聚类是一种常见的数据分析工具, 其目的是把大量数据点的集合分成若干类, 使得每个类中的数据之间最大程度地相似, 而不同类中的数据最大程度地不同。聚类在数据挖掘、数据管理(数据索引、检索)领域有着广泛的应用。聚类的种类如下图所示。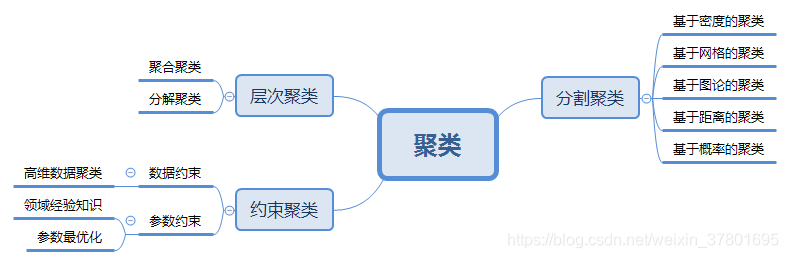
1、 层次聚类算法
聚合聚类的策略是先将每个对象各自作为一个原子聚类, 然后对这些原子聚类逐层进行聚合, 直至满足一定的终止条件。分解聚类与聚合聚类相反。
2、 分割聚类算法
(1)基于密度的聚类
基于密度的聚类算法从数据对象的分布密度出发, 将密度足够大的相邻区域连接起来, 从而可以发现具有任意形状的聚类, 并能有效处理异常数据。它主要用于对空间数据的聚类。DBSCAN是一个典型的基于密度的聚类方法。
(2)基于网格的聚类
基于网格的聚类从对数据空间划分的角度出发, 利用属性空间的多维网格数据结构, 将空间划分为有限数目的单元的网格结构。该方法的主要特点是处理时间与数据对象的数目和顺序无关, 但与空间所划分的单元数相关;而且, 基于其间接的处理步骤(数据->网格数据->空间划分->数据划分)。基于网格的聚类可以处理任意类型的数据, 但以降低聚类的质量和准确性为代价。
(3)基于图论的聚类
基于图论的方法是把聚类转换为一个组合优化问题, 并利用图论和相关的启发式算法来解决该问题。其做法一般是先构造数据集的最小生成树MST, 然后逐步删除MST中具有最大长度的那些边, 从而形成更多的聚类。基于超图的划分和基于光谱的图划分方法是这类算法的两个主要应用形式。该方法的一个优点在于它不需要进行一些相似度的计算, 就能把聚类问题映射为图论中的一个组合优化问题。
(4)基于概率的聚类
基于概率分析,不断将更新类别中心,对数据集进行重新分配以获得最优解
(5)基于距离的聚类
基于距离分析,不断将更新类别中心,对数据集进行重新分配以获得最优解
3、 约束聚类
约束的聚类通常只用于处理某些特定应用领域中的特定需求
(1)参数约束
真实世界中的聚类问题往往是具备多种约束条件的, 这里的约束可以是对个体对象的约束, 也可以是对聚类参数的约束, 它们均来自相关领域的经验知识,例如对地理空间中的点进行聚类,需要计算地理距离。可以利用领域知识和历史数据,对参数进行选择,使参数选择更有针对性。可以基于进化理论不断优化可选方案从而得到最终的聚类结果。利用进化理论进行聚类的缺陷在于它依赖于一些经验参数的选取, 并且具有较高的计算复杂度,通常将进化理论与聚类算法相结合进行参数的选取。
(2)数据约束
对高维数据聚类的困难主要来源于以下两个因素:①高维属性空间中那些无关属性的出现使得数据失去了聚类趋
势;②高维使数据之间的区分界限变得模糊。对高维数据进行聚类前,可以先进行降维、特征提取、特征选择。
寻求聚类方法是在需求、聚类质量、算法时间复杂度之间的折中也是一个重要的问题。
4、 常用算法效果对比
Sklearn中聚类算法效果和适用场景比较如下图所示。
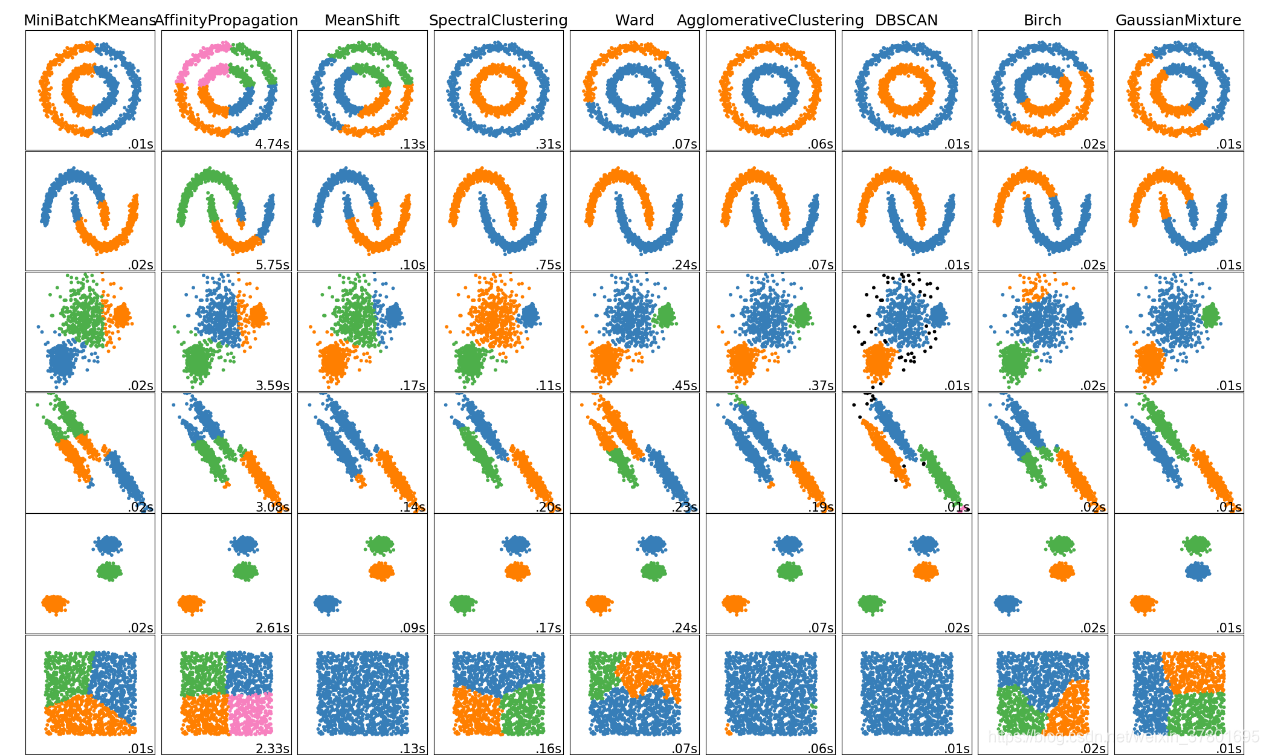
参考论文《数据挖掘中的聚类算法综述》。文章编号:1001-3695(2007)01-0010-04
写博客的目的是学习的总结和知识的共享,如有侵权,请与我联系,我将尽快处理