支持向量机(SVM)和逻辑回归(LR)
一、相同点
1、都是常用的分类算法。
2、如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
3、LR和SVM都是监督学习算法。
4、LR和SVM都是判别模型
判别模型会生成一个表示P(Y|X)的判别函数(或预测模型),而生成模型先计算联合概率p(Y,X)然后通过贝叶斯公式转化为条件概率。简单来说,在计算判别模型时,不会计算联合概率,而在计算生成模型时,必须先计算联合概率。或者这样理解:生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。常见的判别模型有:KNN、SVM、LR,常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。
5、LR和SVM在学术界和工业界都广为人知并且应用广泛
二、不同点
1、首先他们的损失函数不一样,这算本质上区别
不同的loss function代表了不同的假设前提,也就代表了不同的分类原理,也就代表了一切!!!简单来说,逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值,具体细节参考
逻辑回归相关文档。支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面,具体细节参考SVM支持向量机的相关文档
2、支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局(远离的点对边界线的确定也起作用)。
当你读完上面两个网址的内容,深入了解了LR和SVM的原理过后,会发现影响SVM决策面的样本点只有少数的结构支持向量,当在支持向量外添加或减少任何样本点对分类决策面没有任何影响;而在LR中,每个样本点都会影响决策面的结果。
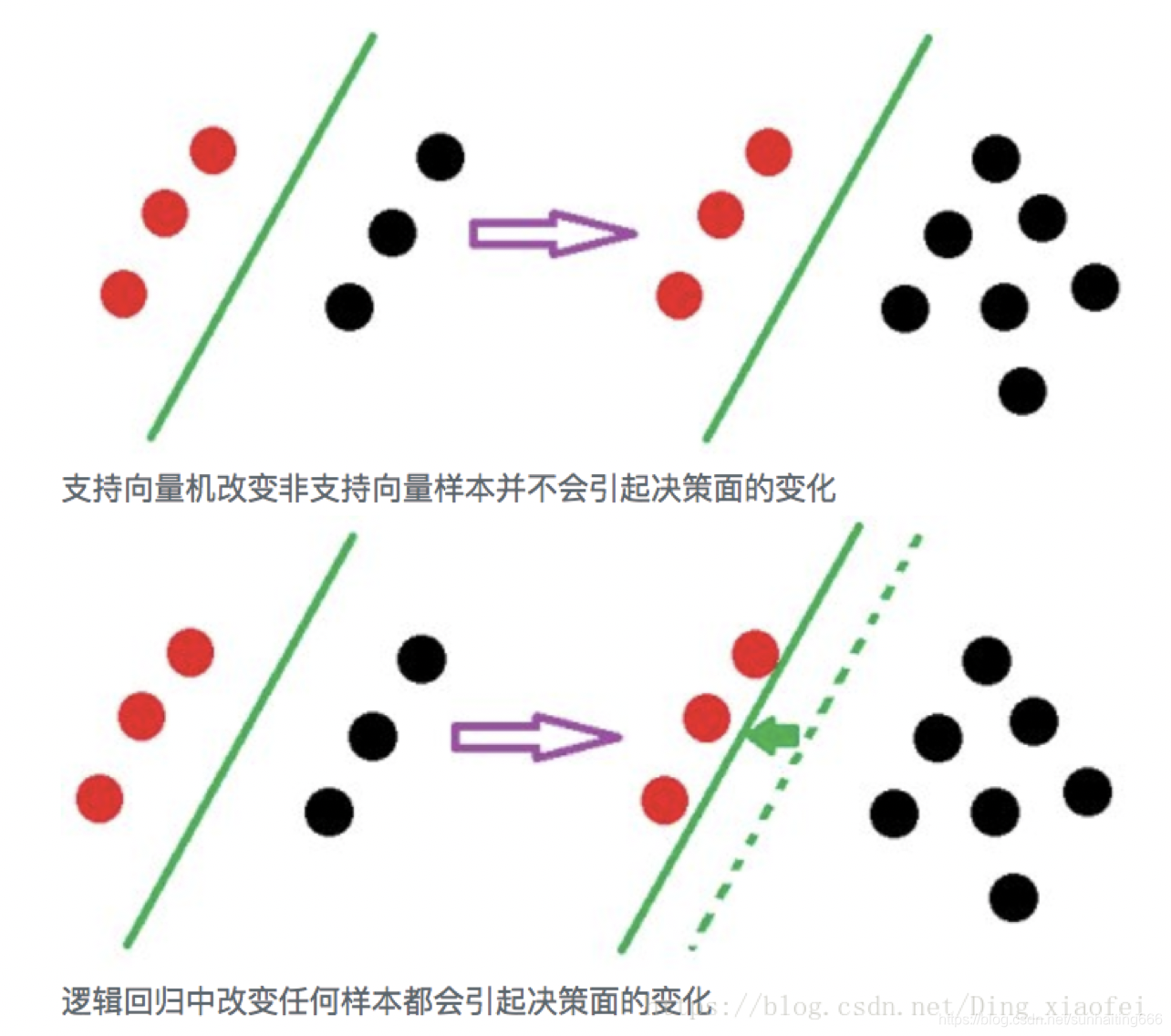
因为上面的原因,得知:线性SVM不直接依赖于数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
3、在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法。
这个问题理解起来非常简单。分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。通过上面的第二点不同点可以了解,在计算决策面时,SVM算法里只有少数几个代表支持向量的样本参与了计算,也就是只有少数几个样本需要参与核计算(即kernal machine解的系数是稀疏的)。然而,LR算法里,每个样本点都必须参与决策面的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制。
4、线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响。
5、SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!
以前一直不理解为什么SVM叫做结构风险最小化算法,所谓结构风险最小化,意思就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,从而达到真实误差的最小化。未达到结构风险最小化的目的,最常用的方法就是添加正则项,后面的博客我会具体分析各种正则因子的不同,这里就不扯远了。但是,你发现没,SVM的目标函数里居然自带正则项!!!再看一下上面提到过的SVM目标函数
三、LR和SVM分别在什么情况下使用??
同样的线性分类情况下,如果异常点较多的话,无法剔除,首先LR,LR中每个样本都是有贡献的,最大似然后会自动压制异常的贡献,SVM+软间隔对异常还是比较敏感,因为其训练只需要支持向量,有效样本本来就不高,一旦被干扰,预测结果难以预料。
SVM对噪声点比较敏感。
逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础,虽然一般使用的人不太会去关注。还有很重要的一点,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
假设: n = 特征数量,m = 训练样本数量
1)如果n相对于m更大,比如 n = 10,000,m = 1,000,则使用lr理由:特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型;
2)如果n较小,m比较大,比如n = 10,m = 10,000,则使用SVM(高斯核函数)理由:在训练样本数量足够大而特征数较小的情况下,可以通过使用复杂核函数的SVM来获得更好的预测性能,而且因为训练样本数量并没有达到百万级,使用复杂核函数的SVM也不会导致运算过慢;
3)如果n较小,m非常大,比如n = 100, m = 500,000,则应该引入/创造更多的特征,然后使用lr或者线性核函数的SVM。
理由:因为训练样本数量特别大,使用复杂核函数的SVM会导致运算很慢,因此应该考虑通过引入更多特征,然后使用线性核函数的SVM或者lr来构建预测性更好的模型。
