版权声明:其他网站转载请注明原始链接,尽量不要破坏格式 https://blog.csdn.net/landstream/article/details/80865262
DBSCAN
Density-Based Spatial Clustering of Applications with Noise
——基于密度的噪声下聚类算法
核心定义
Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;
核心对象:如果给定对象Ε邻域内的样本点数大于等于MinPts,则称该对象为核心对象;
直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
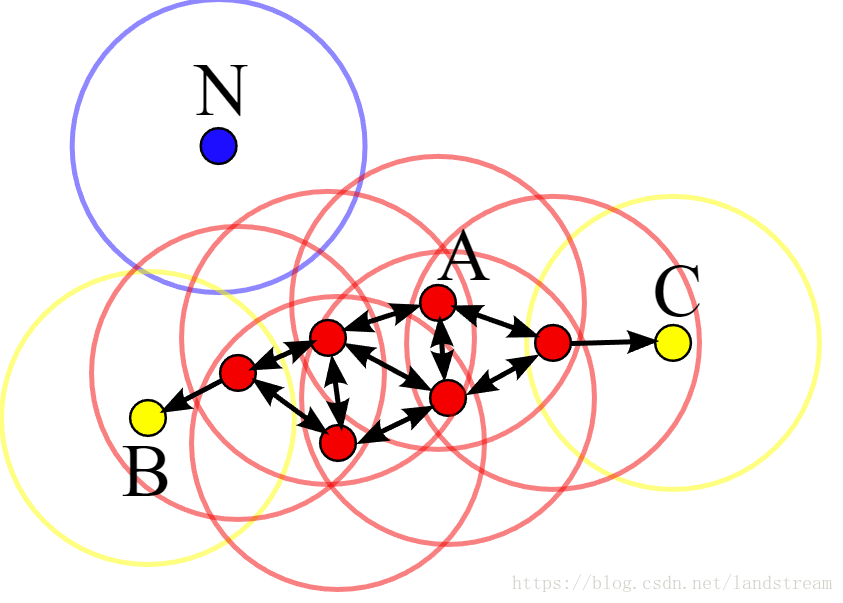
上图是一个DBSCAN算法示例,其中圆形的半径是E;红色点是核心对象;黄色点是从核心对象密度可达的非核心对象,因而同样属于A所在的簇;蓝色的点是噪声。
In this diagram, minPts = 4. Point A and the other red points are core points, because the area surrounding these points in an εradius contain at least 4 points (including the point itself). Because they are all reachable from one another, they form a single cluster. Points B and C are not core points, but are reachable from A (via other core points) and thus belong to the cluster as well. Point N is a noise point that is neither a core point nor directly-reachable[1].
注意,这里请区分密度可达和密度相连这两个概念,密度可达一定密度相连,但密度相连却不一定密度可达。
密度相连是密度可达的必要条件。
算法描述
DBScan需要二个参数: 扫描半径 (eps)和最小包含点数(minPts)
输入: 包含n个对象的数据库,半径e,最少数目MinPts;
输出:所有生成的簇,达到密度要求。
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF 抽出的点是核心点
THEN
找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE
抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
算法改进
提升此类算法性能的方法主要包括:
- 通过减少扫描核心数据集的次数来降低I/O开销;
- 在GPU的基础上重新改写算法实现方法,降低距离计算和比较的时间开销——CudaSCAN[2];
[2]Loh W K, Yu H. Fast density-based clustering through dataset partition using graphics processing units ☆, ☆☆[J]. Information Sciences, 2015, 308(C):94-112.