What:什么是GO和KEGG?
GO全称是Gene Ontology,它分为:细胞组分(cellular component, CC)、分子功能(molecular function, MF)、生物过程(biological process, BP),那这三者有什么关系呢?,大概就是母鸡A被养在鸡笼里,它能够下鸡蛋,但是前提是我往笼子里再放一只公鸡后才能下蛋,在这个比喻里,鸡笼就是CC,下蛋这个动作是BP,而放进公鸡就是这个过程的催化作用,所以是MF。用科研专业术语来说,CC描述的像是位置,比如定位在细胞核;BP是一种生物学过程,比如细胞粘附;MF是一种功能或者职能,比如我们熟悉的酶。
那KEGG又是什么呢?在上面的故事里,有了公鸡母鸡,那还差小鸡,我们把基因看成小鸡,一群小鸡找自己的兄弟姐妹认亲最后回到特定母鸡身边,这个过程就是KEGG,也就是我们常说的找通路。这个通路不一定准确,但是帮助理解应该没问题。
Why:为什么要做GO和KEGG?
如果你手上拿到一个基因list,里面有500个基因,你要怎么确定哪些基因可能跟你要研究的通路或者表型有关呢?你要怎么知道这些基因哪些可以认为是一伙的呢?你要怎么透过这乱花渐欲迷人眼的现象,去找寻这些基因背后的规律呢?
引用:公众号:解螺旋
library(clusterProfiler)
library(AnnotationHub)
#AnnotationHub可以看作是生物数据的中转站,方面我们搜索目标数据,另一个相似包是biomaRt
library(AnnotationDbi)
library(ggplot2)
#BiocManager::install("org.Hs.eg.db", version = "3.8")
#具体物种对应的R包名字看这页:<http://bioconductor.org/packages/release/BiocViews.html#___OrgDb>
library(org.Hs.eg.db)
#查看有哪些ID
keytypes(org.Hs.eg.db) #人类
[1] "ACCNUM" "ALIAS" "ENSEMBL" "ENSEMBLPROT"
[5] "ENSEMBLTRANS" "ENTREZID" "ENZYME" "EVIDENCE"
[9] "EVIDENCEALL" "GENENAME" "GO" "GOALL"
[13] "IPI" "MAP" "OMIM" "ONTOLOGY"
[17] "ONTOLOGYALL" "PATH" "PFAM" "PMID"
[21] "PROSITE" "REFSEQ" "SYMBOL" "UCSCKG"
[25] "UNIGENE" "UNIPROT"
导入数据·
setwd('D:\\GEO数据挖掘与meta分析\\练习\\18.GO富集(代码)\\18.GO富集(代码)')
deg <- read.csv("deg_down_symbol.csv", as.is = T)
dim(deg)
[1] 271 8
#ID转换
deg.id <- bitr(deg$SYMBOL, #基因名
fromType = "SYMBOL", #从gene symbol
toType = "ENTREZID", #提取ENTREZ ID
OrgDb = "org.Hs.eg.db") #相应物种的包
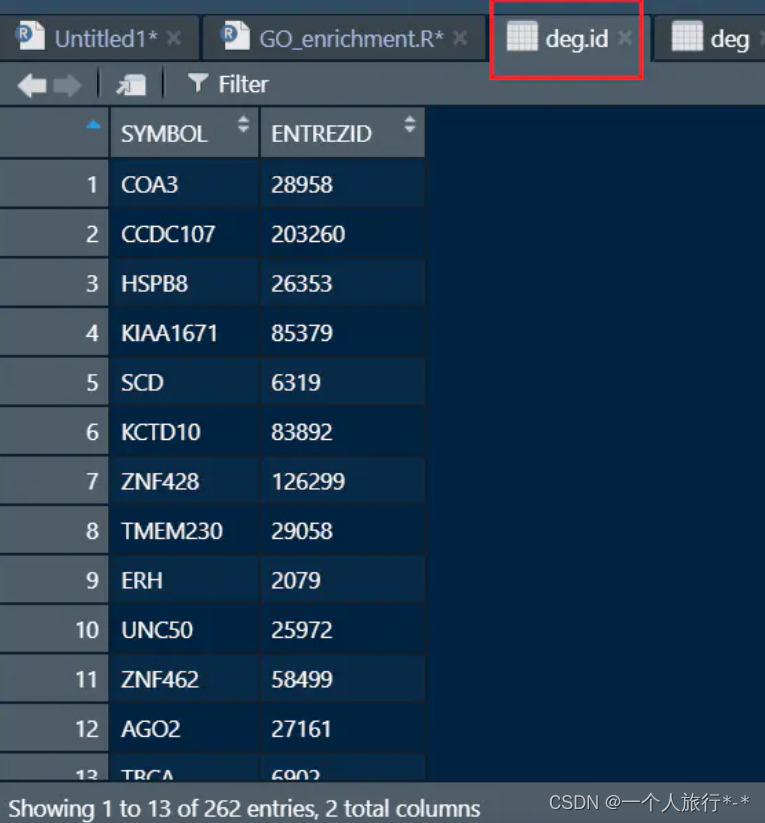
head(deg.id)
SYMBOL ENTREZID
1 COA3 28958
2 CCDC107 203260
3 HSPB8 26353
4 KIAA1671 85379
5 SCD 6319
6 KCTD10 83892
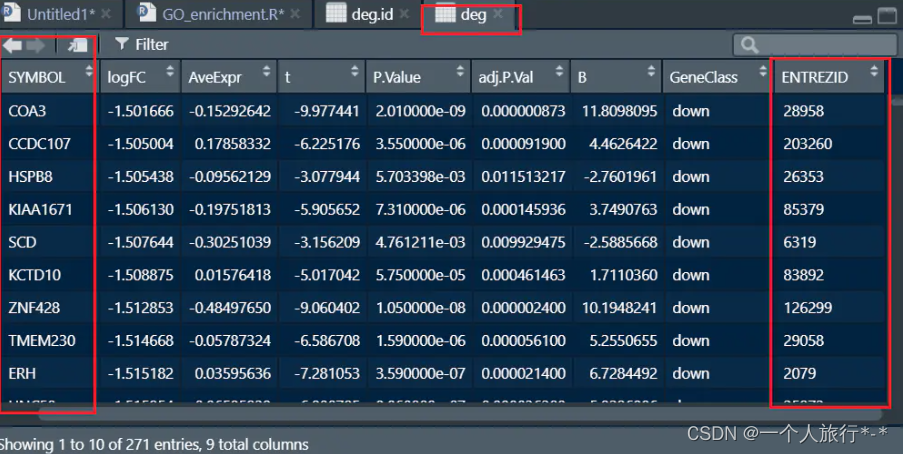
合并基因名、ENTREZID
idvec <- deg.id$ENTREZID
names(idvec) <- deg.id$SYMBOL
deg$ENTREZID <- idvec[deg$SYMBOL]
head(deg)
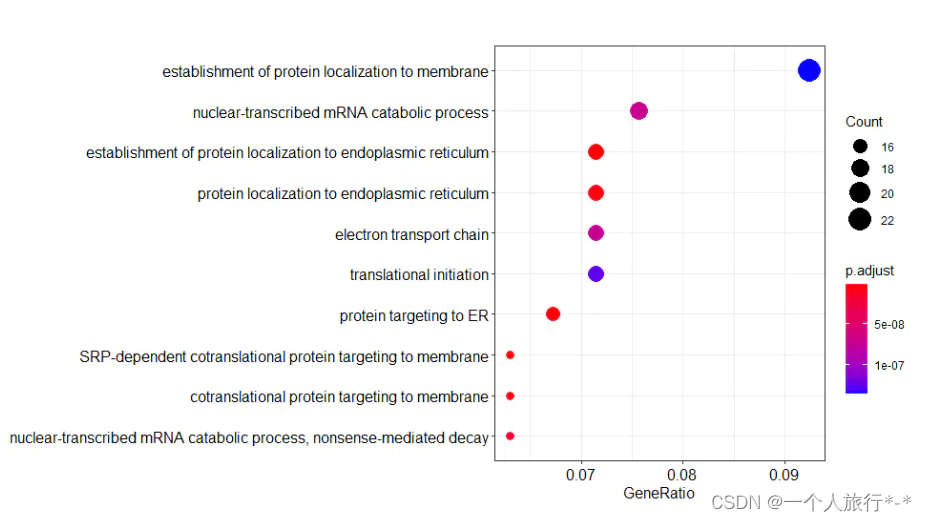
GO BP 富集
ego_BP <- enrichGO(gene = deg.id$ENTREZID,
#人类用这行
OrgDb = org.Hs.eg.db,
#非模式生物用这行,例如玉米
#OrgDb = maize.db,
ont = "BP", #或MF或CC
pAdjustMethod = "BH",
pvalueCutoff = 0.05
#qvalueCutoff = 0.01
)
dim(ego_BP)
61 9

#富集的GO term有些是相似的,可以用语义学方法,合并相似的GO term。需要较长时间。
#参考资料:<https://guangchuangyu.github.io/2015/10/use-simplify-to-remove-redundancy-of-enriched-go-terms/>
ego_BP_1 <- simplify(ego_BP, cutoff = 0.7, by = "p.adjust", select_fun = min)
dim(ego_BP_1)
30 9
GO CC 富集
ego_CC <- enrichGO(gene = deg.id$ENTREZID,
OrgDb = org.Hs.eg.db,
ont = "CC",
pAdjustMethod = "BH",
pvalueCutoff = 0.05)
dim(ego_CC)
36 9
#把富集分析结果保存到文件
write.csv(ego_CC,"enrichGO_CC.csv",quote = F)
## barplot画图
barplot(ego_CC)
dotplot(ego_CC,showCategory=10)
dev.off()


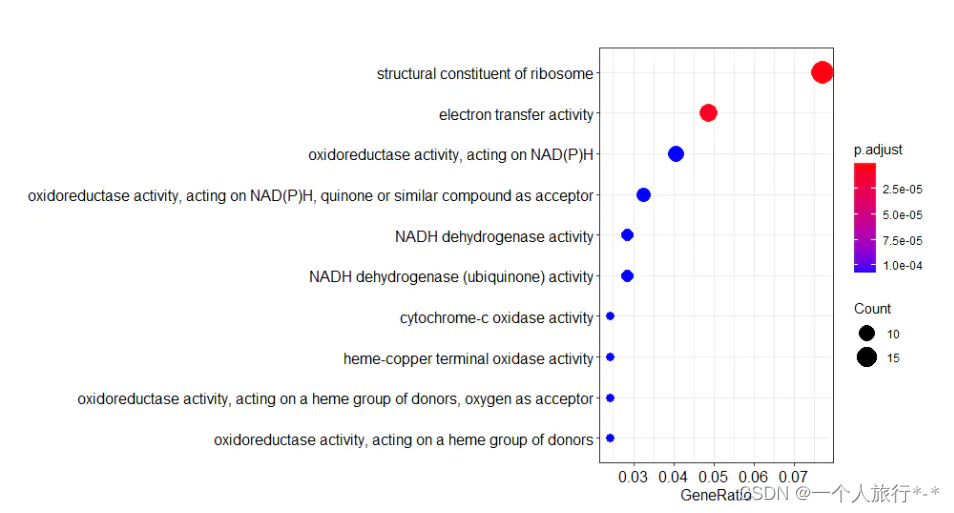
GO MF 富集
ego_MF <- enrichGO(gene = deg.id$ENTREZID,
OrgDb = org.Hs.eg.db,
ont = "MF",
pAdjustMethod = "BH",
pvalueCutoff = 0.05)
dim(ego_MF)
[1] 19 9
#把富集分析结果保存到文件
write.csv(ego_MF,"enrichGO_MF.csv",quote = F)
barplot(ego_MF)
dotplot(ego_MF,showCategory=10)

KEGG分析
library(clusterProfiler)
library(ggplot2)
hsa_kegg<-download_KEGG("hsa")
str(hsa_kegg)
length(unique(hsa_kegg$KEGGPATHID2EXTID$from)) ###信号通路个数
344
length(unique(hsa_kegg$KEGGPATHID2EXTID$to)) ###所有信号通路中的基因数
8108
x<-data.frame(hsa_kegg$KEGGPATHID2EXTID) ###两列为pathwayid,基因id extid 扩增标识符
#一个信号通路含有多个基因,一个基因在多个信号通路
length(unique(hsa_kegg$KEGGPATHID2NAME$from)) ###信号通路对应的名称;
length(unique(hsa_kegg$KEGGPATHID2NAME$to)) ###信号通路对应的名字
y<-data.frame(hsa_kegg$KEGGPATHID2NAME) ###信号通路信息
setwd("D:/GEO数据挖掘与meta分析/练习/19.KEGG富集(代码)/19.KEGG富集(代码)")
deg<- read.csv("deg_all_symbol.csv", as.is = T)
#ID转换
deg.id <- bitr(deg$X, #基因名
fromType = "SYMBOL", #从gene symbol
toType = "ENTREZID", #提取ENTREZ ID
OrgDb = "org.Hs.eg.db") #相应物种的包
#合并基因名、ENTREZID
idvec <- deg.id$ENTREZID
names(idvec) <- deg.id$SYMBOL
deg$ENTREZID <- idvec[deg$X]
#保存到文件
write.csv(deg, "diff_ENTREZID.csv", quote = F, row.names = F)
#deg <- read.csv("diff_ENTREZID.csv", as.is = T)
deg
#KEGG富集
ekk <- enrichKEGG(gene = deg$ENTREZID,
keyType = 'kegg',
organism = 'hsa',
pvalueCutoff = 0.05,
pAdjustMethod = "BH"
#qvalueCutoff = 0.05
)
dim(ekk)
19 9
#把富集分析结果保存到文件
write.csv(ekk,"enrichKEGG_test.csv",quote = F)
#可以用语义学方法,合并相似的KEGG term。需要较长时间。
#参考资料:<https://guangchuangyu.github.io/2015/10/use-simplify-to-remove-redundancy-of-enriched-go-terms/>
#ekk_1 <- simplify(ekk, cutoff = 0.7, by = "p.adjust", select_fun = min)
#dim(ekk_1)
#write.csv(ekk_1,"enrichKEGG_simple.csv",quote = F)
dotplot
dotplot(ekk,showCategory=10)
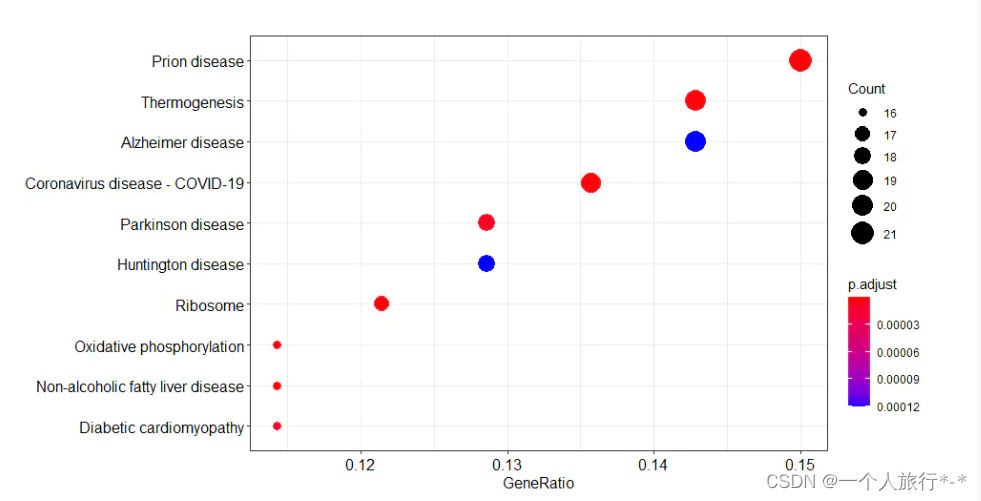
barplot
barplot(ekk)

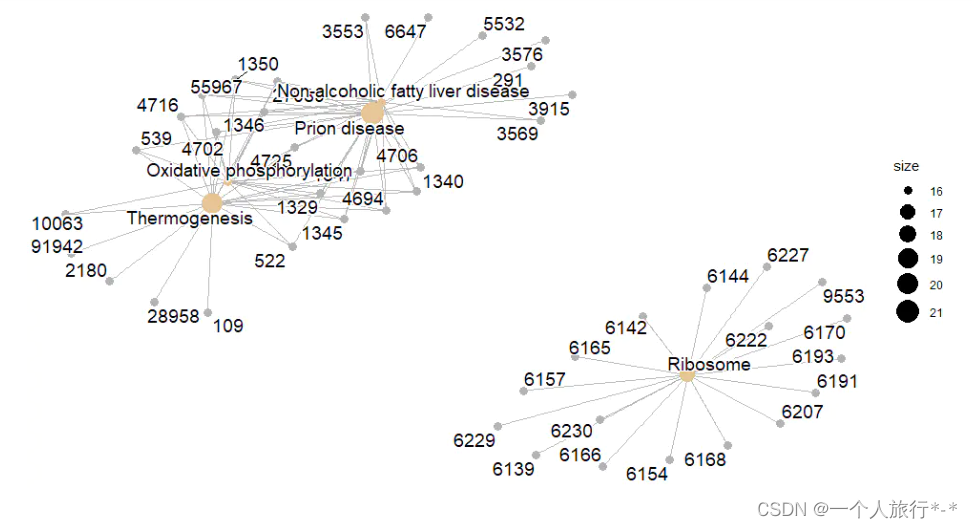
cnetplot
#对于基因和富集的pathways之间的对应关系进行展示,如果一个基因位于一个pathway下,则将该基因与pathway连线
cnetplot(ekk, categorySize="pvalue", showCategory = 5)
emapplot
###upsetplot
upsetplot(ekk)
查看富集通路
#BiocManager::install("pathview")
BiocManager::install("pathview")
library(pathview)
#Downloading xml/png files for hsa00190 会比较慢
pv.out <- pathview(gene.data = deg$ENTREZID,#需要提供的基因向量,默认是Entrez_ID。可以由gene.idtype设置
pathway.id = 'hsa00190', #在KEGG中的ID
species ="hsa",
#out.suffix = "gse57691",#文件输出名称,默认是pathview
kegg.native =TRUE#默认是TRUE输出完整pathway的png格式文件,反之输出pdf文件
)
#在pathway通路图上标记富集到的基因
browseKEGG(ekk, "hsa00190")
#https://www.kegg.jp/kegg-bin/show_pathway?hsa00190/27089/55967/522/4706/4716/1345/4702/539/4694/1346/1350/1329/4725/1347/10063/1340
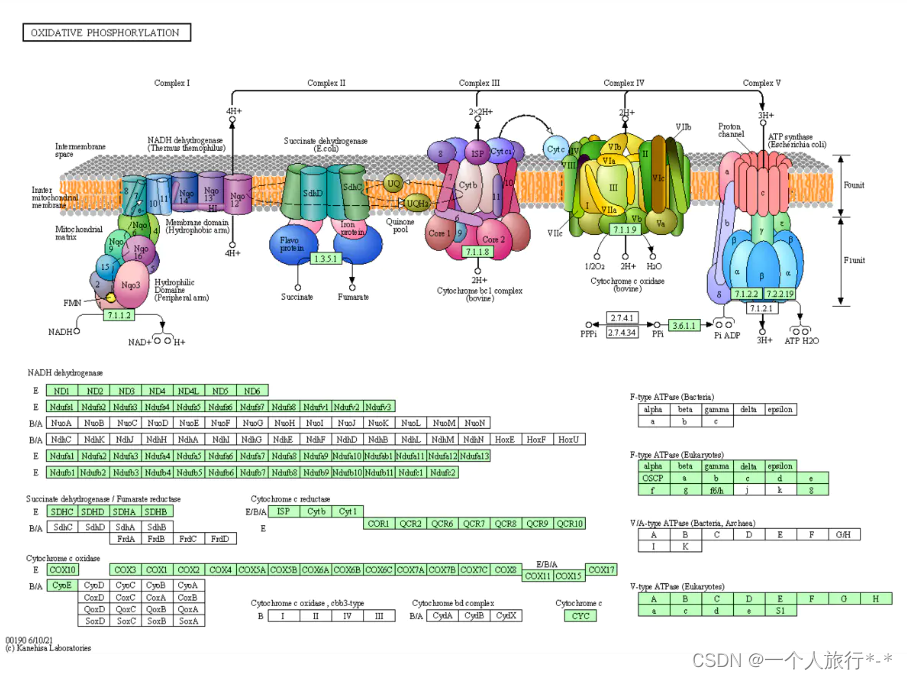

实例
g2<-c("K06585","K00799","K06483","K01016","K00901")
x=enrichKEGG(g2,organism = "ko",minGSSize = 1,pvalueCutoff = 1,qvalueCutoff = 1)
head(x,2)
x@result
dotplot(x,showCategory=10)
barplot(x)
#对于基因和富集的pathways之间的对应关系进行展示,如果一个基因位于一个pathway下,则将该基因与pathway连线
cnetplot(x, categorySize="pvalue", showCategory = 5)
###upsetplot
library(enrichplot)
library(ggupset)
upsetplot(x)