一、t-SVD-MSC
(1)t-SVD有类似于SVD的优良性质
(2)多视图聚类有两大原则:视图间的一致性;视图间的互补性。
(3)张量的核范数为什么可以挖掘高阶信息?因为张量的核范数是由各个视图矩阵循环排列堆叠成新矩阵再进行求核范数得到的。即:


(4)张量旋转的意义:通过旋转在傅里叶得到的频域计算比较方便;旋转后每个前置切片都有不同的样例和视图;降低了复杂度。
(5)奇异值分解用在哪?怎么用?用在求解参数上,做聚类用谱聚类,需要相似度矩阵,用张量扩展LRR的方法模型化数据的重建过程来求得相似度矩阵,求解模型的时候需要用ADM的方法迭代求解每个参数,多视图求相似度是把多个相似度矩阵堆叠成一个tensor再进行旋转,奇异值分解就用在求解这个旋转后的张量上。用法:求解这个张量需要采用一种针对张量奇异值分解的算法,这个算法为了降低计算复杂度,采用在傅里叶之后的频域进行SVD分解的形式,然后再进行逆傅里叶变换,得到待求张量。
二、Kt-SVD-MSC
三、检索
(一)整体流程
1.基本思想:多索引融合,也即多特征融合,是将原始特征进行转换得到新特征(也叫索引),采用一定的算法,得到一个可以更新原始索引的作用矩阵,使得更新后的索引,图像相似的索引更相似,图像不相似的进行推远,完成训练过程得到数据库。在测试阶段,输入一张图像,提取特征并得到索引,与数据库中的训练集分别进行距离比较即可得到搜索结果。
2.基本步骤:
采用多视图索引融合(MMF)算法对图像进行检索分为下面几步:
阶段一:训练集图片:①提取多种特征(如A,B,C)-》②分别采用BOW得到新特征-》③采用MMF算法求得作用矩阵-》④用求得的作用矩阵Z分别更新②中得到的特征-》⑤使用倒排索引得到数据库(为了加快搜索速度)
阶段二:测试集图片:①选择一种特征并提取(如A)-》②采用BOW得到新特征-》③将②中的特征与训练集中图片的A特征进行余弦距离比较,返回距离最小的几个结果。
注意:以上是无监督的过程,所谓训练阶段不过是把数据库中的图片进行组织起来,没有标签。
(二)细节
1.阶段一中的②是怎么执行的?
对一张图片提取多个特征(注意不是种),然后聚类得词典,然后在此字典下得到新特征(即索引),方法如词频、直方图等。
详细参考: https://blog.csdn.net/xuzhongxiong/article/details/52689048
2.阶段一中的③是怎么求的?
采用多视图自表示的方法,下面的Z即是作用矩阵。
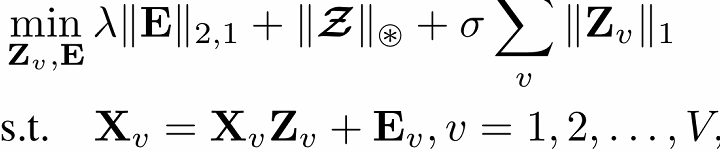
3.阶段一中的④是怎么更新的?为什么这么更新可以达到推远推近的效果?
多视图更新是这样的:(单视图可类比)

为什么会靠近或者推远?比如a和b两个数据,a更新为a=a(1+z)=a+lmbda*b,(Z(i,j)跟b有关),z>0时,a归一化后就会变得跟b相似,相当于把别人的部分加过来就会跟它相似。z<0时,反过来即可得知相似度变小。
4.阶段一中的⑤有什么作用?具体怎么实现的?
就是为了加快搜索速度呗,具体实现方式,原理参考:https://blog.csdn.net/hackerose1994/article/details/50933396
(三)实验
1.实验数据集信息
holiday数据集:1491张,500张做测试,对训练集全部按距离进行排序,给出这种排序即可。
2.所用特征
SIFT特征:新特征维度为20000*1491,较稀疏,SIFT原理详见:https://blog.csdn.net/jianghuxiaojin/article/details/51770896
Alexnet特征:模型图参考:https://www.sohu.com/a/134347664_642762
VGGNet特征:模型图参考:https://www.sohu.com/a/134347664_642762
3.结果评价指标及结果
mAP:平均精度均值,一般用在检索中,跟顺序有关。详见:https://blog.csdn.net/u011501388/article/details/77962401
(四)总结
1.优点
多视图融合提高准确率
2.局限性
针对小数据集,大数据搜索不行,因为计算Z需要内存开销很大,与X大小有关。