
- 这是深圳大学、香港城市大学和南洋理工大学发表在CVPR2022的一篇暗图增强的论文
- 网络结构如图所示:
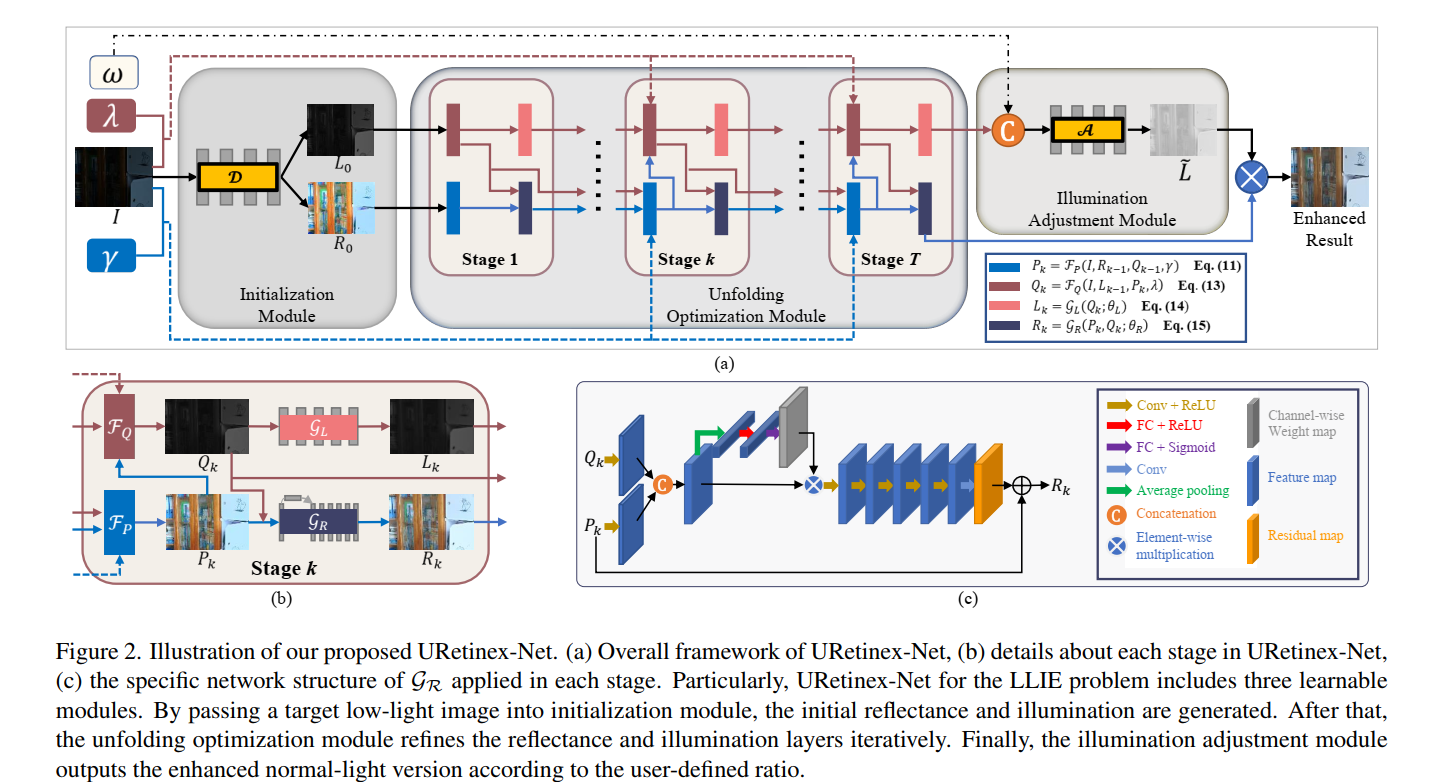
- 左上角首先是初始化模块,对输入的图片送进4层3x3的卷积估计初始的亮度层和照度层。这一模块是单独训练的,同时使用暗图和亮图进行训练,暗图输入时使用以下损失监督:
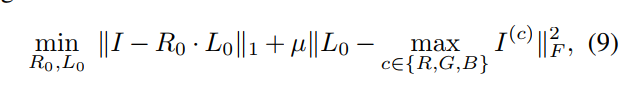
亮图输入时使用以下损失监督,加了一个平滑损失,认为亮图的luminance分量是平滑的:
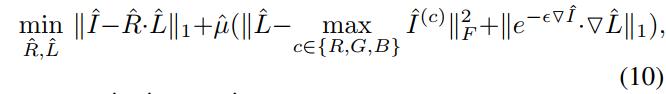
- 在介绍第二个模块前,要讲一下retinex的公式。retinex本来是如下公式,要将 I I I分解为 R R R和 L L L分量,使得 R R R和 L L L分别满足如下公式:
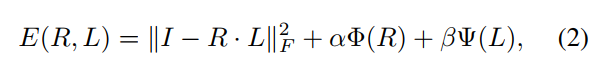
- 使用half quadratic splitting可以将上述优化问题转化为如下形式:
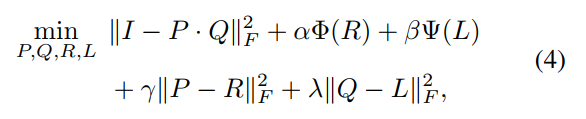
- half quadratic splitting使用迭代的方式对四个分量分别进行优化,因此表现为图中的第二个模块unfolding optimization module,公式则如下:
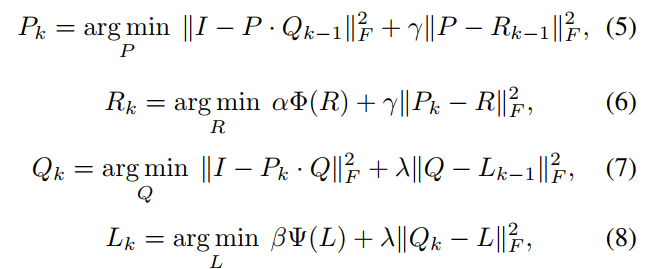
P和Q的最优化都很简单,求梯度等于0即可求得最小值表达式:
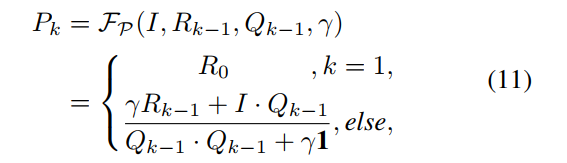
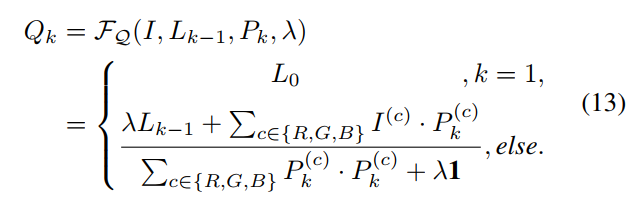
- L和R的优化则借助网络进行,L的预测网络较为简单,5层卷积即可,R的网络在网络结构图右下角展示出来,不同stage的网络参数是share的:
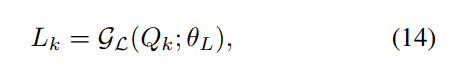
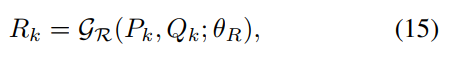
- 两个网络的损失函数如下,其中 R ^ \hat R R^是对应的亮图GT用第一阶段的网络提取的R分量, ϕ \phi ϕ表示vgg,即perceptual损失:
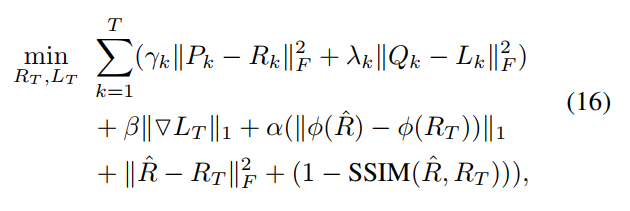
- 然后是第三个illumination adjustment module,是为了对L分量进行调节,但是不要用gamma校正而要用网络(说是suggested in KinD),而且和KinD一样提供了一个可人为调节亮度的因子 ω \omega ω,将 ω \omega ωrepeat成L一样的大小,然后concatenate到后面,一起送进网络(网络的结构和第一个初始化的网络的结构一样,但用了5x5的卷积),这个模块的损失函数如下,带波浪线的即为网络的输出,带盖的是GT的亮度分量(同样是用第一个初始化网络预测的),训练的时候 ω \omega ω设为GT的L除以暗图的L(都是初始化网络预测的)。
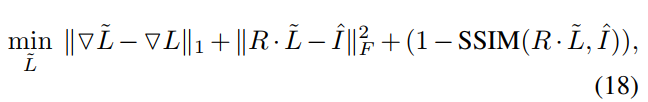
- 网络在LOL数据集上训练和测试,每个模块是单独训练的,中间迭代模块的T=3。
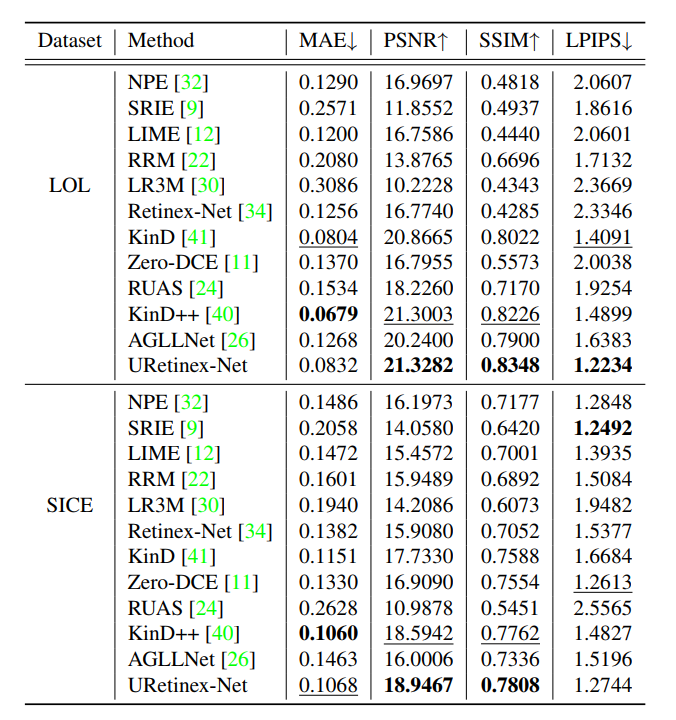
- 实验结果可以看到,LOL上是SOTA:
- 可视化效果也不错,速度则是慢了一点,但也不会特别慢:

- 启发是,最近看到很多用HQS来优化retinex模型的方法,这个工作用网络避免了Retinex的手工设计约束(虽然第一个初始化网络还是用到了),以及一些地方用SSIM损失和梯度的损失避免了亮度的直接对比。感觉文章条理清晰,有理有据,确实是一篇好文章。