Abstract
文章定义了一个新的度量空间,能够将salient区域和非salient分开
Introduction
作者提出了一个在学习到的度量空间中的saliency model。对于部分扭曲的图像作者提出了一种深度的度量学习的方法来解决saliency分割问题。用语义分割的特征来学习一个齐次度量空间。特征是像素级别的,对于前景和背景的区分通过一个distance measure来解决。作者引入了一个基于度量学习和交叉熵的全新的度量函数,和Hypercolumns和UNet很像
Network
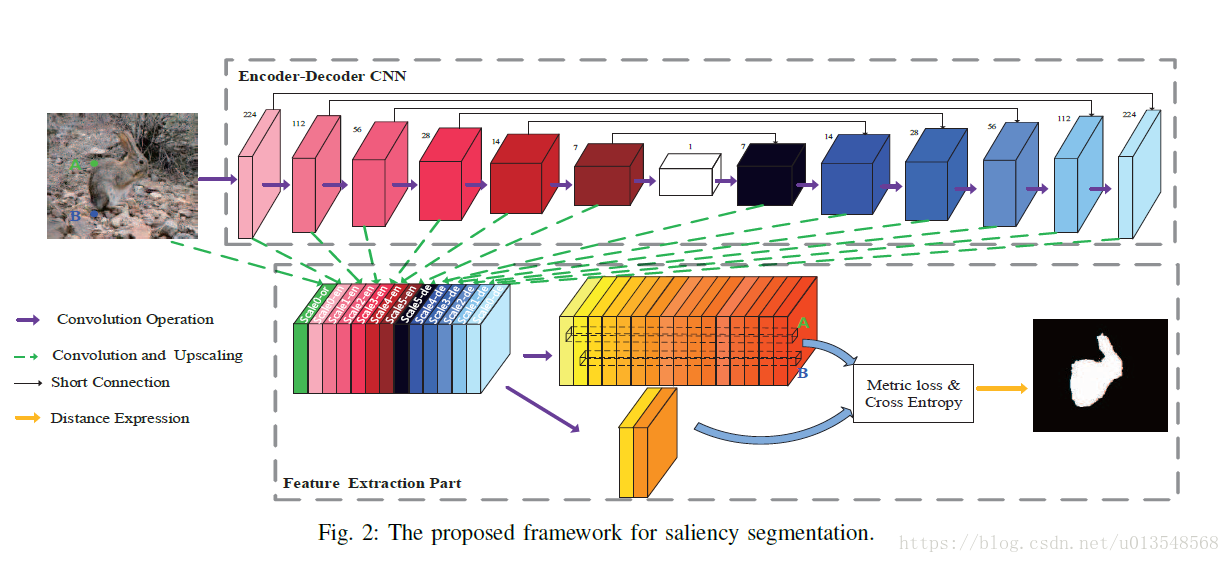
Encoder
在每一个下采样中都会double channel
Decoder
图中白色的地方是1x1的map,对于编辑全局的语义信息很有意义

Concat
对于不同尺度的特征将他们concat在一起,作者将13个不同尺度的特征捆绑在一起,也即concat在了一起,然后用16个通道的卷积去生成相应的特征
和Hypercolumn的区别
Hypercolumn在训练的时候会充分运用多尺度的saliency标签信息用来做分割,但是本文只用了一个尺度的标签
loss
Traditional loss
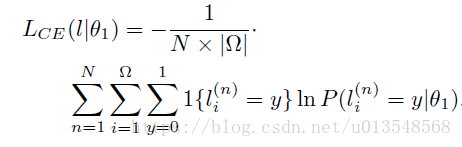
y = 1代表是saliency像素,y = 0代表室非saliency像素,
是指第i个位置地方出现y=0或者1的概率,因为需要预测两个y=0和y=1都要预测,所以需要两个kernel来进行卷积。
Metric learning
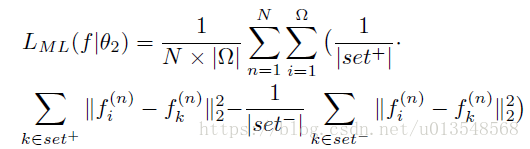
其中
代表要学习的参数,此时的feature map大小为WxHxC,C=16,上一部分已经提到了。
代表的是一个batch里的第n张图片的WXHXC的feature map的第i个位置的长度为C的特征向量
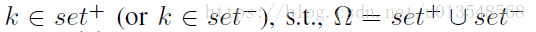
当
,表示
和
是来自同一个区域,也即要么都是saliency区域,要么都是非saliency区域,否则的话
和
是来自不同的区域
这个损失函数寻求扩大不同区域的向量之间的距离,减小相同区域间的距离,因此saliency和非saliency区域是各向同性的,因此整个的损失可以进行简化
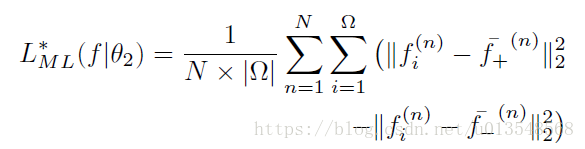
代表的是与
是同一个区域的所有的向量的均值,
代表的是与
是不同区域的所有的向量的均值,上面的公式能够让同一个区域提取出来的向量在salient特征空间上接近那个区域的中心,在salient特征空间上而远离其他区域的中心,这里必须要强调在salient特征空间上,因为只有在这个空间相同区域的特征才会有一个中心,只有在特征层面上去理解才可以。(其实细想想对于saliency分割,同一个区域不同位置的特征向量应该是很相近的,中心距离他们应该都比较近的)
最后的总的损失

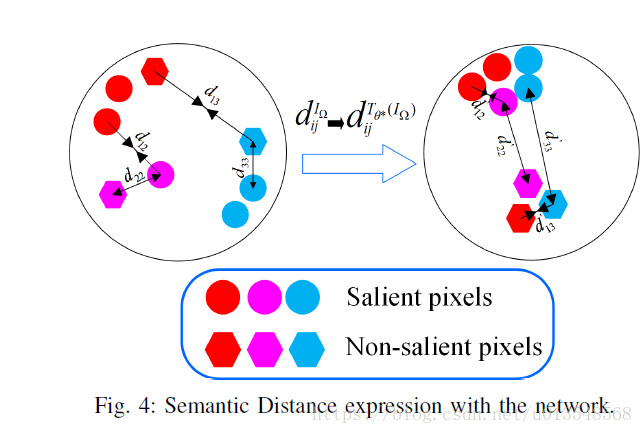
Semantic distance expression
最后的S map通过以下公式获得
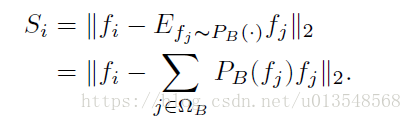
代表的是背景, 代表的是前景,上面的公式表示如果i是前景,减去背景的期望,因为二者相差很大,此时的结果很大;如果i是背景,背景和背景的期望应该会很小,所以此时的结果应该为0。
Experiment
略