1、Introduction
说实话和作者的context encoding那篇有点重了的感觉
作者将字典学习和编码融合到一个模型里面了
- inherent的视觉字典是从损失中直接学习出来的
- 整个的表示是无序的,对于material和texture识别是特别有效的
- 最后的encoder层是传统的residual encoder(VLAD,FISHER)的一个全新的泛化,能够丢弃domain-specific的信息,让学习得到的特征更容易迁徙
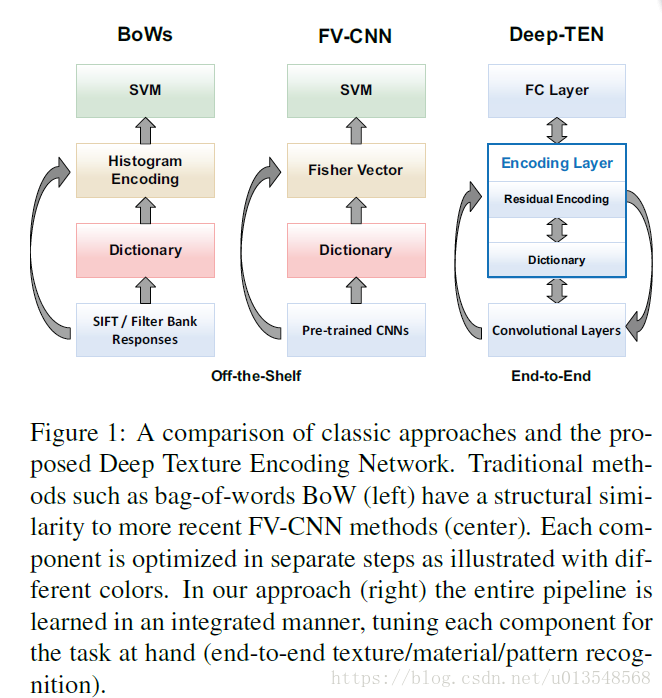
2、 CNN
对于传统的CNN的学习其实是一个类似滑动窗口的学习,最后产生的特征都是ordered,这对于一般的分类,场景识别是很有助益的,但是对于识别纹理来讲却不是那么理想,因为对于纹理来说需要一个空间不变性的表示,而普通的CNN最后的全连接类似于一个concat的操作,这对于texture来讲并不是那么理想。因此orderless的 feature pooling对于端到端的学习就显得尤为重要。重点是要让网络对于网络参数和层数可微
3、Contribution
- 将字典学习和残差编码融合到一个网络里面了
- 新的端到端的网络
新的编码层有三个特点
- Encoder layer泛化了VLAD和Fisher Vector的能力,整个的表示是无序的,对于material和texture识别很有益处
- Encoder layer扮演了pooling的角色,接受任意大小的输入输出固定长度的表示,通过可以接受任意大小的输入使得整个网络自由度更高
- Encoder层学习的字典和编码表示很有可能携带domain-specific信息因此对于pretrained的特征有很好的迁移性。
4、Learnable Residual Encoding Layer(部分参考自己的博客)
Input feature: CXWXH —>
Inherent codebook:
Scaling factors:
最后会输出k个残差编码,
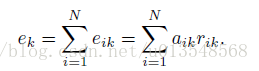
Hard 分配
怎么将每一个 通过 分配给 呢?以前hard的分配是 中最小的哪个直接置 为1
soft 分配
是一个平滑因子
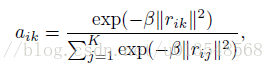
模仿GMM的soft分配
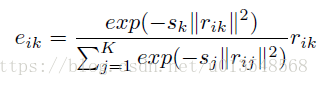
是C维的,最后将k个
融合到一起,这里没有用concat,一方面concat包含了顺序信息,另一方面用加的方法节省了显存。这里加起来的含义是获得整张图像相对于K个语义词的全部信息
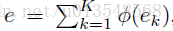
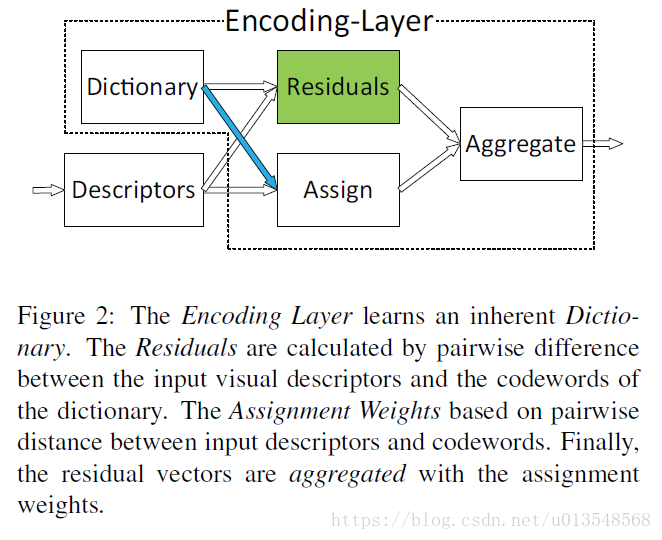
Dictionary learning:
的学习
Residual encoding:
的学习
5、Relation to Dictionary Learning
Relation to Dictionary Learning
Dictionary Learning通常是从descriptor中通过无监督学习到的,例如Kmeans和GMM.如果将上面图中的Residuals(绿色)去掉的话, 趋向于无穷大,此时encoding layer等同于dictionary learning
Relation to BoWs and Residual Encoders
Bow会将每一个descriptor hard分配给最近的那个codeword,统计每一个codeword中descriptor出现的频率
VLAD的改变在于他讲residual vector和hard assignment结合在了一起
NetVLAD
- soft assignment
- assignment weight和dictionary进行了解耦,使得assignment weight仅仅取决于输入的discriptor.,也就是把上图的绿色箭头给去掉了
Fisher Vector同时编码了一阶和二阶的aggregated residual。FV-CNN用现成的residual encoder和CNN,取得了不错的效果
Relation to Pooling
K=1 ,c=0就等同于sum pooling.
6、Deep Texture Encoding Network
FV能够摒弃经常出现在数据集中的特征,通常包含着domain-specific信息。而本文的encoder layer也具有这个特性。
对于频繁出现的
,他有极大的可能接近某个codeword
- 这样, 会很小
- 也会很小
综合上述两点,根据 会很小,这也就是对于频繁出现的descriptor具有削弱功效,对于不同领域的特征迁徙学习很重要
Our Encoding Layer on top of convolution layers accepts arbitrary input image sizes and learns domain independent convolutional features, enabling convenient joint training. We present and evaluate a network that shares convolutional features for two different datasets and has two separate Encoding Layers. We demonstrate joint training with two datasets and show that recognition results are significantly improved.
所以作者在最终的实验里用CIFAR-10和STL-10进行了不同domain的图像的学习,也即在主干网络Resnet20上面加上两个encoder layer,一个用来训练CIFAR-10,一个用来训练STL-10,损失是两个损失的和。发现性能得到了很大的提升。