Pre-trained ViT 整理
由于第一次投顶会没有经验,导致选择了一个较大的backbone,整个实验的时间拖的非常长~~~
最近深感选好baseline的重要性,所以看了一些预训练的VIT整理在这里,希望下一篇工作能够对此作出调整。
Deit
Title: Training data-efficient image transformers & distillation through attention
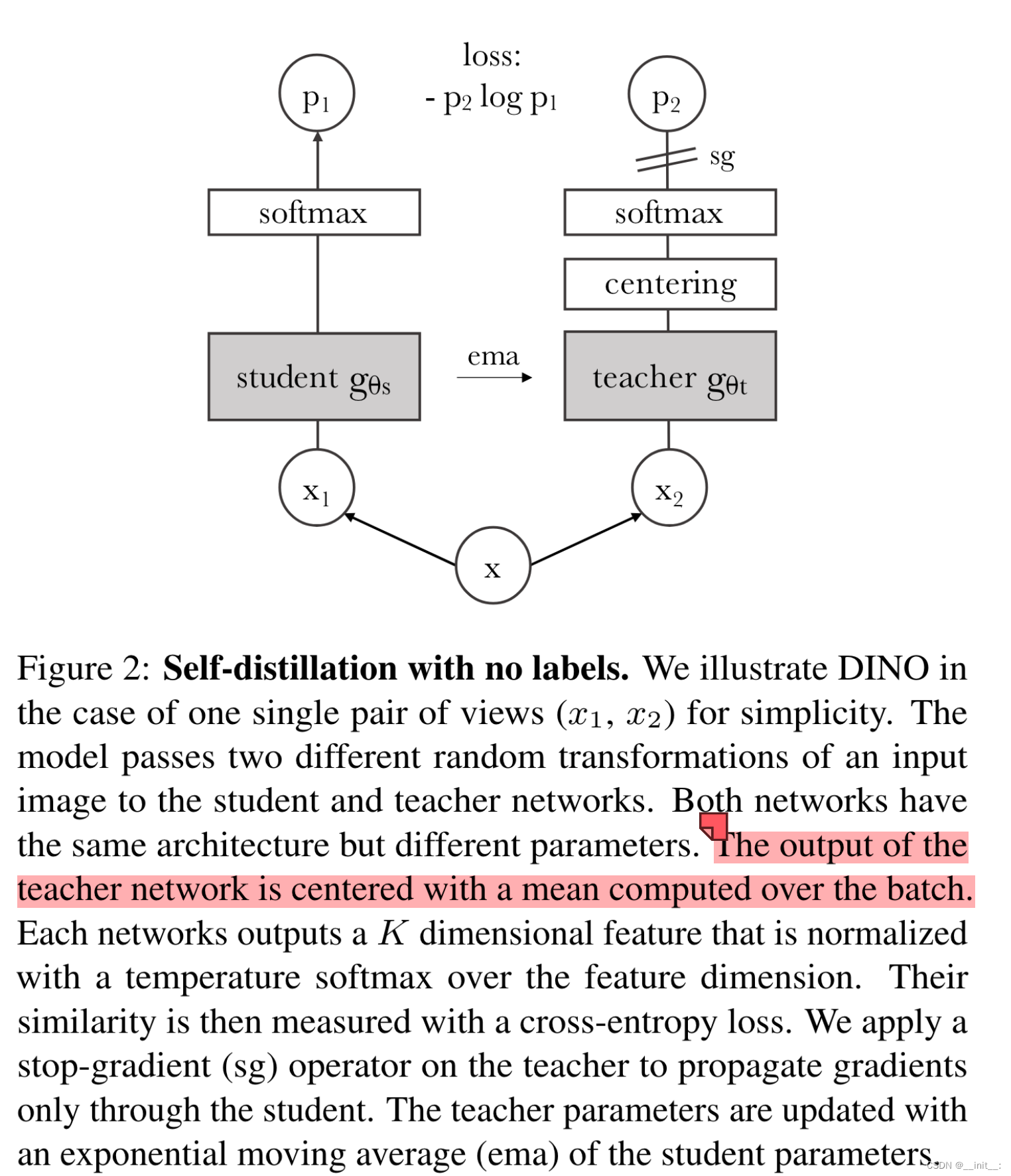
Deit 采用蒸馏学习的方式,将教师网络中的信息进行蒸馏压缩。模型引入了一个额外的dist token(包含对应的position embedding)用于收集蒸馏信息,除此之外没有对结构进行改动。另外,输出结果由原本的class token变为两个token的平均。
DINO(self-distillation with no labels)
Emerging Properties in Self-Supervised Vision Transformers
一篇有意思的自训练方法,名称让人联想到了Chrome里的小恐龙dino。
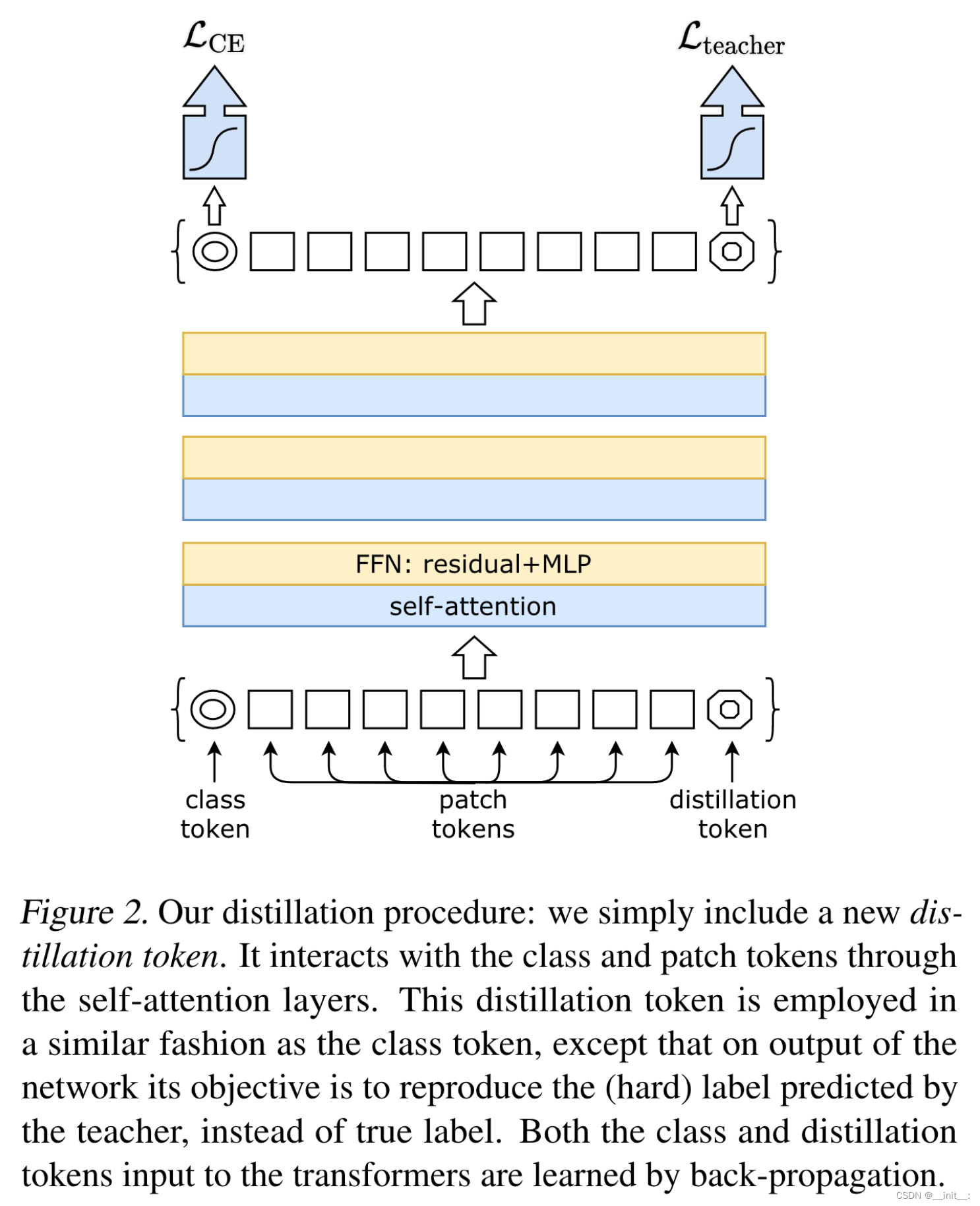
作者发现经过自蒸馏训练的ViT包含有一定的图像语义信息,这在监督训练的ViT中是几乎没有的。另外,通过自训练ViT-small得到的特征,仅仅使用简单的k-NN分类就能取得可观的效果。同时,作者给出了一个有意思的实验结论,采用更小的patch块,能够更好的提升网络性能。
整个方法也十分简洁,学生网络与教师网络初始参数相同,在训练时学生网络自然更新,教师网络根据学生网络参数的EMA进行更新。损失函数为计算两者之间的交叉熵。
值得注意的地方有两点,首先是网络的输入,学生网络的输入为多个较小分辨率的局部图像,而教师网络输入两个不同view的全局图像。优化交叉熵的过程,其实是在优化网络学习local-global的对应能力。
另一点在于,网络的输出不是直接得到的结果,而是center-sharpness的,目的是为了防止模型崩溃。
具体来说,center操作其实可以看作对网络输出添加一定的bias:
g t ( x ) ← g t ( x ) + c g_t(x) \leftarrow g_t(x) + c gt(x)←gt(x)+c
其中,c通过EMA的方式更新:
c ← m c + ( 1 − m ) 1 B ∑ i = 1 B g θ t ( x i ) c \leftarrow mc + (1-m)\frac{1}{B} \sum^{B}_{i=1} {g_{\theta_t}(x_i)} c←mc+(1−m)B1i=1∑Bgθt(xi)
sharpness即计算softmax时,温度系数设置小一点。
BEiT
BEIT: BERT PRE-TRAINING OF IMAGE TRANSFORMERS
这篇论文和ViT的写作动机有些像,都是从NLP的任务和方法获得启发,来适应到CV领域。类似于:
Transformer -> ViT
BERT -> BEiT
有意思的是,同样是作为CV预训练模型,也是从masked patch复原,与Kaiming的MAE十分相似。不同的地方在于,MAE直接重建masked patch并试图恢复原图,而BEiT试图预测masked token。
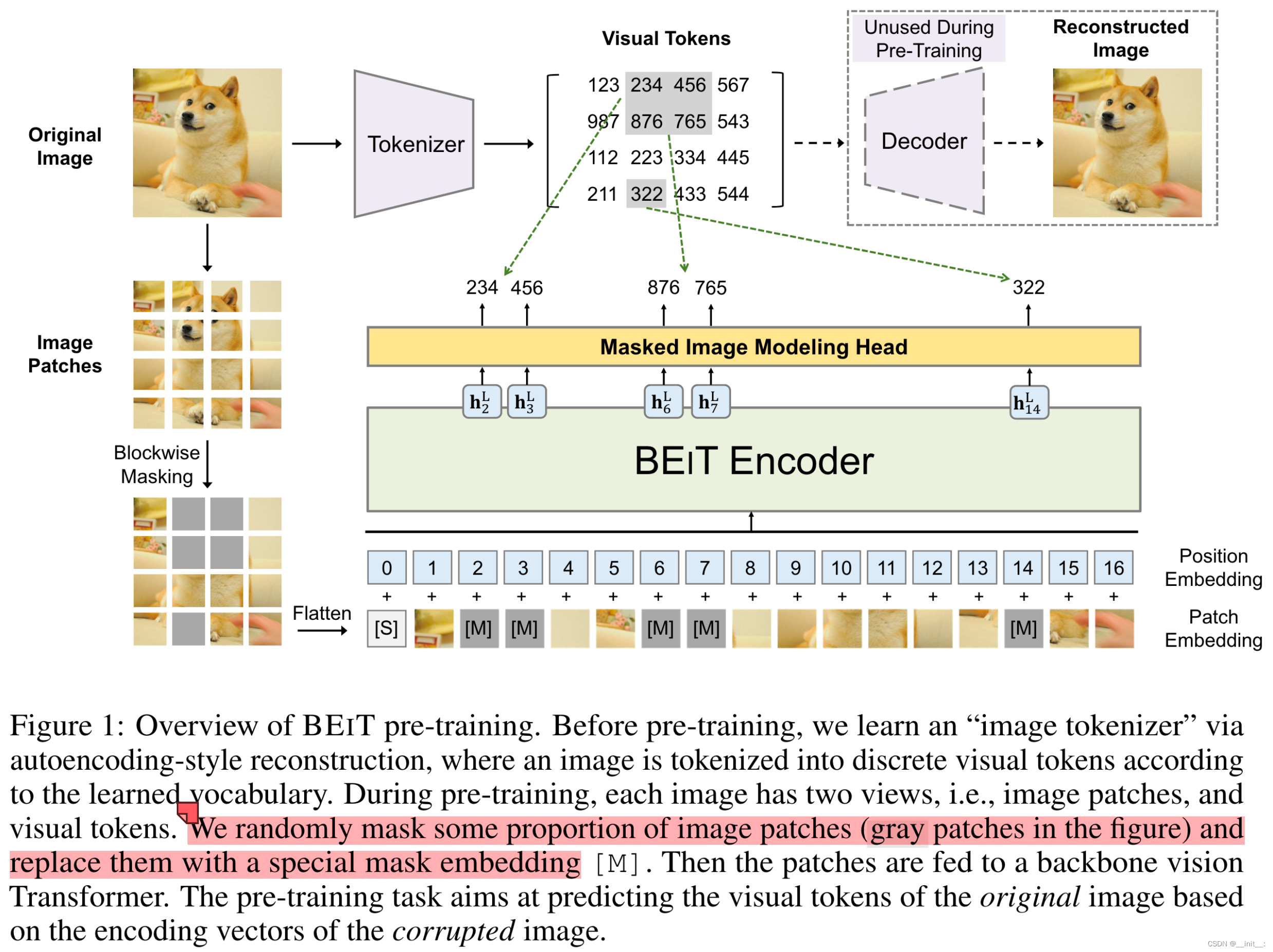
方法的整体结构并不复杂:
输入流分为两个部分:1.将图像通过image tokenizer得到Visual tokens;2.与ViT的处理方式类似,将图像处理为patch,不过这里添加了随机掩码遮盖部分patch后再输入transformer。整个训练过程的任务为masked image modeling(MIM),即通过网络学习预测mask区域的visual token这样一个pretext task来得到较好的视觉特征表示(可能是为了与BERT的设定类似,感觉在CV任务中没有MAE来的直接)。
需要注意的是,VIsual Tokenizer使用的是预训练好的模型,因此在训练BEiT时,只需要使用tokenizer部分得到visual token即可,不需要decode重建的过程。
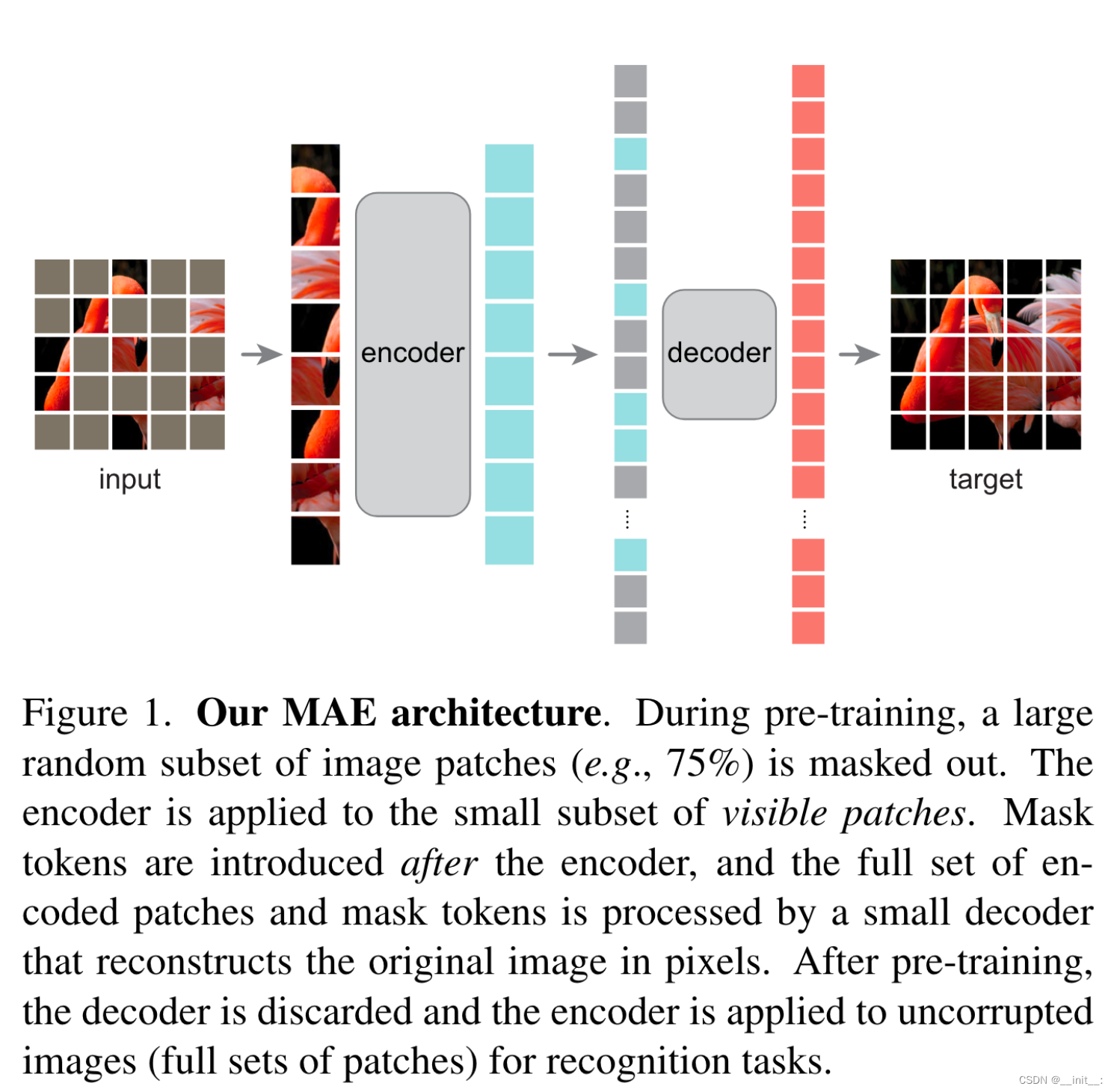
MAE
Masked Autoencoders Are Scalable Vision Learners
何恺明的论文读起来总是让人神清气爽。。。
与刚刚介绍的BEiT类似,MAE也是仿照BERT的“做填空”的训练方式。不同之处在于,MAE更加符合“填空题”这一形容:将输入的图像处理为patch并随机mask一部分之后,直接将剩余的patch输入进encoder,随后将masked patch token与得到的token全部输入进decoder来重建出原图。通过这种方式训练得到的encoder具有强大的表示能力,即使是整个mask比率达到95%依然能够取得很好的重建效果。