
一、逻辑(logistic)回归原理

1.1 逻辑回归的数学原理

1.2 logistic回归的L2正则化原问题

1.3 逻辑回归的L2正则化原问题使用可信域牛顿法求解


1.4 logistic 回归L2正则化的对偶问题
1.4.1 logistic回归的拉格朗日对偶问题和利用KKT条件求解

1.4.2 逻辑回归L2正则化Fenchel对偶问题

二、示例代码1-实现逻辑回归的L2正则化,并用信赖域牛顿法求解最优参数
2.1 对数据集:测试1分数,测试2分数,是否被录取。进行逻辑回归分类。

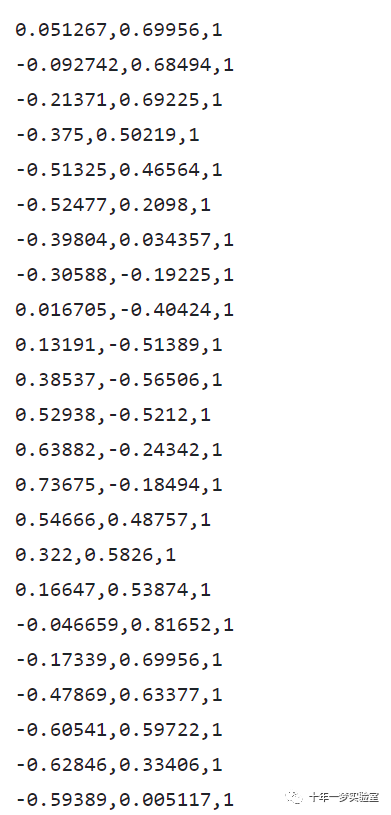
数据集:118行,3列:测试1分数,测试2分数,是否被录取
# 导入 numpy, pandas 和 matplotlib 库,分别用于进行数值计算,处理数据和绘制图形
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#%matplotlib inline # 这一行是在 Jupyter Notebook 中使用的,表示将图形显示在当前的单元格中
# 获取当前的工作目录,并拼接上数据文件的相对路径
import os
path =r'ipython-notebooks-master/data/ex2data2.txt'
# 读取数据文件,它是一个 csv 文件,包含了 118 个样本,每个样本有 3 个属性,分别是两个测试的分数和是否被录取
data2 = pd.read_csv(path, header=None, names=['Test 1', 'Test 2', 'Accepted'])
# 显示数据的前 5 行,查看数据的格式和内容
data2.head()
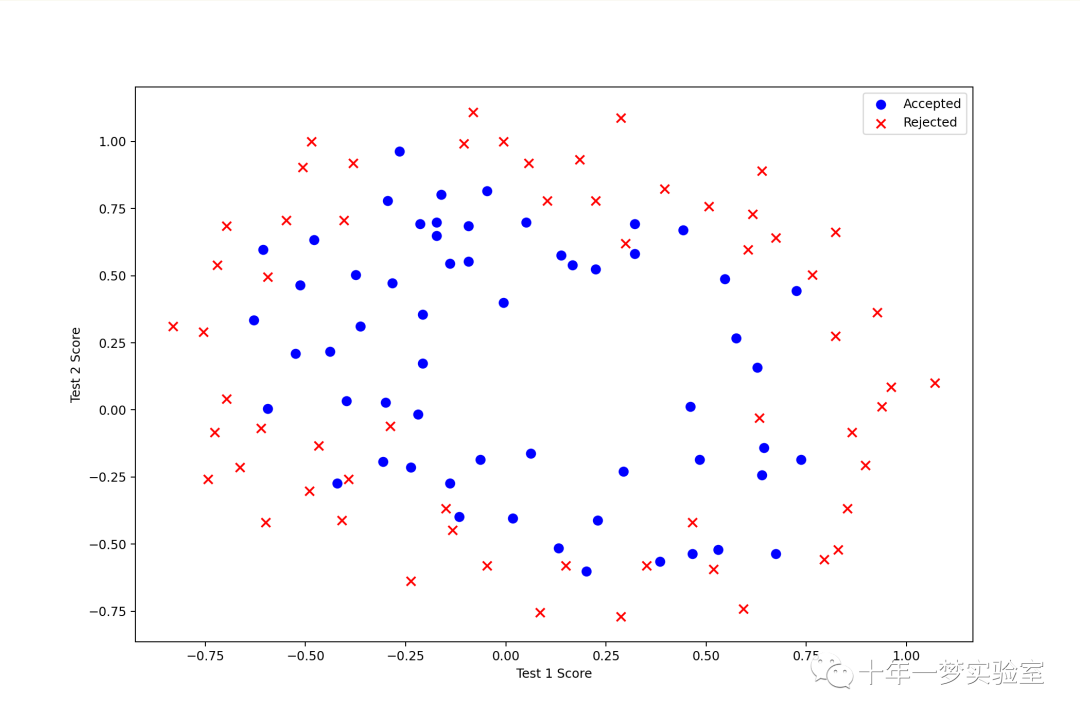
# 根据是否被录取,将数据分为正类和负类
positive = data2[data2['Accepted'].isin([1])] # positive 是一个 DataFrame,包含了所有被录取的样本
negative = data2[data2['Accepted'].isin([0])] # negative 是一个 DataFrame,包含了所有未被录取的样本
# 创建一个图形对象,设置大小为 12 x 8
fig, ax = plt.subplots(figsize=(12,8))
# 使用 scatter 函数绘制散点图,分别显示正类和负类的样本的分布,使用不同的颜色和形状来区分
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted') # s 表示点的大小,c 表示颜色,marker 表示形状,label 表示图例
ax.scatter(negative['Test 1'], negative['Test 2'], s=50, c='r', marker='x', label='Rejected')
# 显示图例
ax.legend()
# 设置 x 轴和 y 轴的标签
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
plt.show()
# 定义 sigmoid 函数,它是逻辑回归的激活函数,将任意实数映射到 0 到 1 之间的概率值
def sigmoid(z):
return 1 / (1 + np.exp(-z)) # 使用 numpy 的 exp 函数来计算 e 的幂
# 设置多项式的最高次数为 5
degree = 5
# 获取数据的第一列和第二列,分别表示两个测试的分数
x1 = data2['Test 1']
x2 = data2['Test 2']
# 在数据中插入一列全为 1 的值,表示截距项 1*theta0+theta1*x1+theta2*x2+...+theta11*x11
data2.insert(3, 'Ones', 1)
# 使用循环来生成多项式特征,例如 x1^2, x1*x2, x2^2 等,将它们添加到数据中,并命名为 Fij,其中 i 和 j 分别表示 x1 和 x2 的次数
for i in range(1, degree): #二元五次多项式
for j in range(0, i):
data2['F' + str(i) + str(j)] = np.power(x1, i-j) * np.power(x2, j) # 使用 numpy 的 power 函数来计算幂
# 删除数据中的第一列和第二列,因为它们已经被多项式特征替代
data2.drop('Test 1', axis=1, inplace=True)
data2.drop('Test 2', axis=1, inplace=True)
# 显示数据的前 5 行,查看多项式特征的生成结果
# data2.head()
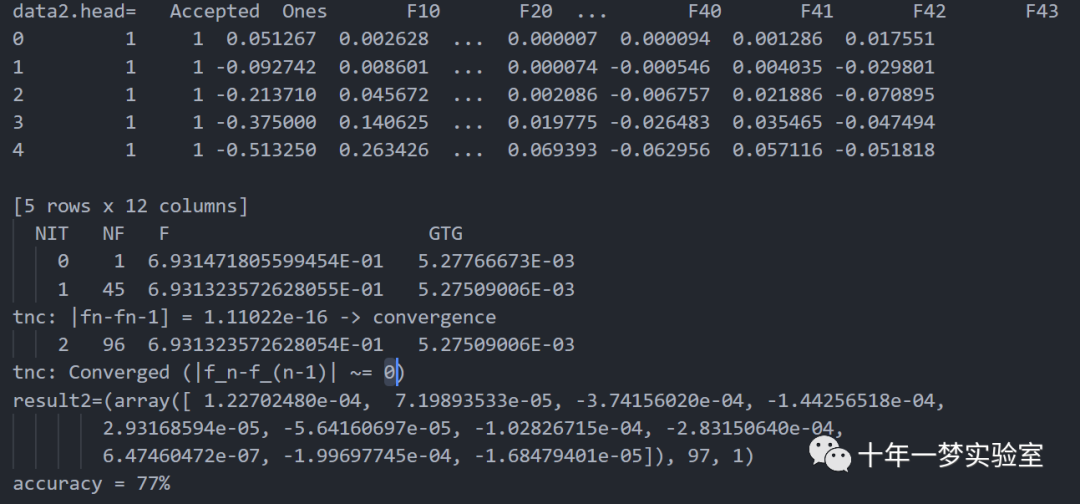
print('data2.head={0}'.format(data2.head()))
# 定义正则化的代价函数,它用于评估逻辑回归模型的拟合程度,同时考虑了模型的复杂度
def costReg(theta, X, y, learningRate):
# 将参数向量,特征矩阵和类别向量转换为 numpy 的矩阵对象,方便进行矩阵运算
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
# 计算第一部分,表示模型预测的概率与真实类别的对数似然
first = np.multiply(-y, np.log(sigmoid(X * theta.T))) # 使用 numpy 的 multiply 函数来进行元素级的乘法
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
# 计算第二部分,表示正则化项,用于惩罚过大的参数,避免过拟合
reg = (learningRate / 2 * len(X)) * np.sum(np.power(theta[:,1:theta.shape[1]], 2)) # 注意从第二个参数开始,不惩罚截距项
# 返回代价函数的值,是一个标量
return np.sum(first - second) / (len(X)) + reg
# 定义正则化的梯度函数,它用于计算代价函数的偏导数,用于更新参数
def gradientReg(theta, X, y, learningRate):
# 将参数向量,特征矩阵和类别向量转换为 numpy 的矩阵对象,方便进行矩阵运算
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
# 获取参数的个数,并创建一个全为 0 的向量,用于存储梯度值
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
# 计算模型预测的概率与真实类别之间的误差
error = sigmoid(X * theta.T) - y
# 使用循环来计算每个参数的梯度值
for i in range(parameters):
# 计算第 i 个参数的梯度值,是误差和第 i 列特征的乘积的均值
term = np.multiply(error, X[:,i])
# 如果是第 0 个参数,即截距项,不加正则化项
if (i == 0):
grad[i] = np.sum(term) / len(X)
# 否则,加上正则化项,即参数本身乘以正则化参数
else:
grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[0,i])
#grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:,i])
#grad[i] = (np.take(np.sum(term), 0) / len(X)) + ((learningRate / len(X)) * np.take(theta[:,i], 0)) # 使用 np.take 函数来获取第 0 个元素
# 返回梯度向量
return grad
# 设置 X 和 y,注意我们已经将类别标签移动到了第 0 列
cols = data2.shape[1]
X2 = data2.iloc[:,1:cols] # X2 是一个 118 x 11 的矩阵,表示多项式特征矩阵
y2 = data2.iloc[:,0:1] # y2 是一个 118 x 1 的向量,表示类别向量
# 将 X2 和 y2 转换为 numpy 的数组,并初始化参数向量 theta2,全为 0
X2 = np.array(X2.values)
y2 = np.array(y2.values)
theta2 = np.zeros(11)
# 设置正则化参数为 1 λ
learningRate = 1
# 计算初始的代价函数值
#costReg(theta2, X2, y2, learningRate)
# 计算初始的梯度值
#gradientReg(theta2, X2, y2, learningRate)
# 使用 scipy 库中的 fmin_tnc 函数来进行优化,找到最小化代价函数的参数值
import scipy.optimize as opt
result2 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate))
# 打印优化结果,包括最优的参数值,代价函数的最小值,迭代次数等
#result2
print('result2={0}'.format(result2))
# 定义预测函数,它用于根据给定的参数和特征,预测样本的类别,如果概率大于等于 0.5,就预测为 1,否则预测为 0
def predict(theta, X):
probability = sigmoid(X * theta.T) # 计算样本的概率值,是一个向量
return [1 if x >= 0.5 else 0 for x in probability] # 返回预测的类别,是一个列表
# 将优化结果中的最优参数转换为矩阵
theta_min = np.matrix(result2[0])
# 使用最优参数和多项式特征,对所有样本进行预测
predictions = predict(theta_min, X2)
# 比较预测的类别和真实的类别,如果一致,就记为正确,否则记为错误
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y2)]
# 计算正确的个数占总数的百分比,表示模型的准确率
accuracy = (sum(map(int, correct)) % len(correct))
# 打印准确率
print ('accuracy = {0}%'.format(accuracy))
result2 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate))

2.2 输出结果

三、示例代码2-使用sklearn 库 linear_model模块的 LogisticRegression对数据集进行对数概率回归分类
3.1 数据集是一个 csv 文件,包含了 400 个样本,每个样本有 5 个属性,分别是用户 ID,性别,年龄,预估收入和是否购买了产品。

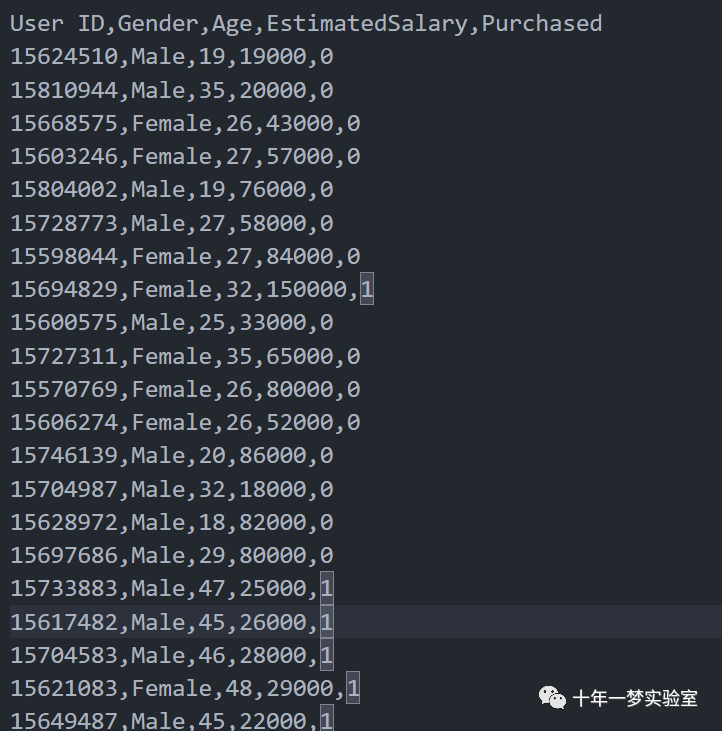
数据集 400个样本
# 导入 numpy, matplotlib 和 pandas 库,分别用于进行数值计算,绘制图形和处理数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 导入数据集,它是一个 csv 文件,包含了 400 个样本,每个样本有 5 个属性,分别是用户 ID,性别,年龄,预估收入和是否购买了产品
dataset = pd.read_csv('datasets/Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # X 是一个 400 x 2 的矩阵,表示特征矩阵,只选取了年龄和预估收入两个特征
y = dataset.iloc[:, 4].values # y 是一个 400 x 1 的向量,表示类别向量,表示是否购买了产品,取值为 0 或 1
# 将数据集划分为训练集和测试集,其中测试集占 25%,并设置随机种子为 0,以保证每次划分的结果一致
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 对特征进行标准化,也就是将每个特征的均值变为 0,方差变为 1。这样可以避免数据的量纲或范围对模型的影响。使用 StandardScaler 类来实现标准化,先对训练集进行拟合和转换,再对测试集进行转换
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 创建逻辑回归分类器,使用默认的参数
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train) # 使用训练集的特征和类别来拟合逻辑回归模型
# 对测试集进行预测,使用训练好的模型对测试集的特征进行预测,得到预测的类别
y_pred = classifier.predict(X_test)
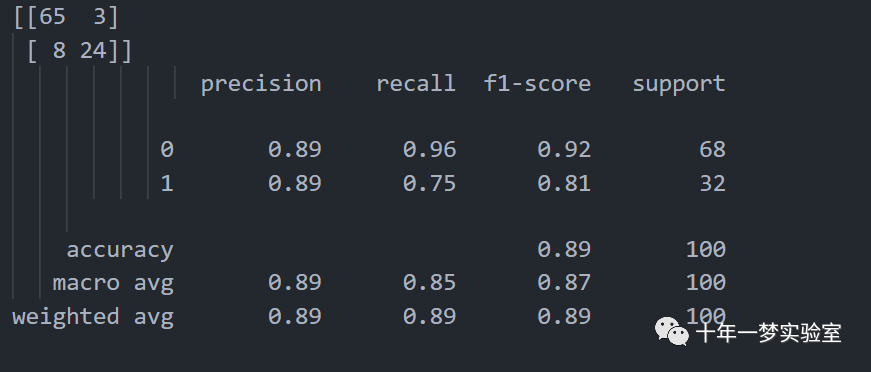
# 生成混淆矩阵和分类报告,使用 confusion_matrix 和 classification_report 函数来比较预测的类别和真实的类别,得到模型的准确率,召回率,精确度和 F1 值等指标
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
cm = confusion_matrix(y_test, y_pred) # cm 是一个 2 x 2 的矩阵,表示真阳性,假阳性,假阴性和真阴性的个数
print(cm) # 打印混淆矩阵
print(classification_report(y_test, y_pred)) # 打印分类报告
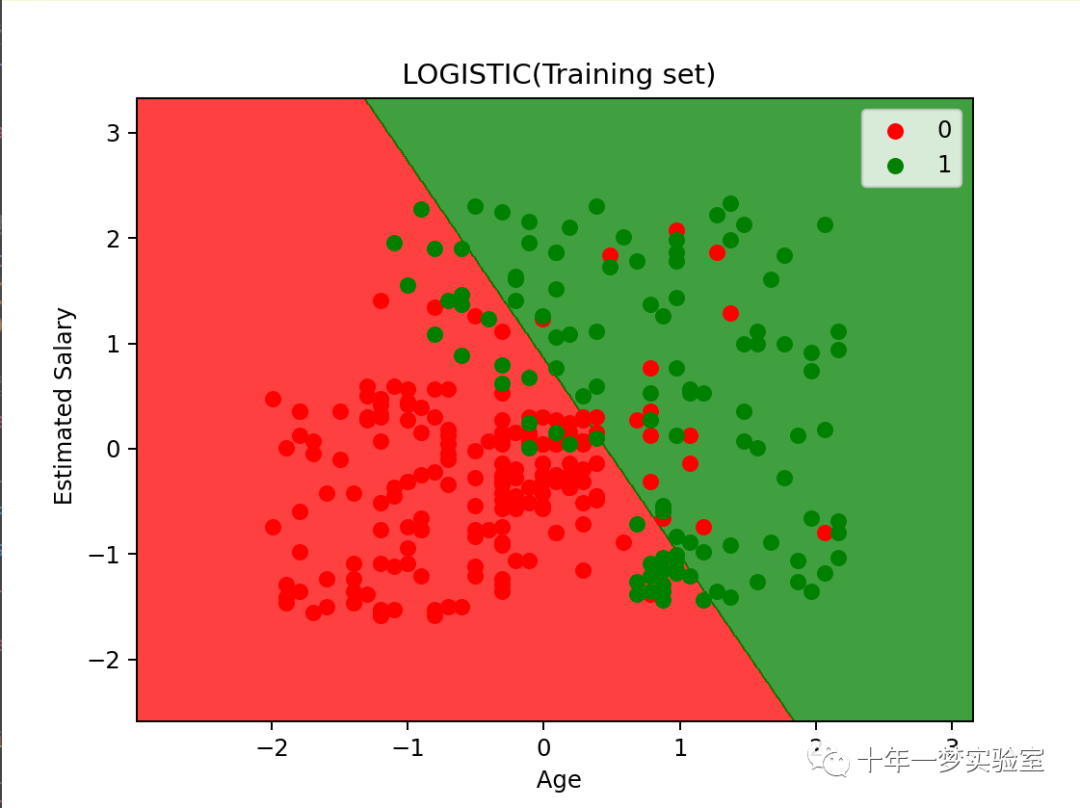
# 可视化训练集和测试集的结果,使用 matplotlib 库来绘制散点图和决策边界,展示不同类别的分布和模型的分类效果
from matplotlib.colors import ListedColormap
X_set,y_set=X_train,y_train # X_set 和 y_set 分别表示训练集的特征和类别
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01), # X1 和 X2 分别表示特征矩阵的第一列和第二列的网格点
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape), # 使用 contourf 函数绘制等高线,表示模型的决策边界
alpha = 0.75, cmap = ListedColormap(('red', 'green'))) # alpha 表示透明度,cmap 表示颜色映射
plt.xlim(X1.min(),X1.max()) # 设置 x 轴的范围
plt.ylim(X2.min(),X2.max()) # 设置 y 轴的范围
for i,j in enumerate(np. unique(y_set)): # 对于每个类别,绘制对应的散点图
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],c = np.array([ListedColormap(('red', 'green'))(i)]), label=j)# 选择该类别的样本的特征值 # 选择该类别的颜色和标签
plt. title(' LOGISTIC(Training set)') # 设置图的标题
plt. xlabel(' Age') # 设置 x 轴的标签
plt. ylabel(' Estimated Salary') # 设置 y 轴的标签
plt. legend() # 显示图例
plt. show() # 显示图形
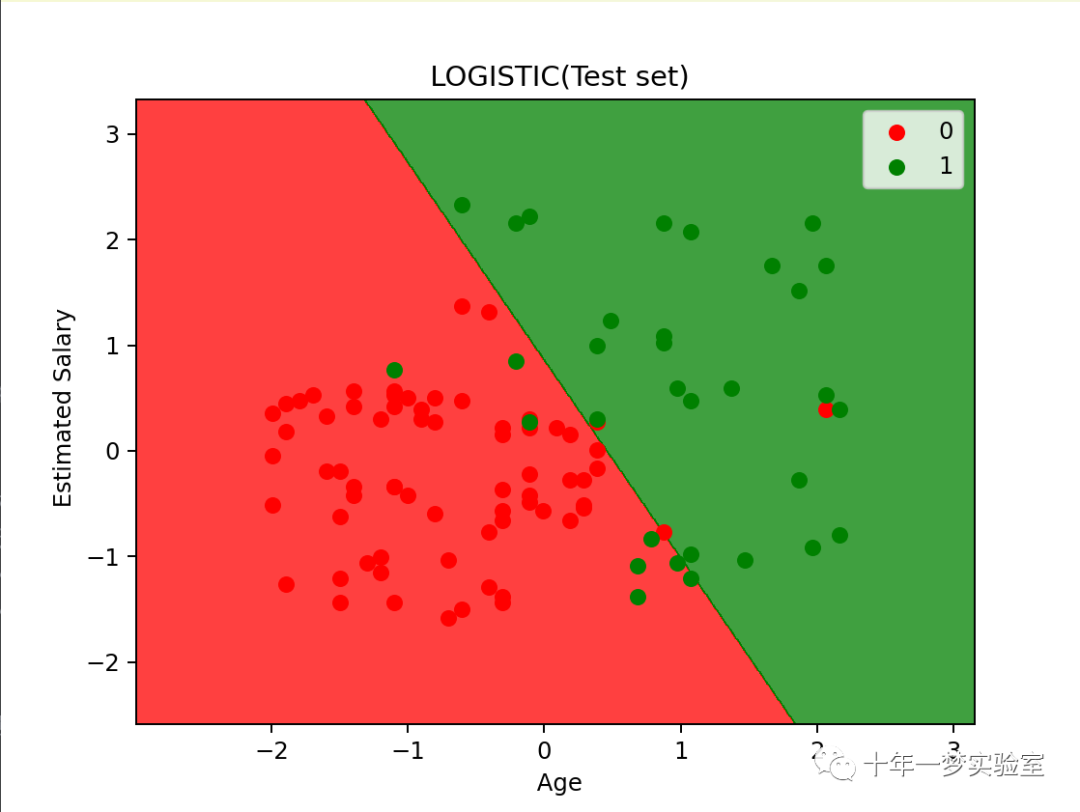
X_set,y_set=X_test,y_test # X_set 和 y_set 分别表示测试集的特征和类别
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01), # X1 和 X2 分别表示特征矩阵的第一列和第二列的网格点
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape), # 使用 contourf 函数绘制等高线,表示模型的决策边界
alpha = 0.75, cmap = ListedColormap(('red', 'green'))) # alpha 表示透明度,cmap 表示颜色映射
plt.xlim(X1.min(),X1.max()) # 设置 x 轴的范围
plt.ylim(X2.min(),X2.max()) # 设置 y 轴的范围
for i,j in enumerate(np. unique(y_set)): # 对于每个类别,绘制对应的散点图
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],color=ListedColormap(('red', 'green'))(i), label=j) # 选择该类别的样本的特征值 # 选择该类别的颜色和标签
plt. title(' LOGISTIC(Test set)') # 设置图的标题
plt. xlabel(' Age') # 设置 x 轴的标签
plt. ylabel(' Estimated Salary') # 设置 y 轴的标签
plt. legend() # 显示图例
plt. show() # 显示图形
sklearn.linear_model.LogisticRegression 参数说明
3.2 输出结果

四、logistic 回归的应用场景
逻辑回归是一种广泛应用于机器学习中的分类算法。它的基本思想是通过建立一个逻辑回归模型,将输入特征与对应的概率进行映射,然后使用一个阈值将概率转化为分类结果。
逻辑回归的应用场景非常广泛,包括以下几个方面:
预测某件事情是否发生。例如,预测客户是否会购买某种产品、预测用户是否会点击某个广告、预测某人是否会患某种疾病。
对数据进行二元分类。例如,对病人的数据进行疾病诊断、对文本数据进行情感分析、对图像数据进行目标检测。
预测某种事件的概率。例如,预测一个网站的用户是否变成付费用户的概率、预测某个客户的贷款违约率。
逻辑回归的优点是模型清晰、输出有概率意义、参数可解释性强、实施简单、非常高效。因此,它在实际应用中得到了广泛的应用。


参考网址:
logistic回归及正则化 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/357819623
https://github.com/jdwittenauer/ipython-notebooks/blob/master/notebooks/ml/ML-Exercise2.ipynb
https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.fmin_tnc.html
https://zhuanlan.zhihu.com/p/626626630 逻辑回归示例代码iris数据集
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
https://www.geeksforgeeks.org/understanding-logistic-regression/ 机器学习中的逻辑回归
https://www.ibm.com/topics/logistic-regression
https://web.stanford.edu/~jurafsky/slp3/5.pdf
The End