来源:iros2021
0、摘要
将点云投影到 2D 球面距离图像上,将 LiDAR 语义分割转换为距离图像上的 2D 分割任务。然而,LiDAR 距离图像仍然与常规的 2D RGB 图像有天然的不同;例如,距离图像上的每个位置都编码唯一的几何信息。在本文中,我们提出了一种新的基于投影的激光雷达语义分割管道,它由新颖的网络结构和高效的后处理步骤组成。在我们的网络结构中,我们设计了一个 FID(全插值解码)模块,该模块使用双线性插值直接对多分辨率特征图进行上采样。受到 PointNet++ 中使用的 3D 距离插值的启发,我们认为这个 FID 模块是 (θ,φ) 空间上的 2D 版本距离插值。作为无参数解码模块,FID 在保持良好性能的同时极大地降低了模型复杂度。除了网络结构之外,我们凭经验发现我们的模型预测在不同语义类别之间具有清晰的界限。这让我们重新思考广泛使用的 K 最近邻后处理对于我们的管道是否仍然是必要的。然后,我们意识到多对一映射会导致一些点映射到同一像素并共享相同标签的模糊效果。因此,我们建议通过为这些遮挡点分配最近的预测标签来处理它们。这种 NLA(最近标签分配)后处理步骤在消融研究中表现出比 KNN 更好的性能,推理速度更快。在 SemanticKITTI 数据集上,我们的流程在 64 × 2048 分辨率和所有逐点解决方案的所有基于投影的方法中实现了最佳性能。以 ResNet-34 作为主干,模型的训练和测试都可以在具有 11G 内存的单个 RTX 2080 Ti 上完成。
I. INTRODUCTION
激光雷达传感器在户外机器人,尤其是自动驾驶汽车中发挥着重要作用。随着深度学习技术的蓬勃发展,最近的研究主题集中在从点云中提取对象和语义信息。 LiDAR语义分割是一个神经网络预测每个点的语义标签的任务[1]。如图 1 所示,解决此任务可以构建对附近环境的 3D 理解。

尽管第一个专门针对 LiDAR 语义分割基准测试的数据集于 2019 年发布[2],但两个社区更早地就对使用神经网络处理 3D 点云产生了兴趣。计算机视觉学会的研究人员研究了如何设计排列不变网络来处理更一般的无序点云 [3]、[4]。相比之下,机器人方面的研究人员的解决方案设计更多地考虑了LiDAR传感机制,通过将点云投影到2D球形范围图像上[5]。基于投影的解决方案允许精心设计的2D图像语义分割模型直接用于LiDAR语义分割任务。它缺乏处理更通用的无序点云的能力,但它显示出实际的优势,例如在速度和精度方面都有更好的性能[6],[7]。为了追求更好的性能,最近的研究人员通过将多视图投影或体素化与逐点特征相结合来进一步设计模型[8]、[9]、[10]。
Motivation
本文的主要目标是讨论我们应该如何设计基于投影的激光雷达分割网络。我们希望保持结构尽可能通用并保持良好的性能。大多数基于图像的网络结构都依赖于编码器-解码器结构。本文通过考虑球面表示图像与常规图像之间的差异,重新思考了这种结构。在球面表示图像上,每个位置都是一个具有唯一位置信息的 3D 点。然而,在常规图像上,两个不同的像素可能具有相同的光谱信息,这使得仅像素图案有意义。为了设计更好的距离图像结构,我们提出了几个模块,包括具有 1×1 卷积的输入模块、提取多尺度特征的主干网络、完全插值解码模块以及仅分配那些被遮挡点的标签。
Contribution
本文提出了一种新的流程来以投影方式解决 LiDAR 语义分割问题。整个解决方案干净有效。训练和测试都可以在具有 11 G 内存的单个 RTX 2080 Ti 上进行。该解决方案的性能优于所有基于投影的方法,遵循相同的 64×2048 输入分辨率。我们认为有两项主要技术贡献将对其他相关方法有所帮助:
• 我们提出了一种无参数全插值解码模块,仅包含双线性插值操作。大多数现有的解码器结构需要转置卷积或带有插值的特殊组合卷积来对低分辨率特征图进行上采样。我们证明,仅使用双线性插值就可以实现最先进的性能。此设置通过避免其他模型 [11]、[7] 使用的解码器中的大量参数来降低模型复杂性。
• 我们用更高效、更直观的步骤取代了广泛使用的K 最近邻后处理。最近邻算法的提出是为了解决由两个原因产生的边界模糊效应[1],即CNN的模糊输出和球面距离图像上的多对一映射。然而,根据经验,我们发现模糊对我们预测的影响可以忽略不计。然后,我们特别关注多对一映射,即某些点将与其他点映射到同一位置,因此没有直接从网络预测标签。为了解决这个问题,我们将 3D 空间中最近点的预测标签分配给那些未预测的点。与 KNN 相比,这种 NLA(最近标签分配)后处理步骤具有更好的性能和更快的推理速度。
上述两个贡献都为基于投影的激光雷达语义分割任务的网络设计带来了实际的改进,据我们所知,其他文献尚未对此进行讨论。还有一些其他的小贡献,例如具有 1×1 卷积的输入模块或具有空洞卷积的附近点特征聚合[12]。由于最近的论文[13]中已经探讨了类似的想法,我们将在方法部分介绍它们,但不会声称它们是本文的主要贡献。
II. RELATED WORK
A. Point-based Networks
PointNets PointNet [3] 总结了一般点云的几个关键属性,包括无序、变换下的不变性以及点之间的交互。这些独特的挑战促使他们设计基于 MLP(多层感知器)的网络结构以及由全局和逐点特征连接的每点特征向量。除了全局特征和逐点特征的串联之外,PointNet++ [4] 还提出了新颖的集合学习层来自适应地组合来自多个尺度的特征。然而,本地查询和分组限制了大型点云上的模型性能。这吸引了一些连续的论文[14]、[6],最好的纯基于点的解决方案在LiDAR点云语义分割上仍然落后[6]。
PointConvs 除了网络结构设计之外,利用特殊的卷积核解决点云分割也是一个热门话题。一些想法,例如PointCNN [15]和KPConv [16],已经在各种数据集上进行了尝试,并显示出很强的通用性。其中一些特殊的卷积核已被合并为其他解决方案的一部分[17]。
B. Voxel-based Networks
将 3D 世界分割为离散体素是处理点云的一个简单想法。体素化后,常规 3D 卷积可以在 3D 空间上使用,就像 2D 卷积在 2D 图像上使用一样 [18]、[19]。然而,这些方法在室外激光雷达点云中的改进仍然有限。最近的一些论文正在尝试考虑一种更好的 3D 体素化方法,通过结合 LiDAR 传感器生成点云的方式来切割 3D 空间 [20]。
C. Projection-based Network
Single-View projection
2D 卷积神经网络在图像上的成功提出了一个问题:为了使用成熟的现有模型,是否可以将 3D 点云投影到 2D 空间上。 LiDAR 传感器的扫描机制建议采用球形距离投影 [1]。最近许多论文从不同方面探讨了这个想法[7]、[21]、[13]。除了范围视图之外,最近的论文还考虑了鸟瞰视图[9]。所有这些单视图投影方法都具有使用 2D 卷积网络的优点,例如可控的推理速度。
Multi-View projection
有了上述所有新开发的方法,很自然地开始思考如何将不同想法的一部分结合在一起。在最近的多视图投影解决方案[22]、[23]中,首先使用基于MLP的特征提取器,然后将来自不同视图的特征张量融合在一起以由一个解码器处理。然而,这些方法需要花费额外的成本来准备多视图投影,并且还不清楚与单视图投影相比有多少改进。
D. Practical Considerations
作为一个新的重要挑战,如何设计模型来解决激光雷达语义分割仍然是一个悬而未决的问题。解决方案既要考虑数值指标,又要考虑实际可行性。单视图投影方法能够直接使用2D卷积神经网络,因此不需要担心可行性,因为有很多技术可以针对各种应用需求来优化2D网络[24]、[25]。本文专门致力于为具有更好性能的球面范围单视图投影解决方案提供管道。
III. METHOD
范围视图投影方法将每个点从 (x,y, z) 笛卡尔坐标映射到 (r,θ,φ) 球坐标。对 2D (θ,φ) 空间进行离散化后,每个点将在 (θ,φ) 图像上有一个映射位置。与常规图像上的 RGB 三个通道相同,LiDAR 点云距离图像具有五个通道(x、y、z、r、反射)。
A. Input and Backbone Modules
尽管输入就像具有五个通道的 2D 图像,但每个位置仍然代表一个点的信息。因此,我们使用两个 1×1 卷积层处理输入,将每个点映射到高维张量。该输入处理模块类似于PointNet [3],它使用MLP(多层感知器)提取点特征。然后,我们将由逐点特征组成的高维张量输入到常规主干网络中。主干网络可以是任何结构,例如更快的 MobileNet [26] 或更准确的 HRNet [27]。所有这些 CNN 结构都采用张量并生成多分辨率特征图。在本文中,我们使用标准 ResNet-34 [28] 作为主干。
问题是,为什么为图像设计的常规骨干网络仍然可以在逐点特征张量上工作?我们认为,当激光扫描仪逐行发射激光束时,LiDAR 点云在球坐标中是有序的。这种机制使得构建 LiDAR 点云的特殊 2D 球面范围表示成为可能。现代骨干网络中常规的 3 × 3 卷积算子相当于 2D (θ,φ) 空间上的八个最近查询和分组。因此,使用为图像设计的主干网络来处理逐点特征,就是PointNet++[4]中使用的无序点云的3D最接近查询和分组的2D对应。
B. Fully Interpolation Decoding

在图 2 所示的网络结构中,我们使用 1×1 卷积将每个点向量映射到高维张量,然后使用主干网络提取多尺度点特征,该主干网络不断处理 2D 上的附近点特征 (θ,φ ) 空间。下一个问题是,如何以逐点的方式将这些信息融合在一起。在PointNet [3]中,每点特征向量与全局特征向量连接作为每个点的最终特征向量。在 PointNet++ [4] 中,基于距离的插值用于将点的子集上采样为更大的集合。这两个独特的操作启发我们设计一个类似的模块,旨在融合多尺度信息。
PointNet++[4]中定义的距离插值为:
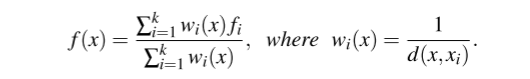
然而,在 2D (θ,φ) 空间上,如果我们设置最近点的数量 k = 4 并将距离函数 d(x,xi) 定义为 l1 距离,则距离插值将完全退化为双线性上采样。使用双线性上采样对低分辨率特征图进行插值,为我们提供了五个具有相同分辨率但编码不同级别信息的逐点特征张量。与 PointNet [3] 相同,我们将所有这些特征张量连接在一起。然后,经过图2中的网络结构后,每个点都从(x,y,z,r,remission)映射到具有多级信息的高维向量。
我们将此模块命名为 FID(全插值解码)。与其他网络中使用的常规解码器相比,FID 完全无参数,大大降低了模型复杂性和内存成本。这一优势也给网络结构设计带来了好处。例如,只能专注于定制骨干网以满足硬件限制的要求。
C. Classification Head
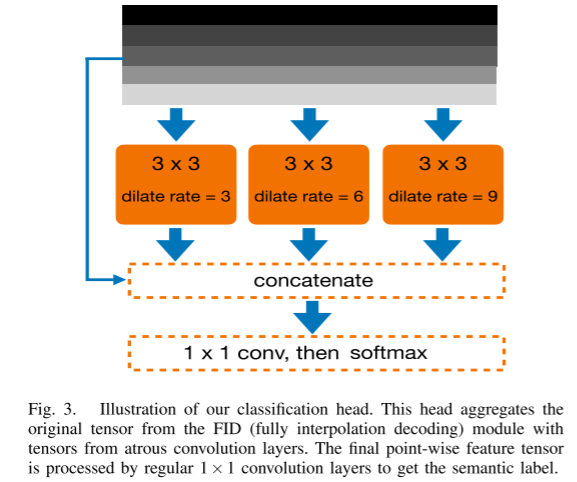
经过FID(全插值解码)模块后,我们得到每点特征张量。为了帮助每个点向量更好地融合附近的信息,我们进一步使用空洞卷积来提取局部特征,并通过与原始特征张量的简单串联来聚合它们。该操作类似于ASPP(atrous Spatial Pyramid Pooling)[29],不同之处在于我们不应用平均池化,而是将输出与原始特征张量连接在一起。最终的特征张量被发送到 1×1 分类层以预测每个点的语义标签。该分类头如图3所示。
D. Post-processing with Nearest Label Assignment
几乎所有最近开发的基于投影的LiDAR语义分割解决方案都采用KNN(K最近邻)后处理模块来减轻边界模糊效应。正如最近的一篇论文 [1] 中所述,造成这种效果的原因有两个:神经网络的输出模糊和距离图像上的多对一映射。然而,在可视化一些网络输出后,我们意识到 FID(全插值解码)模块已经能够给出具有清晰对象边界的预测。在图 4 中,我们展示了我们的观察结果。在顶部,我们通过仅显示网络处理的那些点来可视化两个示例。我们可以看到,即使对于小杆,也几乎没有模糊效果。在图 4 的底部,可以清楚地看到添加这些遮挡点会产生模糊的边界。这促使我们重新思考是否仍有必要在我们的流程中保留 KNN 后处理步骤。
这里我们首先对多合映射问题进行更多讨论。从(x,y,z)笛卡尔坐标到(r,θ,φ)球坐标的映射是一对一的连续映射。然而,在 2D (θ,φ) 图像上离散化 (r,θ,φ) 会将一些接近的点分组到一个单元中。投影后,神经网络只会处理细胞某一点的信息。请注意,映射在同一单元上的那些点仅在 2D (θ,φ) 空间上接近,并且它们可能与处理后的点有很大的距离。潜在的大距离表明那些被遮挡的点可能与预测点具有不同的标签。

根据图 4 中的现象,我们认为多对一映射是我们流程中的主要问题。从上面的讨论中,我们知道映射在同一单元上的那些点可能彼此距离很大,因此不共享相同的标签。这意味着一个简单的解决方案,我们可以直接将 3D 空间中最近点的标签分配给那些被遮挡的点。与 KNN 类似,我们在 Alg 中设计了 NLA(最近标签分配)。 1,在范围图像上查找启用 GPU 的本地补丁中的最近点。

与 KNN 相比,我们的 NLA 后处理步骤不需要高斯加权和范围截止,因此是一个不太复杂的解决方案。在消融研究中,我们表明我们最近的标签分配后处理步骤具有比 KNN 更好的 mIoU 和更快的推理速度。
E. Other Training Settings
对于数据增强,我们遵循其他论文沿 y 轴进行旋转和翻转[23]、[7]。我们将批量大小设置为 2,并采用具有单周期学习率策略的 Adam 优化器。最大学习率设置为0.002,总训练周期设置为30。对于损失函数,我们将加权交叉熵损失[38]和Lov´asz-Softmax损失[39]结合在一起。得益于无参数 FID(全插值解码)模块,我们所有的实验都是在单个 RTX 2080 Ti 上进行的,并在 PyTorch 中选择了混合精度。
IV. EXPERIMENT
A. Dataset
SemanticKITTI 数据集 [2] 是最近的一个大型数据集,为整个 KITTI Odometry Benchmark [40] 提供密集的逐点注释。该数据集总共由 22 个序列组成。在本文中,我们严格按照官方的分割在序列00到07以及序列09、10上训练模型。序列08用作验证集来帮助我们选择最佳检查点。我们提交对序列 11 到 21 的预测,并报告排行榜的结果以与其他人进行比较。
B. Performance Comparison
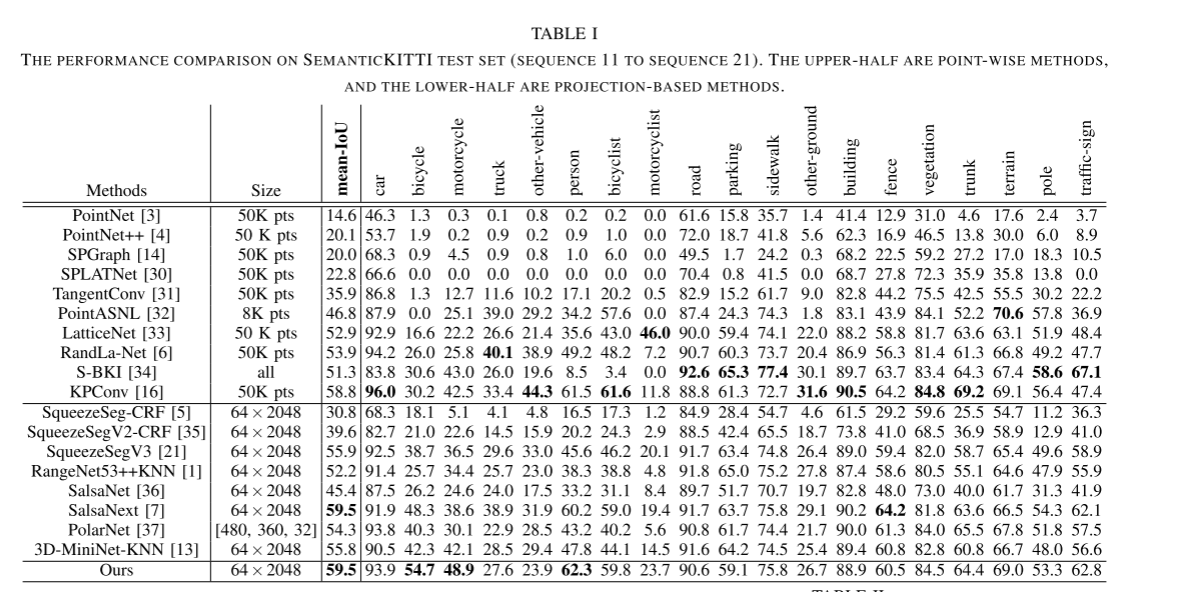
我们将我们的模型性能与表一中的其他方法进行比较。当我们通过考虑点属性来设计处理投影距离图像的结构时,我们主要将我们的方法与逐点解决方案以及基于投影的解决方案进行比较。通过遵循相同的设置,我们的管道大幅优于所有逐点解决方案,并与基于最佳投影的解决方案实现了相似的性能。
C. Ablation Study
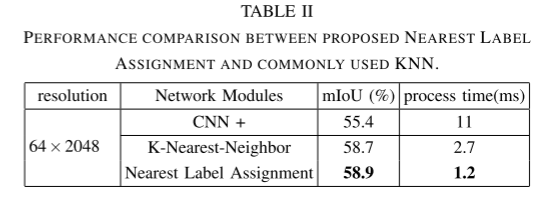
在本文中,我们凭经验发现我们的网络预测没有很强的边缘模糊效果。边界模糊主要是由多对一映射问题引起的。为了解决这个问题,我们设计了一种新的后处理算法,只需将 3D 空间中最近点的标签分配给这些点,而无需神经网络的预测。在表II中,我们可以看到这种NLA(最近标签分配)后处理算法比常用的KNN具有更好的性能和更快的推理速度。实验在SemanticKITTI的验证集上进行。这里使用的硬件是Nvidia RTX 2080 TI。值得一提的是,CNN 结构处理一个样本只需要 11ms。尽管我们在训练过程中使用了 PyTorch 提供的混合精度选择,但这种推理速度仍然非常出色。我们将这一优势归功于无参数 FID 模块。
V. CONCLUSION
在本文中,我们讨论如何设计基于投影的激光雷达点云分割的神经网络解决方案。我们提出了一个带有输入模块、常规主干、用于上采样的 FID 模块、分类头和名为 NLA 的后处理步骤的管道。在每个模块中,我们首先尝试选择最常见的网络设置,然后讨论为什么所选设置有效。
我们的管道在基准测试中实现了良好的性能,并保持了简单的结构,我们相信这对于 GPU 和板载处理器来说都是硬件友好的。我们发布了代码,以使进一步的开发变得更加容易。
自己总结:
1、经常和CEnet一起对比
2、双线性插值
3、后处理 NLA(最近标签分配)
4、性能和SalsaNext持平,CEnet效果会更好一点。