文章目录
前提
用一个深度卷积神经网络去回归3DMM形状参数(Note:只是形状!),然后就可以得到3维人脸形状了,至于纹理参数是直接从照片中得来的,这不是作者关注的重点。另外,作者还解决了训练数据集不够的问题,用多张照片去生成3维人脸模型,作为Ground Truth
方法: Regressing 3DMM parameters with a CNN
关键前提
- 可以通过一个人的多张图片获得3d估计
- 高效的深度网络可更鲁棒
1. 训练数据的生成
用中科院的CASIA WebFace dataset,借鉴了论文:
Automated 3D Face Reconstruction from Multiple Images using Quality Measures(CVPR2016) 的方法。多图像 3DMM 重建是通过首先从 CASIA 中的 50 万张单图像中估计 3DMM 参数来执行的。然后,对同一主题图像的 3DMM 估计值聚合到每个主题的单个 3DMM. 也就是对每张人脸图像都进行一次三维重建,在其中选择一定数量可信度较高的结果,以分区的方式按照权重进行结合,从而得到该个体的三维重建结果.
3dmm表示
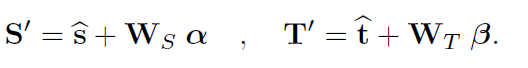
要求的其实就是α和β, 这里说是99维, 我记得咋是199维.
Single image 3DMM fitting
使用前人的方法估计单张图片的近似的形状参数α和纹理参数β,这里作者用了CLNF来做人脸检测,得到68个人脸关键点,求得该张图片的置信度,应该是landmark的置信度, 参见:landmark置信度. 将得到的关键点用来初始化估计人脸模型的姿态,该姿态用六个自由度表示, 三个自由度是旋转角度, 三个是位移. 然后再优化3DMM的形状,纹理,姿态,光照和颜色,利用前人的方法解决定位误差。 一旦损失函数收敛,就得到的形状参数和纹理参数,这就是单个图像得到的3DMM估计,虽然这个过程计算量大,但它只是用在生成数据中,不会影响算法效率
Multi image 3DMM fitting
根据最近的工作,我们将每个对象的多个3DMM(包含形状和纹理)估计进行池化,也就是每个对象的多张照片对应得到的3DMM估计,进行加权求和,最后一个对象只有一个3DMM估计,公式如下:
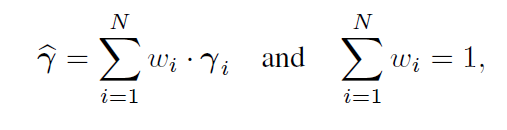
其中wi是由CLNF面部标志检测器提供的归一化的每幅图像的置信度。
3.2. Learning to regress pooled 3DMM
上一个步骤结束之后,一个对象会有多个不同角度的照片,但只有一个3DMM估计。现在我们要用这些数据去学习一个函数,使同一个对象的不同照片得到的3DMM特征向量是相同的。为此,我们引入了一个深度神经网络ResNet,修改了它的最后一层全连接层,使输出为198维的3DMM特征向量γ,用池化的3DMM估计作为真实标注,让网络去学习
The asymmetric Euclidean loss
由构造函数可知,3DMM向量属于多元高斯分布,均值在原点处,代表了均值人脸,就是那个人脸形状和纹理重建公式,因此,在训练期间,如果使用标准的欧拉损失函数来最小化距离,会使得到的人脸模型太泛化,没有区别性。
作者就提出了一个非对称欧拉损失,使模型学习到更多的细节特征,使三维人脸模型具有更多的区别性,公式如下:
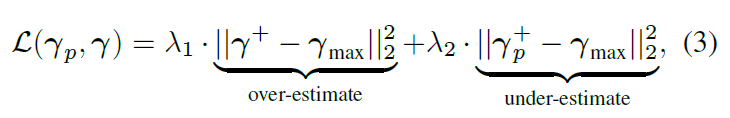
using the element-wise operators:
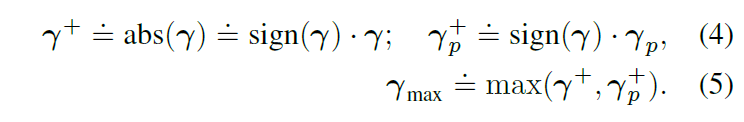
γ是目标池化的3dmm值, γ p γ_p γp是输出, 回归的3DMM. λ1 λ2控制了过度和不足的估计误差之间的权衡。
当两者都等于1时,这就简化为传统的欧几里得损失。在实践中,我们设定λ1=1,λ2=3,从而改变了训练过程的行为,使其更快地摆脱欠拟合,鼓励网络产生更详细、更真实的三维人脸模型。

Network hyperparameters
我们采用mini-batch为144,动量为0.9,L2 weight decay为0.0005的SGD优化器来训练模型。学习速率为0.01.当验证集loss饱和后,我们降低学习速率直至验证集loss停止下降。
3.3 parameter based 3D-3D recognition
CNN神经网络经过训练后,可以将输入图像转换成为3DMM参数 γ p γ_p γp,即 I I I → γ p γ_p γp。我们采用该参数作为人脸特征进行人脸识别。两张人脸的相似度公式为:
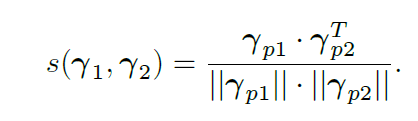
某些情况下,单个个体有一组图片。比如,在YTF数据集中,视频中包含单个个体的多帧图片;在IJB-A数据集中,使用多种数据源(图片,视频),我们每一个视频中人脸帧的3DMM模拟进行pool,得到一个平均的3DMM参数。