一、介绍
DBSCAN是一种著名的基于密度的聚类算法,是Martin Ester、Hans-Peter Kriegel等人在1996年提出来的(参考文献:A density-based algorithm for discovering clusters in large spatial database)。该算法能够有效处理噪声点和发现任意形状的空间聚类,与k-means聚类算法相比,不需要输入要划分的聚类个数。
二、相关概念
要理解DBSCAN算法,首先要清楚以下相关概念:
定义1:(e-领域) :点p的e-邻域记作:
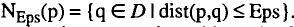
即:以p为圆心,e为半径的范围里,所有的点q的集合。
定义2:(直接密度可达):如果:
(1)点p在点q的e-领域内
(2)在点q的e-领域内,至少包含MinPts个点
那么点p由点q直接密度可达,满足第2个条件的点q,被称为核心点(core point)。
定义3:(边界点):边界点(border point)不是核心点,因为它不满足其e-邻域内,至少包含MinPts个点,但边界点在其他核心点的e-邻域内。
定义4:(密度可达):如果有一连串的点p1,…,pn,p1=q,pn=p并且pi+1由pi直接密度可达,则称点p由点q密度可达。
定义5:(密度相连):如果有一个点o,点p和点q都由点o密度可达,那么称点p和点q密度相连。
定义6:(簇):一个簇(cluster)是一个非空集合,并且满足以下条件:
(1)对于所有的点p和点q,如果点p在簇内,并且点q由点p密度可达,那么点q也在簇内
(2)对于所有在簇内的点p和点q,点p和点q密度相连
定义7:(噪声):噪声(noise)是不包含于任何一个簇内的点。
引理:如果点p是一个核心点,那么由点p密度可达的所有点组成的集合就是一个簇。
综上所述:DBSCAN将数据点划分为三类:核心点、边界点、噪声;点与点之间的状态有3种:直接密度可达,密度可达,密度相连;DBSCAN有两个参数:e和MinPts。所以参数不同,得到的结果就不同,因此要不断地调参进行试验以找到理想的结果。
三、伪代码

说明:
(1)ClusterId:=nextId(NOISE),这句话的意思是首先从数据集中任选一个核心点为“种子”再由此出发确定相应的聚簇类,如果选到了一个噪声或边界点,肯定是无法扩展了,因此就需要重新再选一个点。这其实是一个初始化过程,初始化了ClusrerId。
(2)ExpandCluster是最重要的一个函数,如果它返回False,则说明这个点Point是一个噪声或者是一个边界点;如果它返回True,则说明一个簇形成了,要进行下一个簇的聚类。
(3)一定要注意,在论文的伪代码中,把噪声和边界点都标记为了NOISE。

说明:
(1)首先计算传进来的Point的e-邻域,并把每个范围内的点加入到队列。如果不是核心点就返回False,如果是核心点,就进行扩展,目的就是找出所有由Point密度可达的点。
(2)被标记为NOISE的点在稍后可能会改变,因为它可能是一个边界点。但是代码里并没有对这类点进行处理,因为边界点不会改变结果。
四、利用sklearn进行DBSCAN聚类
除了可以自己写代码实现DBSCAN,也可以利用第三方类库进行简单调用。
首先需要安装第三方类库sklearn、numpy,之后导入相应的模块进行初始化创建对象
from sklearn.cluster import DBSCAN
import numpy as np
DBSCAN(eps=3, min_samples=2)
一般情况下,就是调节前两个参数eps和min_samples,其他的参数(如:度量方式、近邻搜索算法等)详情可参考scikit-learn的官方文档,有详细的说明。
接下来就是对数据集的聚类:
X = np.array([[1, 2], [2, 2], [2, 3], [8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
最后就是输出聚类结果(每个数据点的标签,标签值为-1的是噪声):
labels = clustering.labels_
也可以使用一个函数完成上述两个功能:
fit_predict(X)
输出类簇的个数:
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
利用matplotlib进行数据可视化:
import matplotlib.pyplot as plt
labels = DBSCAN(eps=3, min_samples=2).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.show()