算法的一般流程
①收集数据
②准备数据:距离计算所需要的数值,最好是格式化数据
③分析数据
扫描二维码关注公众号,回复:
936675 查看本文章

④测试算法:计算错误率
⑤使用算法
三.使用k-近邻算法原理和python代码实现
原理:对未知分类的数据中的每个点依次执行下面的操作
①计算已知类别的数据集中的每个点和当前点之间的距离
②按距离递增排序
③选取于当前点距离最小的K个点
④确定k个点所在类别出现的概率
⑤返回前k个点出现频率最高的分类,作为预测分类
使用python实现代码如下:
from numpy import *
import operator
def
classify0(
inX,
dataSet,
labels,
k):
'''k-近邻算法'''
dataSetSize = dataSet.shape[
0]
diffMat = tile(inX, (dataSetSize,
1)) - dataSet
sqDiffMat = diffMat**
2
sqDistances = sqDiffMat.sum(
axis=
1)
distances = sqDistances**
0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i
in
range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,
0) +
1
sortedClassCount =
sorted(classCount.items(),
key=operator.itemgetter(
1),
reverse=
True)
return sortedClassCount[
0][
0]
这个函数传入的参数分别是:inX(用于分类的输入向量)
dataSet(输入的训练样本集)
labels(标签向量)
k(最后选择的近邻数目)
核心公式:计算两点之间xA和xB的距离。使用欧氏距离公式
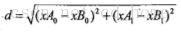
四.实例:使用k-近邻改进约会网站的配对效果
约会网站统计出三条特征值,分别是:
①每周飞行里数
②玩游戏视频消耗时间的百分比
③每周消耗冰淇凌的公升数
目标值:
1.不喜欢
2.魅力一般
3.极具魅力
过程:
①收集数据:本次使用已经存在的数据集,点击下载(只做学习参考,请勿用于商业用途)
②准备数据:使用Python解析文本文件
③分析数据:使用Matplotlib画二维扩散图
④测试算法:
⑤使用算法:
代码如下:
一.首先将文本解析
form numpy import *
def
file2matrix(
filename):
'''将文本记录转换到NumPy的解析程序'''
fr =
open(filename)
# 打开文本
numberOfLines =
len(fr.readlines())
# 获得文本行数
returnMat = zeros((numberOfLines,
3))
# 设置另一维度为3(可以根据需要调整)
classLabelVector = []
fr =
open(filename)
index =
0
for line
in fr.readlines():
# 循环处理每行数据("40920 8.326976 0.953952 3")
line = line.strip()
# 截掉所有的回车字符('40920\t8.326976\t0.953952\t3')
listFromLine = line.split(
'
\t
')
# 使用制表符,将整行数据分割成一个元素列表(['40920', '8.326976', '0.953952', '3'])
returnMat[index,:] = listFromLine[
0:
3]
# 获取前三个元素将他们存储到特征矩阵中
classLabelVector.append(
int(listFromLine[-
1]))
index +=
1
return returnMat,classLabelVector
datingDataMat,datingLabels = file2matrix(
"datingTestSet2.txt")
print(file2matrix("datingTestSet2.txt"))
输出结果如下

二.为了更加直观的了解数据的含义使用Matplotlib使数据可视化
import matplotlib
import matplotlib.pyplot
as plt
fig = plt.figure()
ax = fig.add_subplot(
111)
ax.scatter(datingDataMat[:,
1], datingDataMat[:,
2],15.0*array(
datingLabels),15.0*array(
datingLabels ))
plt.show()
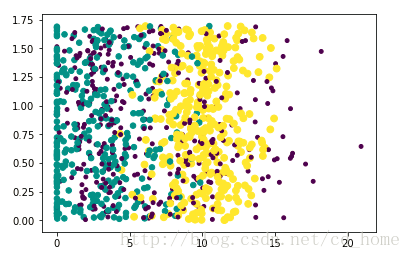
输出效果如下:
横坐标:玩视频游戏的百分比
纵坐标:每周消费的冰激凌公升数
更改字段:
ax.scatter(datingDataMat[:,1], datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels ))
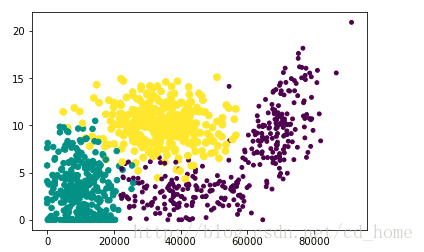
输出效果如下:
横坐标:每年飞行的里程
纵坐标:玩视频游戏所占的百分比
三:归一化数据
根据上面的图片可以看出。如果想计算某两个样本之间的距离,使用欧姓距离公式,因为飞行里程数和其他数据相比十分巨大,会对结果造成关键的影响,但是实际上飞行里程数对分类结果造成的影响应该没有这么巨大。
所以在处理不同取值范围的特征值时,通常采用的方法是将数据归一化。将取值范围处理到0到1,或者-1到1之间。
归一化公式:
newValue = (oldValue-min)/(max-min)
min, max 分别为特征的最小,最大值
### (有点类似于按比例缩小)
归一化python代码实现:
def
autoNorm(
dataSet):
'''数据归一化'''
minVals = dataSet.min(
0)
maxVals = dataSet.max(
0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[
0]
normDataSet = dataSet - tile(minVals, (m,
1))
normDataSet = normDataSet/tile(ranges, (m,
1))
#element wise divide
return normDataSet, ranges, minVals
normMat,ranges,minVals = autoNorm(datingDataMat)
normMat,ranges,minVals
运行结果》》》

四.测试算法
一般情况下使用10%-20%左右的数据作为测试集数据。要求测试数据是在整个样本数据中随机产生的。
代码如下
import operator
def
datingClassTest():
hoRatio =
0.10
#选出10%
datingDataMat,datingLabels = file2matrix(
'datingTestSet2.txt')
#加载数据
normMat, ranges, minVals = autoNorm(datingDataMat)
# 归一化数据
m = normMat.shape[
0]
numTestVecs =
int(m*hoRatio)
errorCount =
0.0
for i
in
range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],
3)
#数据传入分类器
print (
"分类器的计算结果是: %d, 实际的值是: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount +=
1.0
print
(
"分类器的错误率是: %f"
% (errorCount/
float
(numTestVecs)))
print('总共错判:',errorCount)
结果如下:

正确率95%,应该还可以.
## k-近邻算法,k的取值会对正确率产生很大影响,如何确认k的选值十分重要。
五.使用分类器
def
classMan():
iflist = [
'不喜欢',
'有些魅力',
'魅力十足']
ftime =
float(
input(
'每周的飞行时间是:'))
gtime =
float(
input(
'玩游戏所占的时间比是:'))
ice =
float(
input(
'每周消耗的冰激凌公升数:'))
datingDataMat,datingLabels = file2matrix(
'datingTestSet2.txt')
#加载数据
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ftime,gtime,ice])
classifierResult = classify0((inArr -minVals)/ranges,normMat,datingLabels,
3)
print(
'猜你对这个人的感觉是:',iflist[classifierResult-
1])
classMan()
结果如下:

下面是完整代码:
from numpy
import *
import operator
def
file2matrix(
filename):
'''将文本记录转换到NumPy的解析程序'''
fr =
open(filename)
# 打开文本
numberOfLines =
len(fr.readlines())
# 获得文本行数
returnMat = zeros((numberOfLines,
3))
# 设置另一维度为3(可以根据需要调整)
classLabelVector = []
fr =
open(filename)
index =
0
for line
in fr.readlines():
# 循环处理每行数据("40920 8.326976 0.953952 3")
line = line.strip()
# 截掉所有的回车字符('40920\t8.326976\t0.953952\t3')
listFromLine = line.split(
'
\t
')
# 使用制表符,将整行数据分割成一个元素列表(['40920', '8.326976', '0.953952', '3'])
returnMat[index,:] = listFromLine[
0:
3]
# 获取前三个元素将他们存储到特征矩阵中
classLabelVector.append(
int(listFromLine[-
1]))
index +=
1
return returnMat,classLabelVector
# datingDataMat,datingLabels = file2matrix("datingTestSet2.txt")
def
autoNorm(
dataSet):
'''归一化'''
minVals = dataSet.min(
0)
maxVals = dataSet.max(
0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[
0]
normDataSet = dataSet - tile(minVals, (m,
1))
normDataSet = normDataSet/tile(ranges, (m,
1))
return normDataSet, ranges, minVals
def
classify0(
inX,
dataSet,
labels,
k):
'''k-近邻'''
dataSetSize = dataSet.shape[
0]
diffMat = tile(inX, (dataSetSize,
1)) - dataSet
sqDiffMat = diffMat**
2
sqDistances = sqDiffMat.sum(
axis=
1)
distances = sqDistances**
0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i
in
range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,
0) +
1
sortedClassCount =
sorted(classCount.items(),
key=operator.itemgetter(
1),
reverse=
True)
return sortedClassCount[
0][
0]
def
datingClassTest():
'''测试类器正确率'''
hoRatio =
0.10
#选出10%
datingDataMat,datingLabels = file2matrix(
'datingTestSet2.txt')
#加载数据
normMat, ranges, minVals = autoNorm(datingDataMat)
# 归一化数据
m = normMat.shape[
0]
numTestVecs =
int(m*hoRatio)
errorCount =
0.0
for i
in
range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],
3)
#数据传入分类器
print(
"分类器的计算结果是: %d,实际的值是: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount +=
1.0
print(
"分类器的错误率是: %f" % (errorCount/
float(numTestVecs)))
print(
'总共错判',errorCount)
def
classMan():
iflist = [
'不喜欢',
'有些魅力',
'魅力十足']
ftime =
float(
input(
'每周的飞行时间是:'))
gtime =
float(
input(
'玩游戏所占的时间比是:'))
ice =
float(
input(
'每周消耗的冰激凌公升数:'))
datingDataMat,datingLabels = file2matrix(
'datingTestSet2.txt')
#加载数据
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ftime,gtime,ice])
classifierResult = classify0((inArr -minVals)/ranges,normMat,datingLabels,
3)
print(
'猜你对这个人的感觉是:',iflist[classifierResult-
1])
classMan()
总结:主要流程就是数据集的解析,归一化,测试,使用。k-近邻算法对k的选值不好把握。对结果影响也比较大
主要参考:机器学习实战 原书链接
原文使用py2 ,本文使用py3,代码略有不同