文章目录
2020CVPR
牛津大学
本文提出了针对大场景语义分割的一种方法,主要提出了使用random sampling来进行降采样从而降低运算时间,通过提出的Local Feature Aggregation Module来确保局部特征能够被提取出来,减小random sampling的不利影响。
RandLA-Net
Motivation
本文主要是对大场景,但其实应该是针对点云中包含很多点,例如50k个点这样,因为大场景无非是一个尺度问题,但点云的规模则直接关系到计算的速度和存储空间消耗。以下我们就对包含点很多的点云称为大点云。(自己瞎起个名字)
首先作者提出了目前制约对大点云的实时语义分割的因素有以下三点:
1)目前Point-sampling的方法要么费时,要么费内存,对于大点云来说,都是不可接受的。
2)大多数的方法是使用kernelisation or graph construction的方法提取局部特征。但我本人认为这个说法不太成立,因为作者在之前也说了对局部特征提取特征的方法除了上述两种还有neighbouring feature pooling ,也就是Pointnet++类型和attention-based aggregation。而我认为本文就是用了graph construction和attention-based aggregation这两种方法。
3)对于通常由数百个目标组成的大规模点云,现有的局部特征学习者要么无法捕获复杂的结构,要么由于其感受野的大小有限而效率低下。这个其实我也不太理解,我只能说,本文提出的Local Feature Aggregation Module在结果上来看确实很优秀,但说目前的方法具备上述两者缺陷其一,我不太赞同。
Sampling
作者对比了其他几种sampling的方法,包括:FPS,IDIS,GS,CRS,PGS。这里我就不详细说明这几种采样方法的具体操作方式了,作者在原文中已经写得很清楚了。但其实,常用的也就是FPS。
那么想比于上述方法,Random Sampling具有很好的实时性,作者也对此进行了验证。其他方法,要么速度慢,要么占内存,通过学习的方法则对于大点云不收敛,反正各有各的问题。那么具体的对比如下图:

但Random Sampling的问题在于,本身大量的点就集中在离LiDAR近的区域,远处的区域稀疏。通过sampling,由于是random的,比例是一样的,那么远处的就更稀疏了,没准那次就丢掉了边缘的点。而FPS则是能够最好的覆盖整个区域,所以相比random sampling,FPS确实更适合语义分割这个问题。但本文追求的是快啊,那么如何才能弥补RS这个缺点呢?那就是增大每个点的感受野,使得在sampling过后,保留下来的点有足够大的感受野,能够包含丢掉的点的信息,即使是在远处点很稀疏的情况下。
Local Feature Aggregation
这就是为了能够弥补RS所提出来的局部特征提取的方法
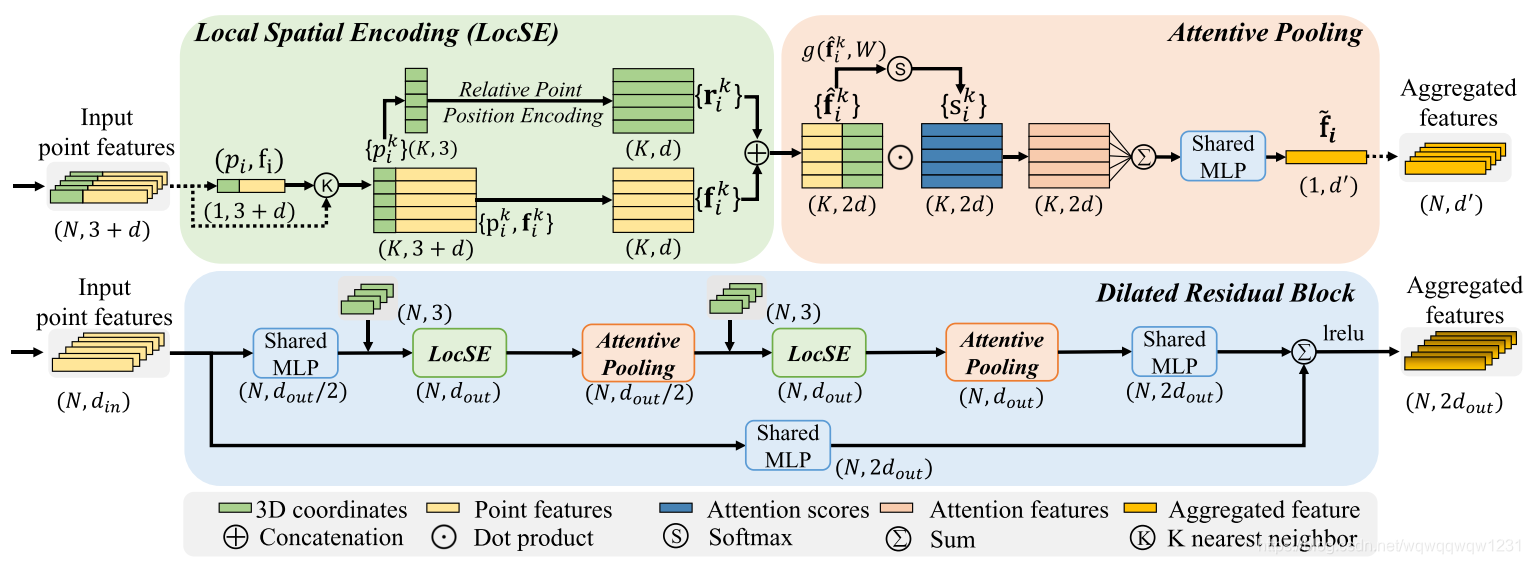
LocSE
对于某个点 p i p_i pi,找其k个临近点,使用MLP提取特征,具体的由下公式表述:

其中 p i k p_i^k pik是k个临近点的中的某个点。但看这种构造方式,不就根据kNN的方式构造了一个graph吗?通过graph提取特征。
Attentive Pooling
然后使用得到的特征,计算一个weight,然后weight加权得到 p i p_i pi的新特征。


Dilated Residual Block
把LocSE+Attentive Pooling合起来看做为提取 p i p_i pi特征的方法,用此方法进行两次,就可以将 p i p_i pi的感受野从K扩展到 K 2 K^2 K2。这个的具体的操作在上图中有具体展现。
Experiments
1、首先实验先验证了RS的速度确实高,这个的结果我已经在讲RS那一块放过了。
2、在Semantic3D和SemanticKITTI上做到了SOTA的效果
3、Ablation Studies
从(1)中可以看到,去掉LocSE,也就是单纯使用Attention的方式并不是很有效。
从(2)-(4)可以看出Attention的效果也是有的,比单纯的pooling好
从(5)可以看出扩展感受野的必要性

我的思考
我看的语义分割这方面的论文不多,目前大多针对点云处理的backbone的方法都会做语义分割的实验,基本都是使用FPS。所以本文使用RS能做到SOTA的效果证明,只要特征能提取的有效,则FPS不是必须的。
Dilated Residual Block其实和PointNet++中的SA相比有以下不同:
1)LocSE中使用的kNN,这也就保证了稀疏的地方仍然能够找到临近点提取特征,而SA中用的是一定半径内的球形邻域,这就在稀疏的地方就不是很好使了。
2)在Ablation Studies证明了的Attention操作是优于pooling的,这个操作将临近点之间的特征联系起来,而不是单单max pooling了。
3)Dilated Residual Block的串联结构有效的增大了感受野,SA中并联的MSG结构则提取multi-scale的特征。
我认为可以试一下做一下将RS改为FPS的实验,看看最终效果涨不涨,来证明FPS是否确实是在效果上可以被RS替代。