参考b站不会还有人不知道最新版2022年的李宏毅——机器学习与深度学习吧?_哔哩哔哩_bilibili
分类
1、监督学习:
从给定的训练数据集中学习一个函数(模型),当新数据(测试集)来到时,根据这个函数预测结果
(1)回归
(2)分类
决策树、随机森林、逻辑回归
2、无监督学习:
输入数据没有标记,也没有确定结果(样本数据类别未知),需要根据样本间的相似性对样本进行
试图使类内差距最小化,类间差距最大化
(1)聚类:K-means
(2)降维 : PCA降维算法
线性回归
1、特点:
利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
用线性的关系来拟合一个事情的发生规律,找到这个规律的表达公式,将得到的数据带入公式以用来实现预测的目的。
应用场景:
- 房价预测
- 销售额度预测
- 贷款额度预测
2、两种模型:
(1) 线性关系:
- 单变量线性关系
- 多变量线性关系
(2)非线性关系:回归方程w1x1+w2x2+w3x3
- 单变量回归:只有一个自变量的情况
- 多元回归:多于一个自变量情况
3、
(1)损失函数:计算误差的函数,欧氏距离加和其实就是用来量化预测结果和真实结果的误差的一个函数。
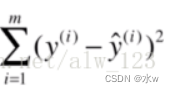
我只要找到一组参数(也就是线性方程每一项上的系数)能让我的损失函数的值最小,那我这一组参数就能最好的拟合我现在的训练数据。
(2)最大似然估计:最大可能性估计
P(x1,x2 ... xn)= P(x1) * P(x2) ... P(xn)的发生概率最大(3)最小二乘公式
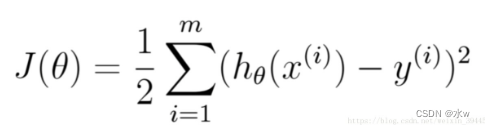
逻辑回归
1、特点:
监督学习就是在用回归的办法做分类任务:
按照多元线性回归的思路,我们可以先对这个任务进行线性回归,学习出这个事情结果的规律,比如根据人的饮食,作息,工作和生存环境等条件预测一个人"有"或者"没有"得恶性肿瘤,可以先通过回归任务来预测人体内肿瘤的大小,取一个平均值作为阈值,假如平均值为y,肿瘤大小超过y为恶心肿瘤,无肿瘤或大小小于y的,为非恶性.这样通过线性回归加设定阈值的办法,就可以完成一个简单的二分类任务。
是使训练数据的标签值与预测出来的值之间的误差最小化。如何使得所有的训练数据距离分类超平面的距离综合最远
2、使用线性模型进行分类遇到的问题:
(1)如何降低离群值的影响,
(2)在正负例数据比例相差悬殊时预测效果不好.为什么会出现这种情况呢?原因来自于逻辑回归交叉熵损失函数是通过最大似然估计来推导出的。
使用最大似然估计来推导损失函数,那无疑,我们得到的结果就是所有样本被预测正确的最大概率.注意重点是我们得到的结果是预测正确率最大的结果,100个样本预测正确90个和预测正确91个的两组w,我们会选正确91个的这一组.那么,当我们的业务场景是来预测垃圾邮件,预测黄色图片时,我们数据中99%的都是负例(不是垃圾邮件不是黄色图片),如果有两组w,第一组为所有的负例都预测正确,而正利预测错误,正确率为99%,第二组是正利预测正确了,但是负例只预测出了97个,正确率为98%.此时我们算法会认为第一组w是比较好的.但实际我们业务需要的是第二组,因为正例检测结果才是业务的根本.
3、一般用于二分类问题中,给定一些输入,输出结果是离散值。
例如用逻辑回归实现一个猫分类器,输入一张图片 x ,预测图片是否为猫,输出该图片中存在猫的概率结果 y。
4、分类思想:
当一个训练样本的标签为1时,那逻辑回归的输出p越大越好;(距离d越大,概率p越大,符合标签为1的情况)
当标签为0时,p越小越好。(距离d越大,概率p越小,符合标签为0的情况)
5、
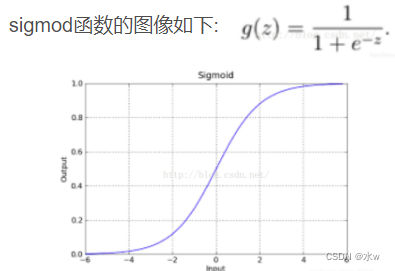
(1)sigmod函数:
具有很强的鲁棒性:预测结果为一个0到1之间的小数
可以解决利用线性回归的办法来拟合然后设置阈值的办法容易受到离群值的影响
(2)交叉熵损失函数:交叉熵损失函数的梯度和最小二乘的梯度形式上完全相同,区别在于此时的h_{\Theta}(x) = g(z),而最小二乘的h_{\Theta} = W^{T}X.
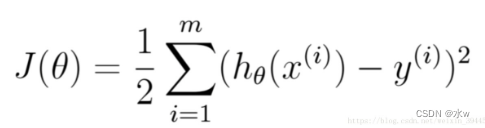
SVM支持向量机
1、特点:
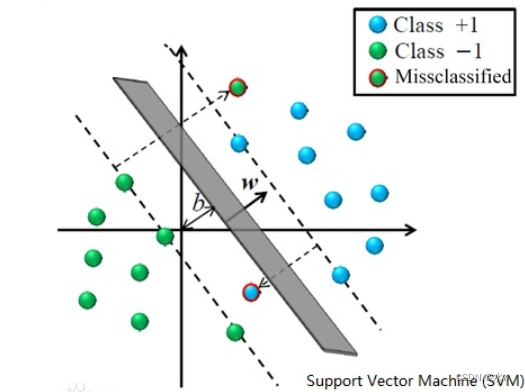
是一个二分类线性分类器
学习策略:
在分类超平面的正负两边各找到一个离分类超平面最近的点(也就是支持向量),使得这两个点距离分类超平面的距离和最大
分类策略的目的:
在保证对训练数据分类正确的基础上,对噪声设置尽可能多的冗余空间,提高分类器的鲁棒性
2、SVM终极目标:
求出一个最优的线性分类超平面wx+b=0
要求:
所有训练数据点距离最优分类超平面的距离都要大于支持向量距离此分类超平面的距离
支持向量点到最优分类超平面距离越大越好
3、
(1)如果我们能保证训练数据是绝对线性可分且噪声很小的,那我们当然可以用最基础的线性SVM,构造目标函数和强硬的约束项,借助拉格朗日对偶求解最优分类超平面;
(2)如果训练数据不是线性可分或噪声较大,那么我们很难用基础的线性SVM对其进行有效地分类,此时有两种方法:
1.允许一部分训练数据点不满足强硬的约束(软间隔),转而将之写入loss中;
背景:在上述的SVM的求解方法中,我们的约束项实在是太强了。在实际的数据中,我们很难拿到线性可分的数据,同时,训练数据也会存在一些噪声,使得”支持向量点“到最优分类超平面非常小。
为了解决这些问题,软间隔SVM允许一些数据点不满足约束项
2.利用核技巧将低维的训练数据升至高维,在高维空间进行线性SVM分类。
也是为了解决数据线性不可分问题
避开了在高维空间计算的复杂过程,取而代之的是直接在低维空间用核函数代替它,简化了计算过程,其本质是用低维空间中的更复杂的运算代替高维空间中的普通内积
解决方式:将输入数据本身从低维空间升到高维空间。毕竟低维线性不可分的数据到了高维线性可分的概率就大多了嘛,而且理论上如果升到足够高维是绝对线性可分的。
4、与逻辑回归在求解目标的区别:
(1)SVM:
让支持向量点远离分类超平面。
是在满足所有训练数据点都比支持向量远离分类超平面的前提下(但根本不管这些训练数据点有多远离),如何使得两个支持向量距离分类超平面的距离最远。
(2)逻辑回归:
让所有训练样本点远离分类超平面
如何使得所有的训练数据距离分类超平面的距离综合最远,考虑所有训练数据点的远离。
决策树
1、是一种基于if-then-else规则的有监督学习算法
一般是自上而下生成的。每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分枝画成图形很像一棵树的枝干
利用了概率论的原理,并且利用一种树形图作为分析工具,其基本原理是用决策点代表决策问题,用方案分枝代表可供选择的方案,用概率分枝代表方案可能出现的各种结果,经过对各种方案在各种结果条件下损益值的比较为决策者提供决策依据
2、
(1)绘制树形图:
决策树不像自然界的树那样从下向上生长和展开,而是从左向右展开,组成一个树状网络图。决策树需要根据已知条件排列出各个方案和每一方案的各种自然状态
(2)计算期望值:
各状态结点的收益值。将各分枝的收益值(或损失值)分别乘以各概率枝上的概率,最后将这些值相加,得出状态结点的期望值(或损失值)
(3)修枝:
根据不同方案期望值(或损失值)的大小进行方案优选。若以最大期望值为准则,则逐级淘汰较小期望值,生成一个最终决策点的决策
随机森林
1、 是一种由决策树构成的集成算法, 是由很多决策树构成的,不同决策树之间没有关联。
(1)
特点:
能够处理具有高维特征的输入样本,而且不需要降维
不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)
能够评估各个特征在分类问题上的重要性,可以判断特征的重要程度和不同特征之间的相互影响
在生成过程中,能够获取到内部生成误差的一种无偏估计(OOB)
训练速度比较快,容易做成并行方法
对于不平衡的数据集来说,它可以平衡误差。
如果有很大一部分的特征遗失,仍可以维持准确度
缺点:
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合
对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
(2)思想:
将一个输入样本进行分类,就需要将它输入到每棵树中进行分类。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
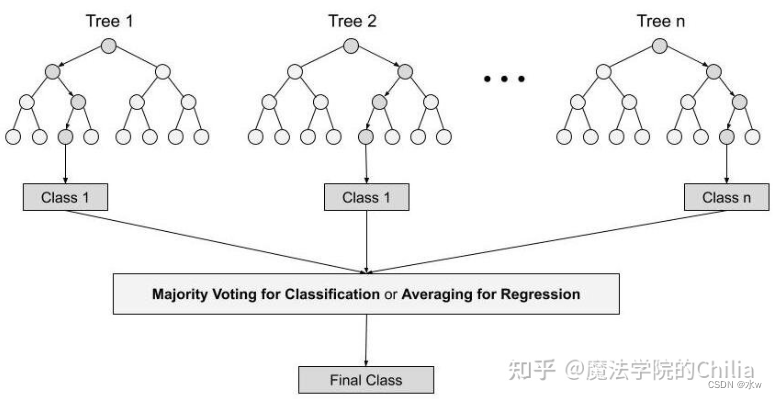
(3)每棵树的按照如下规则生成:
(1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(就是bootstrap sample方法, 拔靴法采样)作为该树的训练集;从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本。
(2)如果存在M个特征,则在每个节点分裂的时候,从M中随机选择m个特征维度(m << M),使用这些m个特征维度中最佳特征(最大化信息增益)来分割节点。在森林生长期间,m的值保持不变。
(4)分类效果(错误率)与两个因素有关:
森林中任意两棵树的相关性:相关性越大,错误率越大;(弱分类器应该good且different)
森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。(弱分类器应该good且different)
(4)构造步骤:
- 随机抽样,训练决策树
- 随机选取属性,做节点分裂属性,重复,直到不能分裂
- 建立大量决策树,形成森林
(5)应用:
- 对离散值的分类
- 对连续值的回归
- 无监督学习聚类
- 异常点检测